PyTorch의 ImageFolder 설명 및 ImageFolder 형식의 데이터셋 구성하기 예제
PyTorch에서는 ImageFolder 라이브러리를 제공하는데, 다음과 같이 계층적인 폴더 구조에서 데이터셋을 불러올 때 사용할 수 있다. 다음과 같이 각 이미지들이 각 클래스명(class name)을 갖는 폴더 안에 들어가 있는 구조라면, ImageFolder 라이브러리를 이용해 바로 불러올 수 있다.
dataset/
class 0/
0.jpg
1.jpg
...
class 1/
0.jpg
1.jpg
...
...
class 9/
0.jpg
1.jpg
...
이러한 ImageFolder 형식을 가지고 있지 않은 데이터셋 예제를 불러와서, ImageFolder 형식에 맞게 변형해 보겠다. 한 번 다음의 데이터셋 예제를 확인해 보자.
▶ Scene Classification Dataset 예제: https://github.com/ndb796/Scene-Classification-Dataset
GitHub - ndb796/Scene-Classification-Dataset
Contribute to ndb796/Scene-Classification-Dataset development by creating an account on GitHub.
github.com
기본적으로 Scene Classification Dataset은 25,000개가량의 다양한 자연 경치(scene) 이미지로 구성되어 있다. 이때 각 이미지에 대하여 카테고리(category) 정보가 주어진다. 먼저 다음과 같은 코드로 전체 이미지 데이터를 다운로드한다.
# 깃허브에서 데이터셋 다운로드하기
!git clone https://github.com/ndb796/Scene-Classification-Dataset
# 폴더 안으로 이동
%cd Scene-Classification-Dataset
이때 데이터셋 폴더 구성은 다음과 같다.
Dataset/
train-scene classification/
train/ # 전체 이미지가 담긴 폴더입니다.
0.jpg
1.jpg
2.jpg
...
24333.jpg
24334.jpg
train.csv # 학습 이미지마다 클래스(class) 정보가 포함되어 있습니다.
test_WyRytb0.csv # 최종 테스트(test) 이미지의 번호를 포함하며, 본 실습에서 사용하지 않습니다.
장면(scene) 데이터셋은 정확히 24,335개의 다양한 자연 경치(scene) 이미지로 구성되어 있다. 이때 각 이미지는 150 X 150 크기를 가진다. 또한, 총 6개의 클래스(class)로 구성된다. 전체 클래스 목록은 다음과 같다.
0. 빌딩(buildings)
1. 숲(forests)
2. 빙하(glacier)
3. 산(mountains)
4. 바다(sea)
5. 거리(street)
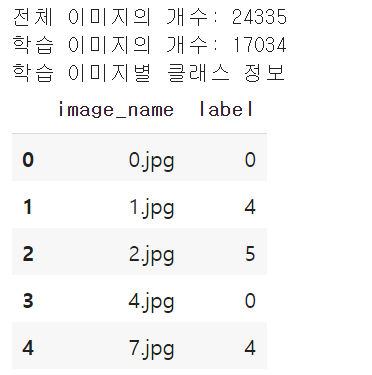
이때 다음과 같은 방법으로 학습 이미지의 개수를 확인할 수 있다. 구체적으로 os 라이브러리의 os.listdir()를 이용하여 이미지 폴더에 존재하는 파일 이름을 확인할 수 있다. 예를 들어 다음과 같은 코드로 이미지의 개수를 확인할 수 있다.
import os
import pandas as pd
path = 'train-scene classification/'
# 전체 이미지 개수 출력하기
file_list = os.listdir(path + 'train/')
print('전체 이미지의 개수:', len(file_list))
# 학습 이미지 확인하기
dataset = pd.read_csv(path + 'train.csv')
print('학습 이미지의 개수:', len(dataset))
print('학습 이미지별 클래스 정보')
dataset.head()
실행 결과는 다음과 같다.
