DeepFakes 소프트웨어: FaceSwap을 이용해 비디오에서 얼굴 추출하기(Extraction)
Face Swapping에서 추출(Extraction) 과정은 반드시 필요하다. FaceSwap에서 추출이란 '얼굴 잘라내기'라고 볼 수 있다. 다시 말해, 추출(Extraction) 자체는 단순히 비디오(Video)나 이미지 파일들이 들어있는 폴더로부터 얼굴이 있는 부분을 찾아서, 얼굴 사진들만 따로 모아놓는 일련의 과정을 의미한다. 당연히 얼굴(Face)에 있는 Identity 정보를 파악해서 Swapping을 해야 되는 것이므로 얼굴 이미지만 따로 추출하는 과정은 일반적으로 필요하다. (사람이 직접 추출하지 않아도 되는 것만으로 고맙다...)
추출 과정은 다음의 세 가지 단계로 구성된다. 아래 단계들에서 언급되고 있는 메소드들은 사실 Facial Manipulation 분야에서 굉장히 흔하게 사용되는 메소드들이다.
1) 얼굴 감지(Facial Detection): 동영상의 매 프레임마다 얼굴이 존재하는 위치를 찾는다.
2) 정렬(Alignment): 얼굴이 존재하는 위치를 찾은 뒤에는, 해당 얼굴에서 68개의 랜드마크(Landmarks)의 위치를 찾고 그에 상응하는 얼굴의 방향성을 결정한다.
3) 마스크 생성(Mask Generation): 어떤 부분이 얼굴이고, 어떤 부분이 배경인지를 잘 구분하기 위하여 얼굴 부분에 마스크를 씌운다.
FaceSwap의 학습 과정(Auto-Encoder 기반)에서는 얼굴 데이터가 필요하기 때문에, 이러한 추출 과정은 Face Swapping에서 매우 중요하다고 볼 수 있다.
또한 추출된(Extracted) 얼굴 정보들은 Alignment File 형태로 관리할 수 있다. Alignment File이란, 각 프레임에서의 얼굴에 대한 정보를 포함하고 있는 파일이다. 68개의 랜드마크를 이용하여 얼굴의 위치를 정확히 결정한다. 처음에는 조금 뜬금없게 느껴질 수 있는데, 일반적으로 Face Recognition 분야에서는 사람 얼굴에서 키 포인트들의 위치 정보를 처리하기 위해 68개의 랜드마크를 이용한다. 아무튼 이러한 Alignment File은 다음의 목적을 위해 사용된다.
1) 학습(Training): "Warp to Landmarks" 설정을 한 경우, 학습 과정에서 얼굴 랜드마크 정보를 제공하기 위해서
2) 변환(Converting): 원래 프레임에서 변환되어야 할 얼굴의 위치를 변환 과정(Convert Process)에게 알려주기 위해서
일단 간단히 Extraction을 해보자. FaceSwap을 실행하면 다음과 같은 화면을 만날 수 있다.
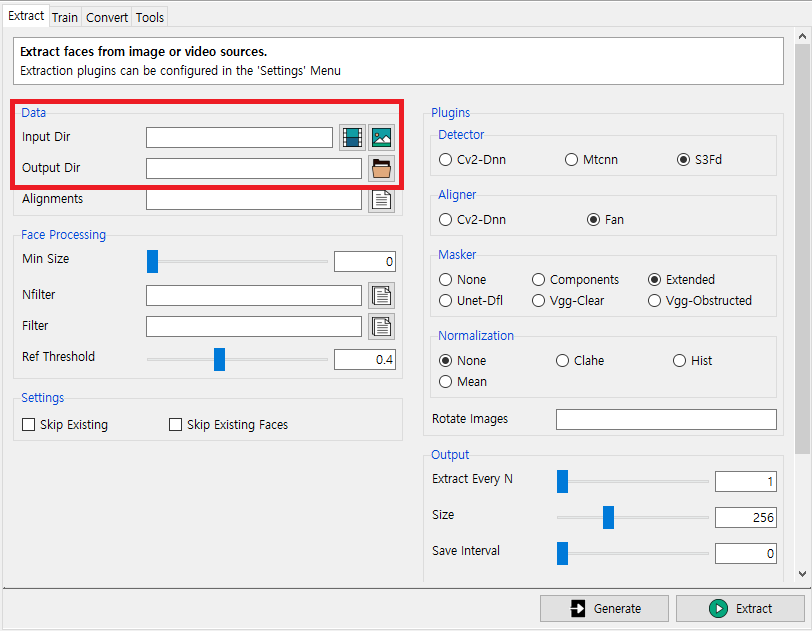
일단 가장 중요한 것은 입력(Input)과 출력(Output)이다.
