AWS 람다(Lambda)에서 AWS S3 서비스 이용하기
※ AWS S3에 접근하기 ※
실습을 위하여 하나의 AWS Lambda 함수를 생성해 봅시다.
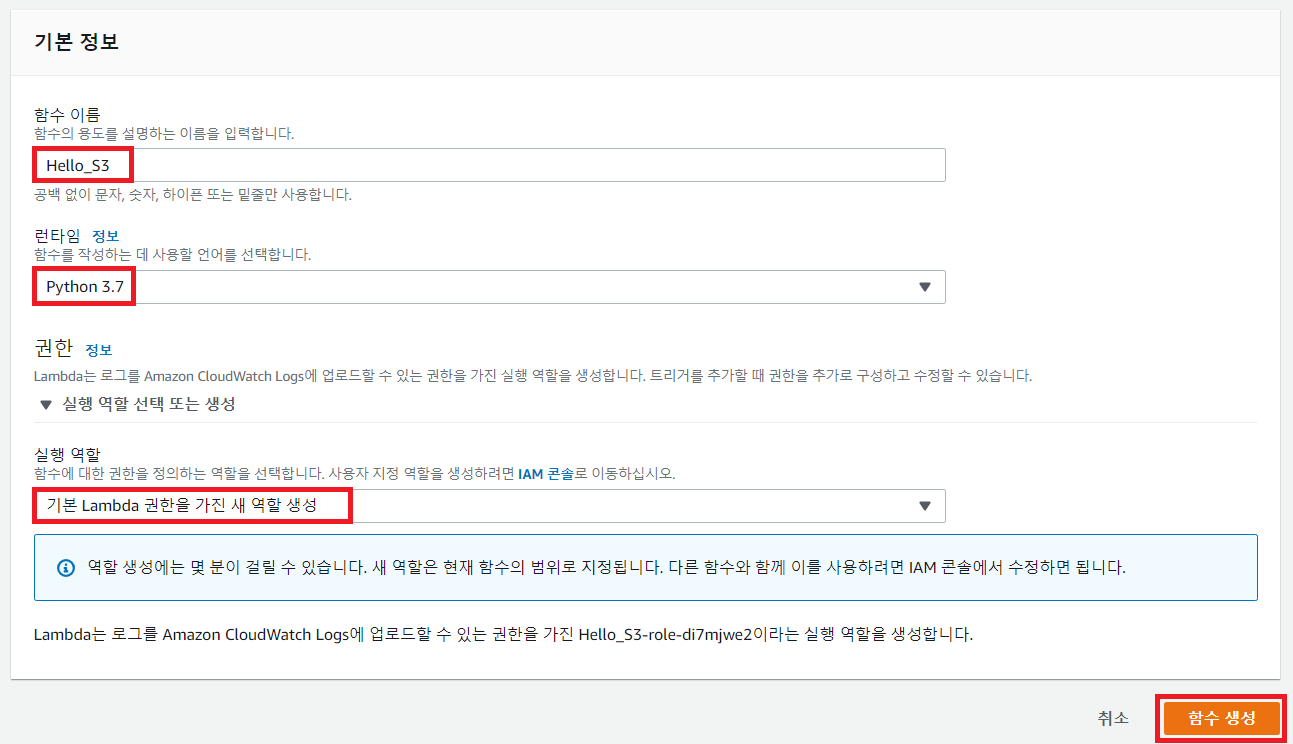
AWS Lambda는 기본적으로 Boto3와 같은 라이브러리를 내장하고 있습니다. 따라서 별도로 Boto3를 AWS Lambda에 업로드 하지 않아도 AWS의 다양한 기능을 이용할 수 있다는 장점이 있습니다. 바로 다음과 같이 현재 자신의 AWS 계정에 포함되어 있는 모든 S3 버킷(Bucket) 리스트를 출력하도록 할 수 있습니다.
import json
import boto3
import botocore
s3 = boto3.resource('s3')
def lambda_handler(event, context):
result_list = []
for bucket in s3.buckets.all():
result_list.append(bucket.name)
return {
'statusCode': 200,
'body': json.dumps(result_list)
}
이후에 트리거를 붙여서 실행 결과를 확인할 수 있습니다.