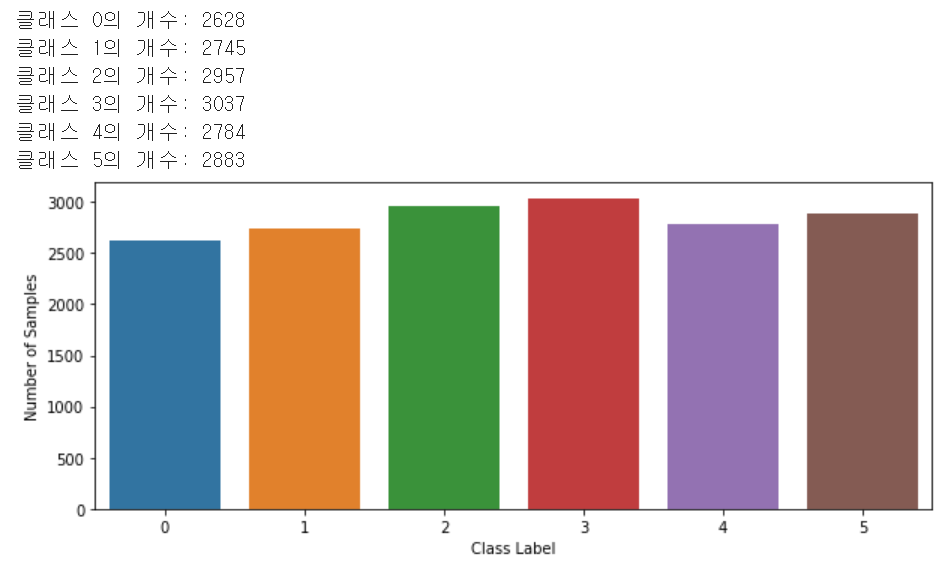
이때 클래스별 학습 이미지의 개수를 구하고자 한다면 다음과 같이 할 수 있다.
import matplotlib.pyplot as plt
import seaborn as sns
plt.rcParams['figure.figsize'] = (8.0, 6.0) # 그림의 기본 크기 설정
# 각 클래스별 개수 출력
print('클래스 0의 개수:', len(dataset[dataset.label == 0]))
print('클래스 1의 개수:', len(dataset[dataset.label == 1]))
print('클래스 2의 개수:', len(dataset[dataset.label == 2]))
print('클래스 3의 개수:', len(dataset[dataset.label == 3]))
print('클래스 4의 개수:', len(dataset[dataset.label == 4]))
print('클래스 5의 개수:', len(dataset[dataset.label == 5]))
# 각 클래스에 따른 학습 이미지의 개수를 출력하기
fig, ax = plt.subplots(figsize = (10, 4)) # 그림 크기 설정
sns.countplot(x ='label', data=dataset)
plt.xlabel("Class Label")
plt.ylabel("Number of Samples")
plt.show()
실행 결과는 다음과 같다.
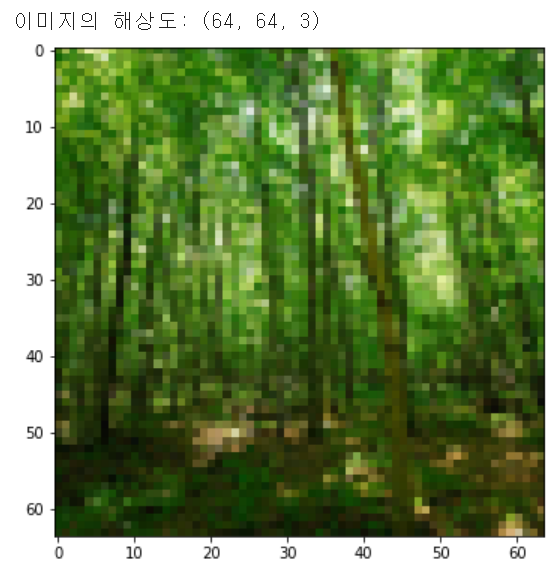
이때 특정한 이미지를 불러와 화면에 출력하고자 한다면 다음과 같이 할 수 있다. 아래 코드는 첫 번째 이미지를 불러와 화면에 출력하는 코드다.
from skimage.transform import resize
from PIL import Image
import numpy as np
img = Image.open(path + 'train/' + file_list[0])
img = np.asarray(img)
img = resize(img, (64, 64, 3))
print('이미지의 해상도:', img.shape)
# 이미지 출력하기
plt.imshow(img)
plt.show()
실행 결과는 다음과 같다.
이어서 학습/검증 데이터셋을 나눌 수 있다. 이때 간단히 sklearn 라이브러리의 train_test_split()을 이용하면 된다. 예를 들어 학습 이미지 데이터를 8:2 비율로 학습(training)과 검증(validation)으로 나누는 예제는 다음과 같다.
from sklearn.model_selection import train_test_split
train_dataset, val_dataset = train_test_split(dataset, test_size=0.2)
print('학습 데이터셋 크기:', len(train_dataset))
print('검증 데이터셋 크기:', len(val_dataset))
실행 결과는 다음과 같다. 이제 결과적으로 데이터셋이 나누어진 것이다.

