CNN (Convolutional Neural Network) 요약 정리
본 글은 cs231n 강의 노트를 정리한 것입니다.
※ CNN을 왜 사용할까? ※
CNN을 이용한 분류기(classification)도 일반 뉴럴 네트워크처럼 이미지를 입력으로 받아 분류 결과를 출력한다. 다만 CNN은 이미지 데이터가 가지는 특성을 활용하여 더 적은 파라미터를 사용하며, 높은 성능을 보인다.
일반적인 신경망(MLP)을 이용해 이미지를 처리할 때는 매우 많은 가중치가 필요하다. MNIST 데이터셋을 넘어서 CIFAR-10 데이터셋만 되어도 MLP를 이용하면 해결하기 어렵다. 32 x 32 크기의 색상 이미지라면 32 x 32 x 3 = 3,072개의 가중치(weight)가 필요하다. 은닉층의 크기가 1,000이라면 순식간에 3,072,000개의 파라미터가 필요하게 된다. 반면에 CNN은 커널(kernel)을 공유하기 때문에 훨씬 적은 가중치만 있어도 된다.
▶ 일반 신경망의 특징: 많은 가중치 필요, fully-connection 사용
▶ CNN의 특징: 적은 가중치 필요 (파라미터 공유), 이미지 처리에 적합
예를 들어 컨볼루션 연산에서 커널의 개수 K = 12, 수용 영역 크기 F = 4, 이전 레이어의 채널 = 3이라고 해보자. 그러면 실제로 커널에 필요한 파라미터의 개수는 12 X 4 X 4 X 3 = 576이 된다. 이처럼 커널을 이용해 파라미터를 공유하면 필요한 가중치의 개수가 획기적으로 줄어들게 된다. 이런 아이디어가 사용될 수 있는 이유는, 하나의 패치 특징(patch feature)은 이미지의 전반적인 위치에서 나타날 수 있기 때문이다. 예를 들어 일반적인 이미지 데이터셋을 확인해 보면 대각선 엣지(edge) 형태의 특징은 이미지 전반에서 나올 수 있다.
※ CNN의 동작 ※
CNN의 각 레이어는 너비(width), 높이(height), 깊이(depth)로 구성된다. 일반적인 MLP와 비교했을 때 깊이(depth)가 추가되었다.

CNN는 다음과 같은 레이어로 구성된다.
▶ 입력 레이어: 입력 이미지가 들어오는 레이어
▶ 컨볼루션 레이어: 입력 이미지의 일부 수용 영역(receptive field)에 대하여 컨볼루션 연산을 수행
▶ ReLU 레이어: 일반적으로 사용되는 액티베이션 함수(activation function)
▶ Pool 레이어: 너비(width)와 높이(height)에 대해 다운샘플링(downsampling) 수행
▶ FC 레이어: 네트워크의 마지막 부분에서 실질적으로 클래스 분류 수행
컨볼루션 연산은 다음과 같이 수행된다.
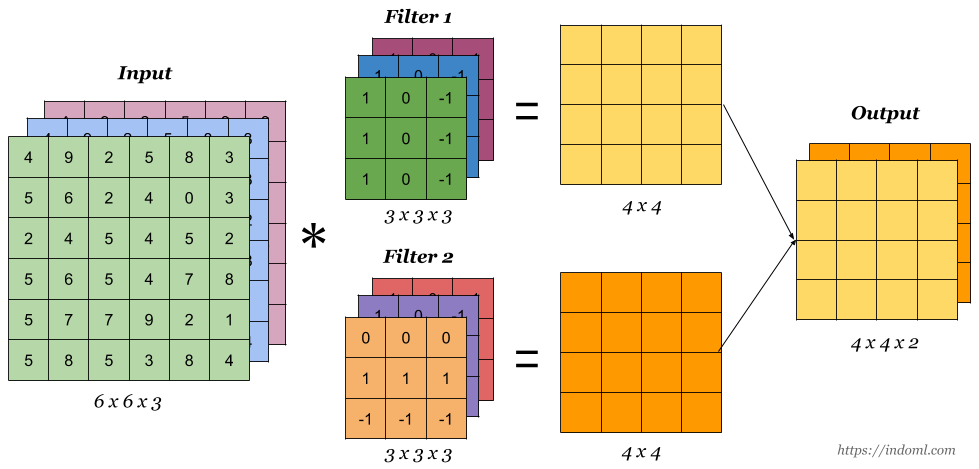
조금 더 자세한 예시로 확인하면 다음과 같다. indoml 사이트에서 정리한 글이 매우 보기 편하므로 참고해보자.