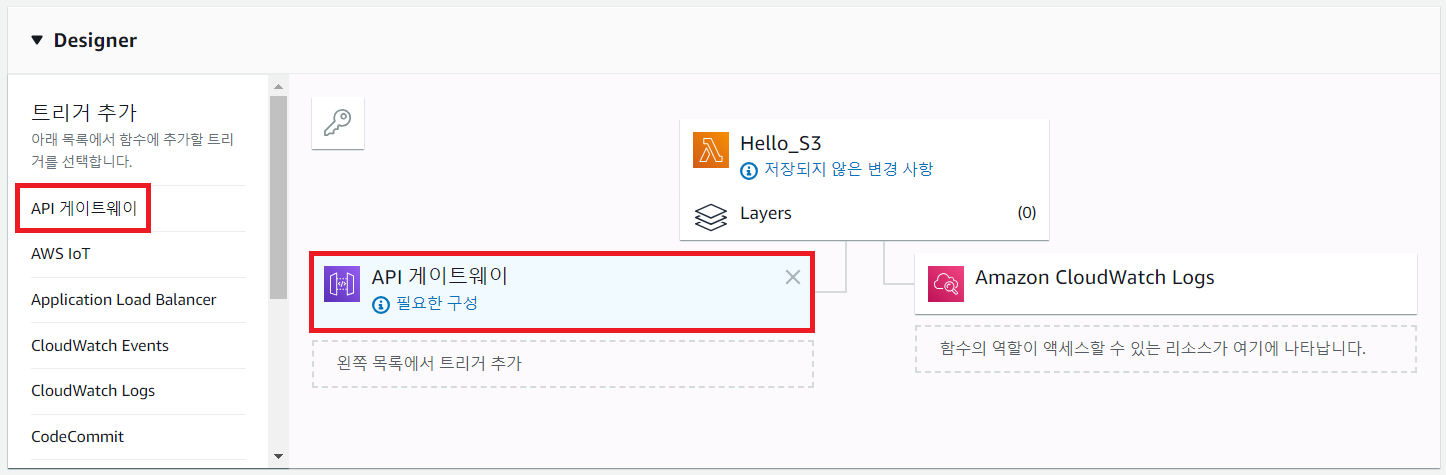
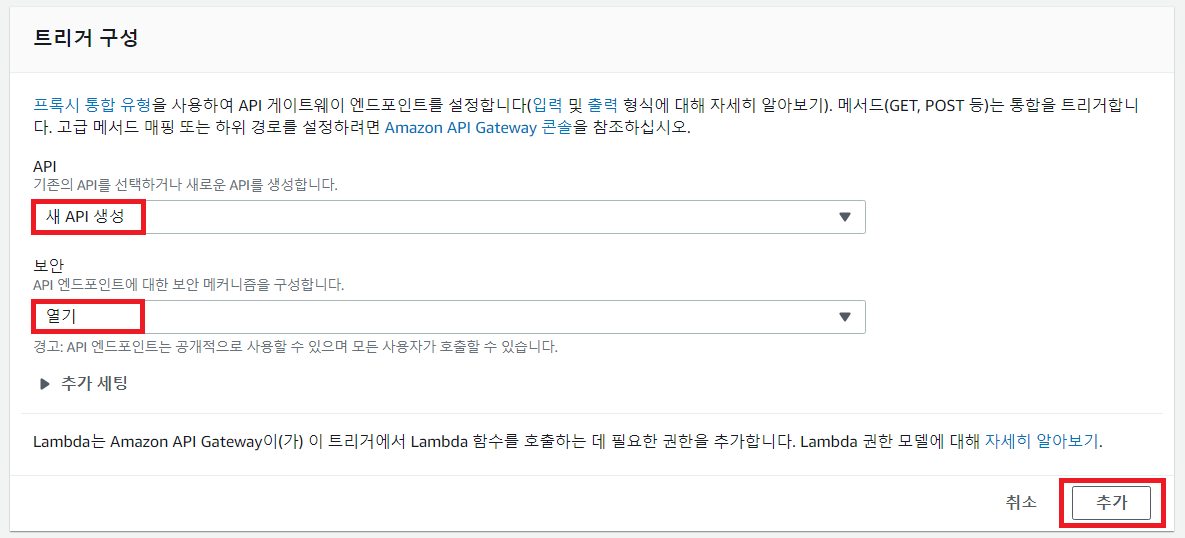
트리거를 구성한 이후에 [저장]하면 됩니다.
다만, 지금 바로 실행하면 S3에 접근할 수 없어서 오류가 발생할 수 있습니다. AWS Lambda가 S3에 접근할 수 있는 권한이 있는지 확인해야 합니다. 따라서 [실행 역할]에서 IAM 계정 정보를 확인합니다.