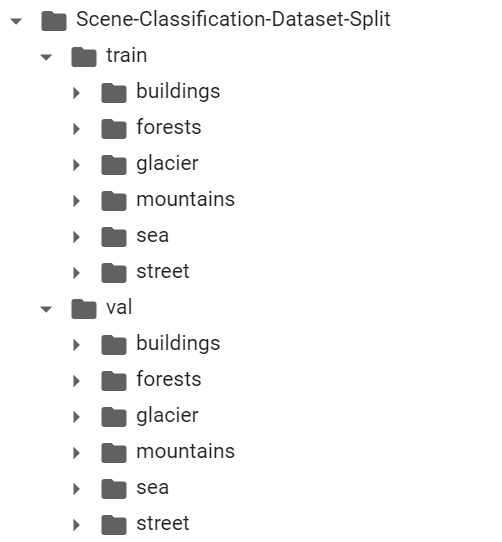
이제 나누어진 데이터셋을 적절한 폴더에 저장하기 위해 다음과 같이 먼저 폴더를 만든다. 클래스 개수가 6개뿐이므로, 간단히 다음과 같이 모든 폴더를 만들 수 있다.
!mkdir Scene-Classification-Dataset-Split
!mkdir Scene-Classification-Dataset-Split/train
!mkdir Scene-Classification-Dataset-Split/train/buildings
!mkdir Scene-Classification-Dataset-Split/train/forests
!mkdir Scene-Classification-Dataset-Split/train/glacier
!mkdir Scene-Classification-Dataset-Split/train/mountains
!mkdir Scene-Classification-Dataset-Split/train/sea
!mkdir Scene-Classification-Dataset-Split/train/street
!mkdir Scene-Classification-Dataset-Split/val
!mkdir Scene-Classification-Dataset-Split/val/buildings
!mkdir Scene-Classification-Dataset-Split/val/forests
!mkdir Scene-Classification-Dataset-Split/val/glacier
!mkdir Scene-Classification-Dataset-Split/val/mountains
!mkdir Scene-Classification-Dataset-Split/val/sea
!mkdir Scene-Classification-Dataset-Split/val/street
실행하면 다음과 같이 전체 폴더가 구성되는 것을 확인할 수 있다.
이제 ImageFolder 형식에 맞게 이미지를 저장해보자. 모든 이미지는 (64 X 64 X 3) 형식으로 resize하여 저장한다.
import time
classes = ['buildings', 'forests', 'glacier', 'mountains', 'sea', 'street']
######### 학습 데이터셋 #########
start_time = time.time() # 시작 시간
# 데이터 정보를 하나씩 확인하며
for index, row in train_dataset.iterrows():
# 이미지 정보를 배열에 담기
img = Image.open(path + 'train/' + row['image_name'])
img = np.asarray(img)
img = resize(img, (64, 64, 3))
img = Image.fromarray((img * 255).astype(np.uint8))
saved = 'Scene-Classification-Dataset-Split/train/' + classes[row['label']] + '/' + str(index) + '.png'
img.save(saved, 'PNG')
print("소요된 시간(초 단위):", time.time() - start_time) # 실행 시간
######### 검증 데이터셋 #########
start_time = time.time() # 시작 시간
# 데이터 정보를 하나씩 확인하며
for index, row in val_dataset.iterrows():
# 이미지 정보를 배열에 담기
img = Image.open(path + 'train/' + row['image_name'])
img = np.asarray(img)
img = resize(img, (64, 64, 3))
img = Image.fromarray((img * 255).astype(np.uint8))
saved = 'Scene-Classification-Dataset-Split/val/' + classes[row['label']] + '/' + str(index) + '.png'
img.save(saved, 'PNG')
print("소요된 시간(초 단위):", time.time() - start_time) # 실행 시간
이후에 만들어진 폴더를 압축(.zip)하여 저장한다.
!zip -r Scene-Classification-Dataset-Split.zip ./Scene-Classification-Dataset-Split/*'인공지능' 카테고리의 다른 글
| ResNet처럼 Batch Normalization을 포함한 네트워크를 Feature Extractor로 사용할 때 유의할 점 (0) | 2021.02.24 |
|---|---|
| PyTorch의 전이 학습(Transfer Learning)에서 Freezing 여부에 따른 성능 차이 및 유의점 (0) | 2021.02.24 |
| CNN (Convolutional Neural Network) 요약 정리 (0) | 2020.10.20 |
| PyTorch 나만의 데이터셋을 만들고, 이를 ImageFolder로 불러오기 (1) | 2020.04.10 |
| PyTorch에서 특정 Dataset을 열어 이미지 출력하기 (3) | 2020.04.10 |