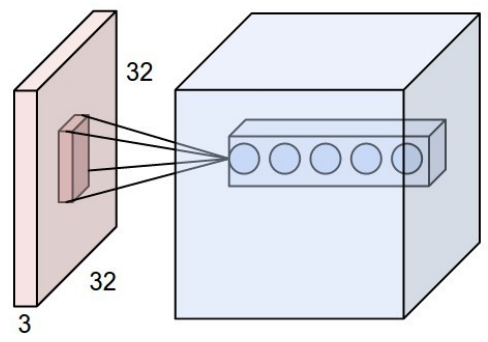
이때 커널은 스트라이드(stride)의 크기만큼 슬라이딩하며 컨볼루션 연산을 수행한다.

또한 처음에 가장 헷갈리는 부분은 컨볼루션 각 레이어의 차원이다. 커널(kernel)을 이용해 컨볼루션 연산을 수행하는데, 이때 이전 레이어의 채널(channel) 크기와 커널의 채널 크기가 동일하다. 예를 들어 입력 크기가 32 x 32 x 3이면, 커널에서도 5 x 5 x 3과 같이 채널의 크기로 3을 사용한다.
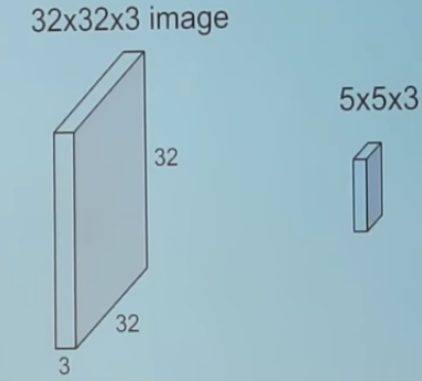
또한 컨볼루션 연산을 수행한 뒤에는 커널의 개수가 레이어의 채널 크기가 된다. 예를 들어 32 x 32 x 3 입력에 대하여 5 x 5 x 3짜리 커널을 6개 사용했다면, 출력으로 나온 레이어는 28 x 28 x 6 크기를 가진다.

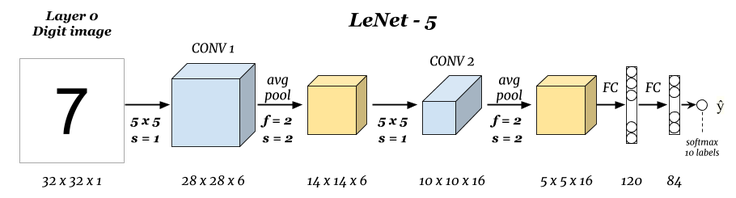
일반적으로 CNN에서는 레이어가 깊어지면 너비와 높이는 감소하고 깊이(채널)는 증가한다. 이때 각 채널은 서로 다른 특징(feature)을 적절히 추출하도록 학습되므로, 다양한 특징들을 조합하여 적절히 분류를 수행하게 된다. 예를 들어 가장 기본적인 형태의 LeNet을 확인해보자. 최신 네트워크들은 이것보다 훨씬 깊은 레이어를 가지고 있지만, LeNet은 CNN의 전형적인 형태를 잘 보여주고 있다.
레이어가 깊어질수록 너비와 높이는 감소하고 채널은 증가하는 것을 확인할 수 있다.
또한 다운샘플링(downsampling) 목적으로 풀링 레이어(pooling layer)를 사용한다. 일반적으로 분류 네트워크에서는 max pooling과 average pooling이 사용된다. 예를 들어 2 x 2 풀링을 수행하는 경우 액티베이션(activation)의 25%만 남게 되므로 참고로 풀링을 수행해도 차원(dimension)은 변하지 않는다.
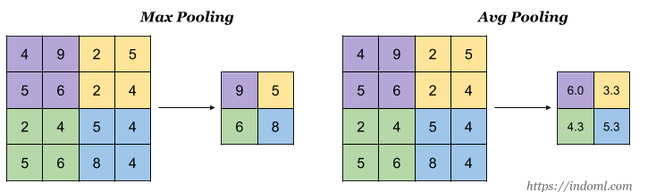
※ CNN의 일반적인 구조 ※
가장 일반적인 CNN의 패턴은 다음과 같다. 결과적으로 마지막 FC 레이어를 거쳐 클래스 분류 결과가 나오게 된다. LeNet 이후에도 굉장히 다양한 CNN이 등장했으나 대부분 아래와 같은 패턴을 따른다는 점이 특징이다.