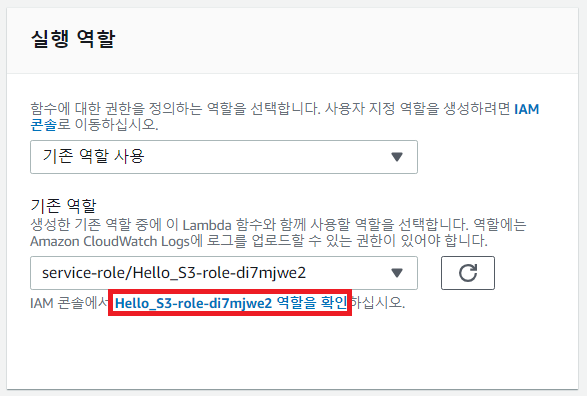
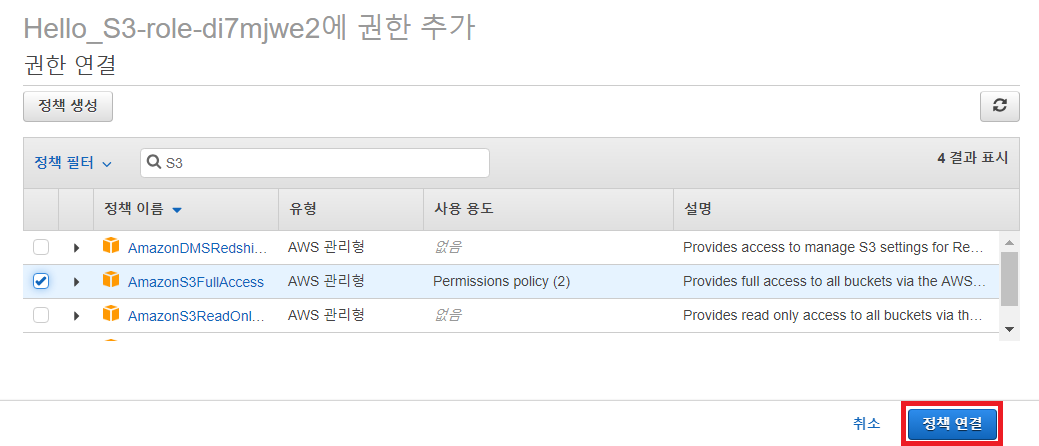
이후에 새로운 정책으로 AmazonS3FullAccess를 추가합니다.
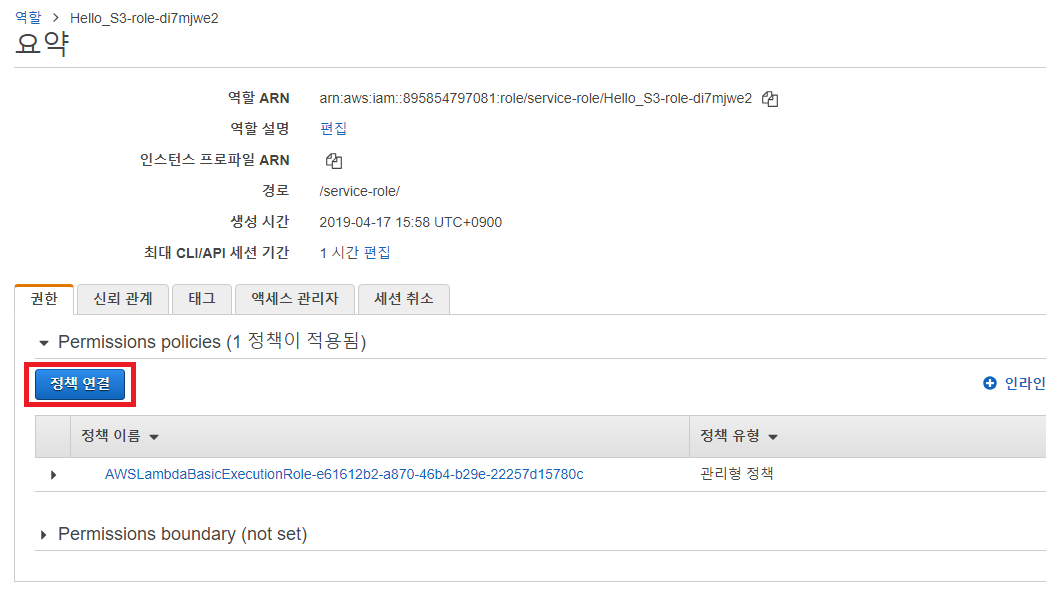
권한을 추가하면 됩니다.