Input Dir: 입력으로 사용할 비디오 혹은 이미지
Output Dir: 추출된 얼굴이 저장될 폴더
이어서 플러그인(Plugins)란에서는 어떤 라이브러리를 이용해서 얼굴을 Detection하고 Alignment할 것인지에 대한 내용을 설정할 수 있다. 자세한 내용은 FaceSwap 포럼(Forum)의 Extraction Guide 문서에서 살펴 볼 수 있다.
▶ FaceSwap Extraction Guide: https://forum.faceswap.dev/viewtopic.php?t=27
다음과 같이 입력으로 비디오 파일(.mp4)을 넣고 출력 폴더를 설정한 뒤에 [Extract] 버튼을 눌러 추출해보자. 저자는 입력과 출력을 설정한 것 이외에는 모두 기본 설정 그대로 진행하였다. [Generate] 버튼은 그냥 Python 커맨드(Command)를 얻기 위해 사용하는 버튼이고, [Extract]와 기능적으로 동일하다.
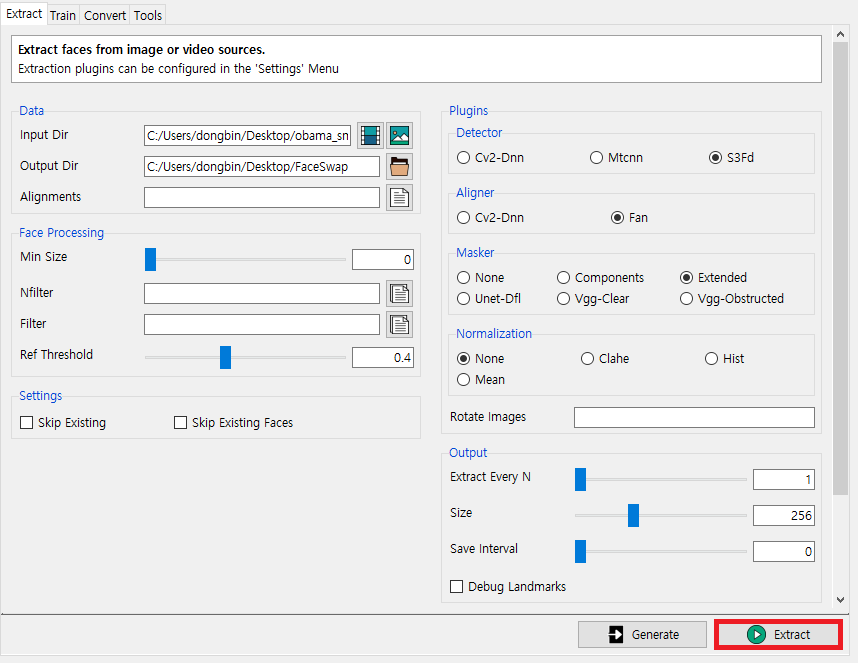
다만 [Extract] 버튼을 눌러도, 정상적으로 동작하지 않을 수 있다. 그럴 때는 컴퓨터를 재부팅한 뒤에 Conda Prompt를 실행해보거나, 재설치가 필요할 수 있다. 혹은 하드웨어(Hardware)적인 한계 때문일 수 있어서 RAM을 더 많이 끼우거나 더 높은 성능의 GPU 디바이스를 이용해야 할 수도 있다.