INPUT → [[CONV → RELU] * N → POOL] * M → [FC → RELU] * K → FC
예시 1) INPUT → FC
예시 2) INPUT → CONV → RELU → FC
예시 3) INPUT → [CONV → RELU → POOL] * 2 → FC → RELU → FC
※ 다양한 CNN 아키텍처 ※
1) AlexNet
이미지 분류(Image Classification)에서 CNN이 큰 주목을 받게 해 준 네트워크다. ILSVRC 2012에 출전하여 압도적인 성능 차이를 보였다. CONV 레이어 이후에 바로 풀링 레이어를 넣지 않고, CONV를 중첩해서 사용했다는 점이 특징이다.
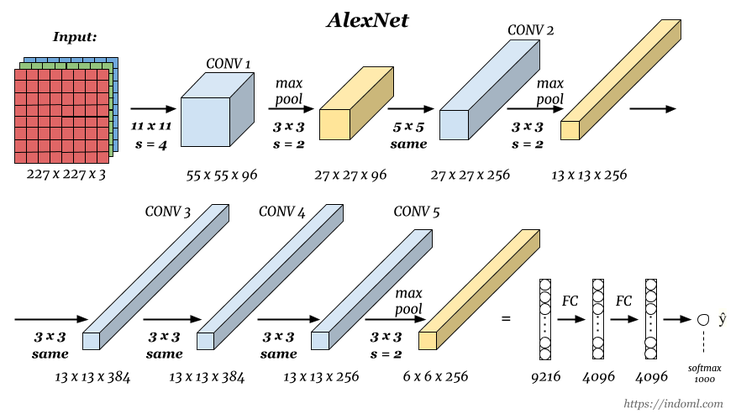
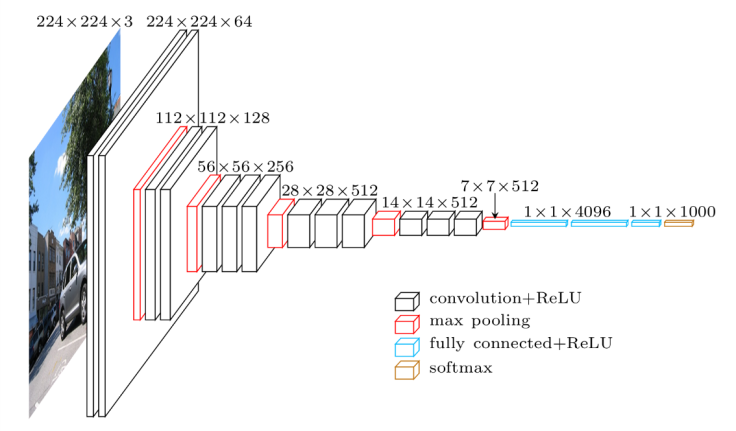
2) VGGNet
ILSVRC 2014에서 2등을 한 네트워크다. VGG에서는 레이어를 깊게 쌓았을 때 더 좋은 성능이 나올 수 있다는 것을 보여주었다. 16개의 레이어로 구성되는 VGG-16이 대표적이다.
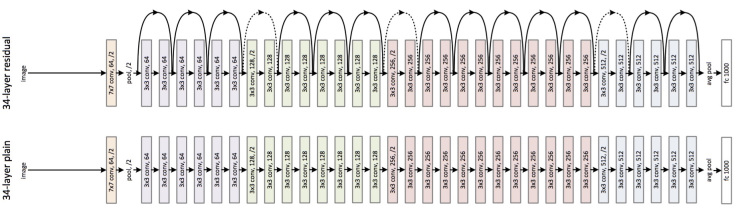
3) ResNet
ILSVRC 2015에서 1등을 한 네트워크인 ResNet는 skip connection과 배치 정규화(batch normalization)를 사용했다는 점이 특징이다. 지금은 매우 많은 네트워크에서 skip connection과 배치 정규화를 사용하고 있으며, 2020년까지도 ResNet은 많은 논문에서 베이스라인(baseline)으로 성능 비교 대상이다.
'인공지능' 카테고리의 다른 글
| ResNet처럼 Batch Normalization을 포함한 네트워크를 Feature Extractor로 사용할 때 유의할 점 (0) | 2021.02.24 |
|---|---|
| PyTorch의 전이 학습(Transfer Learning)에서 Freezing 여부에 따른 성능 차이 및 유의점 (0) | 2021.02.24 |
| PyTorch 나만의 데이터셋을 만들고, 이를 ImageFolder로 불러오기 (1) | 2020.04.10 |
| PyTorch에서 특정 Dataset을 열어 이미지 출력하기 (3) | 2020.04.10 |
| Google CoLab으로 머신러닝 공부 편하게 시작하기 (0) | 2019.06.05 |