이후에 API 게이트웨이의 URL에 접속하여 결과를 확인할 수 있습니다.
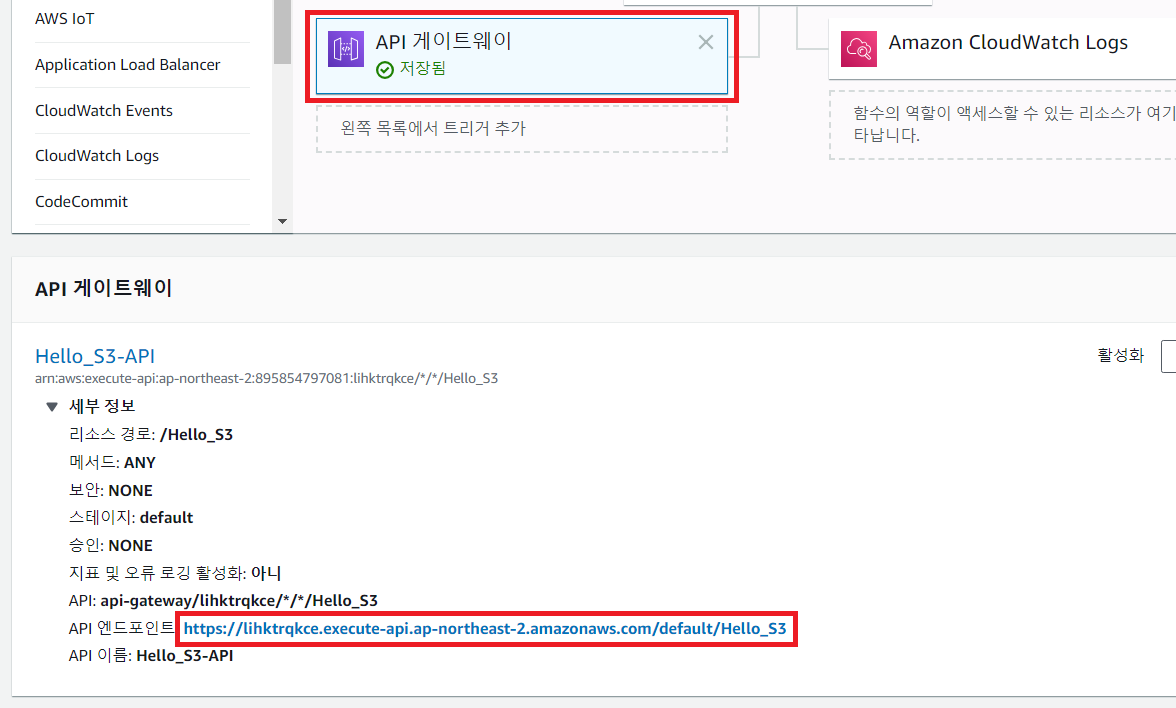
결과는 다음과 같습니다.
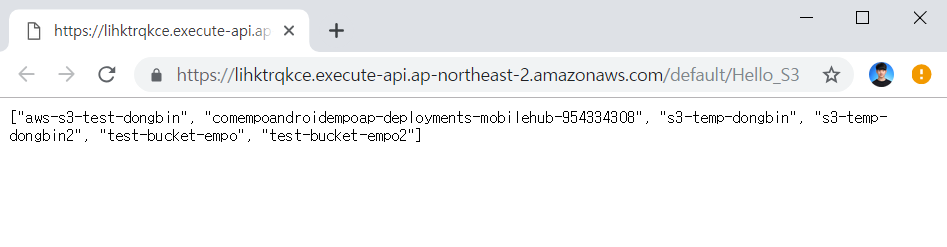
※ AWS S3 버킷(Bucket)에서 파일 읽기 ※
실습을 위해 퍼블릭(Public)한 상태의 AWS S3 버킷이 필요합니다.
참고 사이트: https://ndb796.tistory.com/280
따라서 하나의 AWS S3 버킷에 파일을 업로드 해봅시다.
저는 다음과 같이 텍스트 파일을 하나 업로드 해보았습니다.