저자의 경우 자세한 추가적인 메시지 없이 단순히 with status: failed - extract.py. return code: 1라는 오류 메시지가 출력되어 혼란스러웠다. 그래서 Conda Prompt 대신에 바탕화면에 있는 FaceSwap 바로가기를 이용해서 FaceSwap을 실행해서 Extraction을 해보았는데, 그제서야 정상적으로 동작했다.
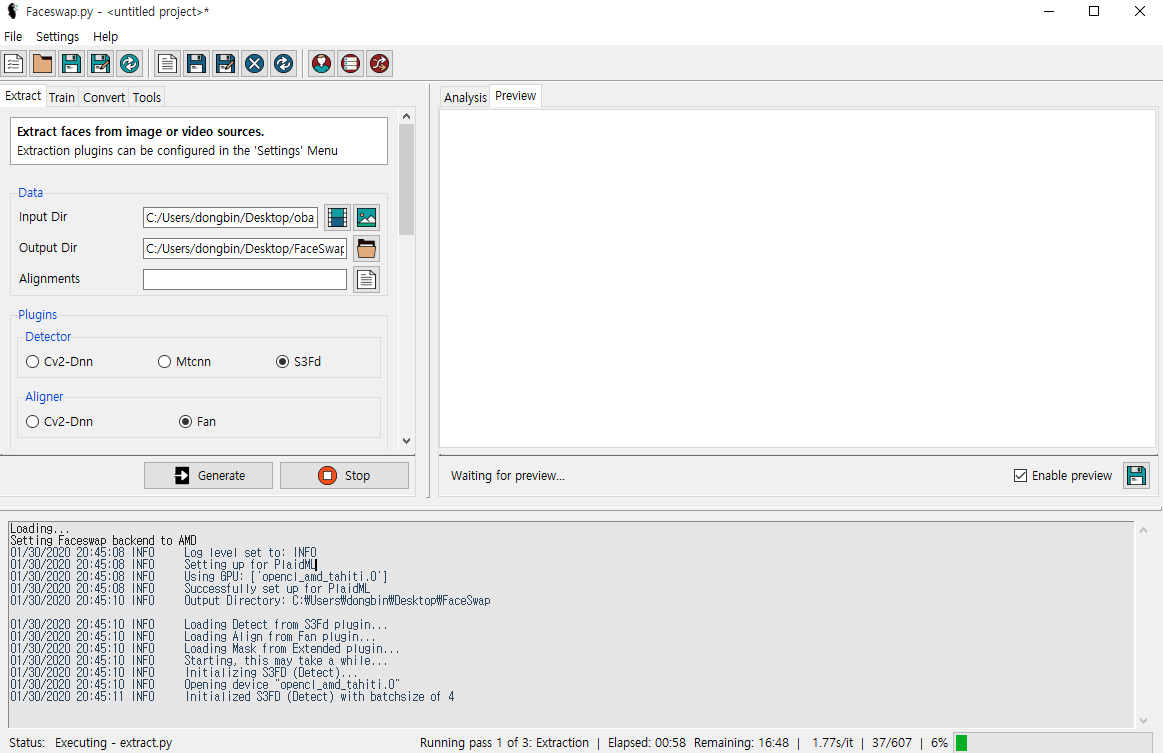
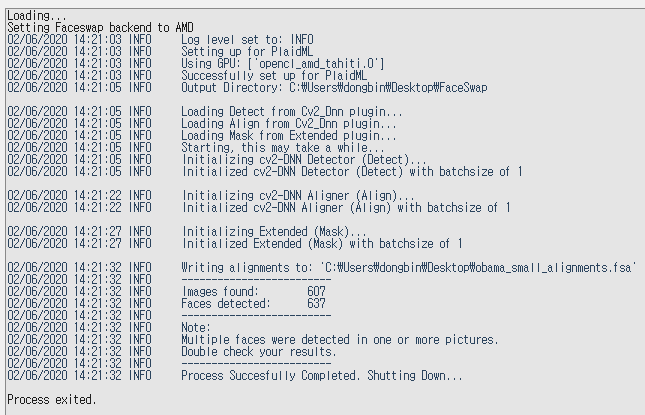
아무튼 정상적으로 Extraction이 수행될 때는 다음과 같은 화면이 나온다. (저자의 경우 20초 가량의 Obama 연설 동영상을 넣었는데, 총 600 프레임의 이미지에 대하여 정상적으로 Extraction이 수행되는 것을 알 수 있다. 저자의 컴퓨터 환경에서는 약 10분 가량이 소요될 정도로 느렸다. 저자의 경우 GPU 디바이스 호환 문제인지 모르겠지만, 이처럼 오랜 시간이 소요되었다.)