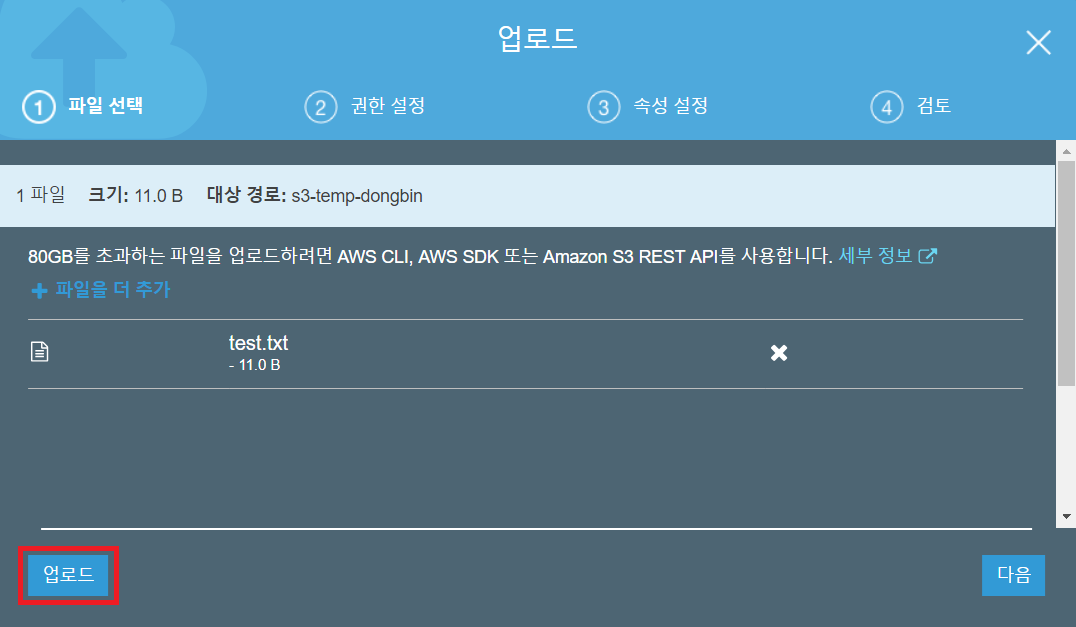
이제 다음과 같이 소스코드를 작성합니다. 버킷(Bucket) 이름과, 파일 객체(Key) 이름을 각각 이용하면 됩니다. 저는 다음과 같이 get_object() 함수를 이용하여 파일의 내용을 출력하도록 만들었습니다. 다만 read() 함수를 이용해서 파일을 읽으면, 읽은 데이터가 바이트(Byte) 형태로 기록됩니다. 따라서 이를 UTF-8으로 디코드하여 출력하도록 했습니다.
import json
import boto3
import botocore
BUCKET_NAME = 's3-temp-dongbin'
KEY = 'test.txt'
s3_client = boto3.client('s3')
def lambda_handler(event, context):
data = s3_client.get_object(Bucket=BUCKET_NAME, Key=KEY)
content = data['Body'].read()
print(content)
return {
'statusCode': 200,
'body': json.dumps(content.decode('UTF-8'))
}
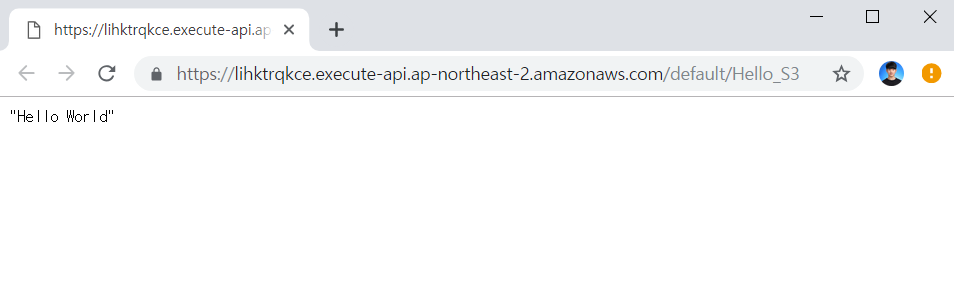
이제 실행 결과 다음과 같이 정상적으로 파일의 내용인 "Hello World"가 출력되었습니다.
'AWS' 카테고리의 다른 글
| AWS 문자 메시지(SMS) 발송 로그(Log) 관리하기 (0) | 2019.04.22 |
|---|---|
| AWS 서비스 한도 증가 요청하는 방법 (AWS 문자 메시지 한도 늘이기) (0) | 2019.04.22 |
| AWS SNS로 문자 메시지(SMS) 전송하기 (PHP 구현) (1) | 2019.04.16 |
| Python boto3을 이용하여 AWS S3과 연동하기 (1) | 2019.04.10 |
| AWS 람다(Lambda)로 Python 서버 API 구현하기 ② 나만의 API 만들기 (3) | 2019.04.10 |