또한 저자의 경우 추가적으로 다음과 같이 plaidml.exceptions.Unknown: Unable to map memory: CL_MEM_OBJECT_ALLOCATION_FAILURE라는 메시지와 함께 오류가 발생했다.
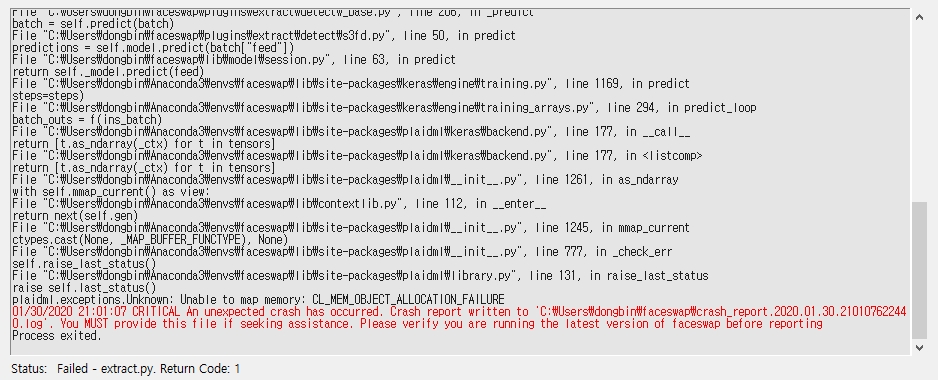
OpenCL 관련 오류 메시지가 나온 것으로 보아, 가지고 있는 AMD GPU와의 호환 문제인 것으로 보인다. 그래서 저자의 경우 그냥 Extraction 과정에서 CPU 기반의 플러그인을 사용하도록 하였다. 그래서 [Detector]에서 Cv2-Dnn을 선택하고, [Aligner]에서 Cv2-Dnn을 선택하였다. 저자의 경우 CPU 기반으로 Extraction을 했더니 매우 빠르게 동작했다. (600 Frames에 대하여 약 1분 가량 소요)
결과적으로 다음과 같이 성공적으로 추출이 진행되었다.
또한 추출(Extraction)을 마치고 나면 다음과 같이 폴더 안에 비정상적인 얼굴 이미지도 함께 포함되어 있다. 기본적으로 추출 과정에서 하나의 프레임 안에 여러 개의 얼굴이 감지(Detection)되는 경우 각각의 얼굴을 모두 추출해주기 때문이다. 따라서 다음과 같이 얼굴이 아닌데 얼굴로 감지되어 추출된 개체(Object)가 있는 경우 하나씩 선택하여 수동으로 삭제해주어야 한다.

이후에 저자는 오바마(Obama) 미국 전 대통령의 이미지를 더 추가하여 총 1,600개 가량의 Obama의 이미지를 준비하였다.
또한 기본적으로 FaceSwap 실습을 위해서는 두 개의 동영상이 필요하다. 따라서 하나의 동영상에 대해서 추가적으로 또 추출(Extraction)을 해준다. 참고로 두 개의 동영상에 대하여 서로 다른 폴더에 추출된 이미지가 저장되도록 해야 한다.
그래서 저자의 경우 부시(Bush) 미국 전 대통령의 스피치 영상 또한 준비하였다. 아까와 마찬가지로 추출 작업을 진행하였으며 대상의 얼굴이 아닌 다른 사람의 얼굴이거나, 사람의 얼굴이 아닌 경우 모두 선택하여 제거해주었다.
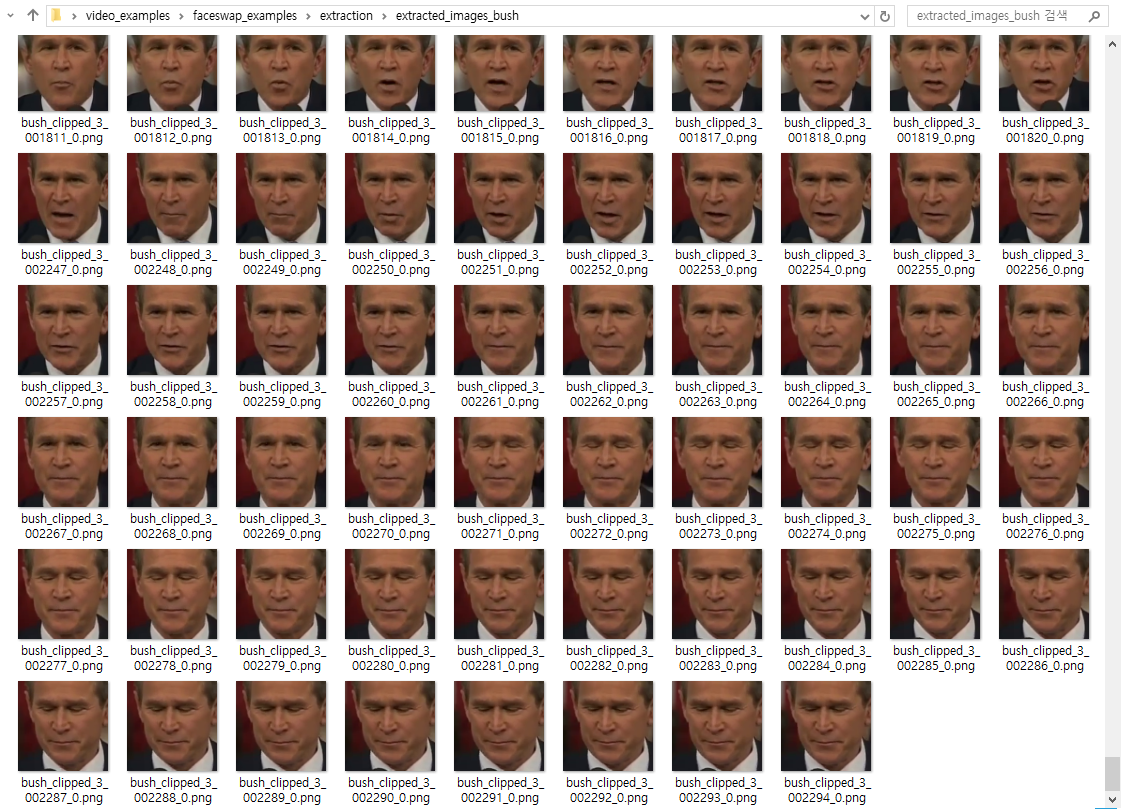
결과적으로 서로 다른 사람이 등장하는 2개의 동영상으로부터 각 인물에 대한 이미지를 1,000장 이상씩 추출하였다. 기본적으로 동영상으로부터 이미지를 추출할 때는 두 가지를 기억하자.
- 기본적으로 두 동영상에 대해서 사람의 얼굴 이미지가 각각 최소한 1,000장 이상 모일 수 있도록 준비해야 한다. 이미지가 너무 적으면 당연히 학습 결과 모델의 성능이 떨어진다.
- 또한 되도록 다양한 얼굴 각도와 표정이 나오도록 이미지를 구비할수록 좋다.
'기타' 카테고리의 다른 글
| STM32CubeIDE를 활용한 Nucleo-144 Blinky 예제 (0) | 2020.01.31 |
|---|---|
| STM32CubeIDE 설치 방법 (0) | 2020.01.31 |
| GPU Shark를 이용한 GPU 모니터링(Monitoring) (0) | 2020.01.30 |
| DeepFakes 소프트웨어: FaceSwap 소개 및 설치 방법 (7) | 2020.01.30 |
| 윈도우(Windows)에 아나콘다(Anaconda) 설치 및 주피터 노트북 실행하기 (0) | 2020.01.30 |
