Clarifai 이미지 인식 서비스 사용법 (Feat. 유명인 얼굴 인식 서비스)
Clarifai는 이미지 인식 서비스를 제공하는 대표적인 회사입니다. 무료로도 꽤 많은 API를 사용해 볼 수 있습니다. 홈페이지에 방문한 뒤에 바로 모델을 사용해 볼 수 있는데요. 예를 들어 유명인(celebrity) 얼굴 인식 서비스는 다음의 경로에 방문하여 사용해 볼 수 있습니다.
▶ Clarifai 유명인 얼굴 인식 서비스: www.clarifai.com/models/celebrity-image-recognition
Analyze Images Using Celebrity Face Recognition | Clarifai
To analyze images and return probability scores, Clarifai Celebrity Face Recognition Model contains 10,000+ famous faces. Who do you look like? Try it out!
www.clarifai.com
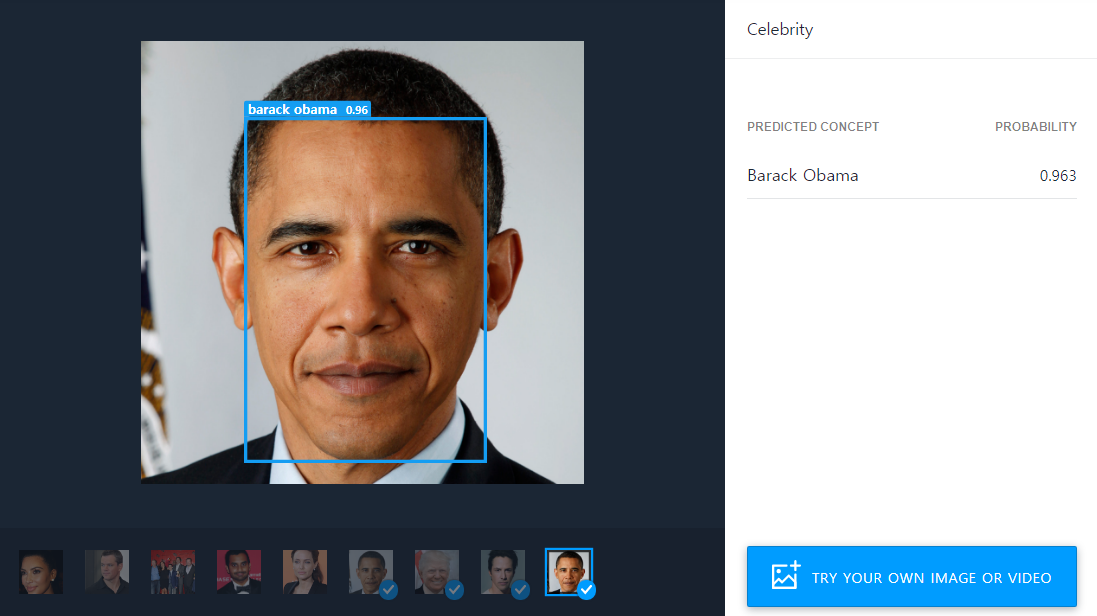
이 서비스에 접속해서 다음과 같이 이미지를 업로드하면 인식 결과 레이블(label)이 나옵니다. 저는 한 번 버락 오바마 대통령 사진을 업로드 해보았습니다. 그랬더니 다음과 같은 결과가 나오는 것을 알 수 있었습니다.
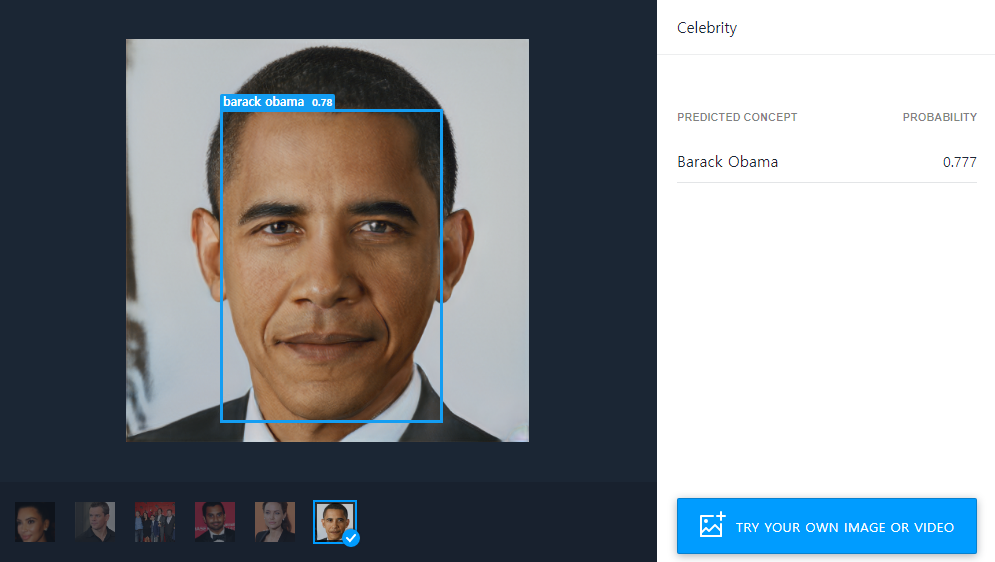
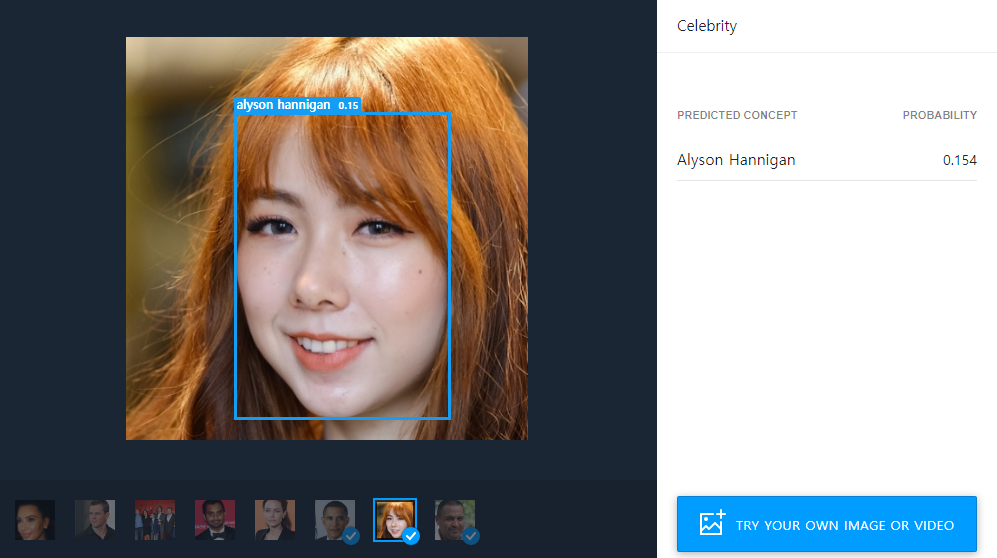
참고로 유명인(celebrity)이 아닌 일반적인 사람의 얼굴을 넣는 경우, 임의의 유명인으로 레이블링을 진행하되 낮은 확률(probability)로 분류하는 것을 알 수 있습니다.
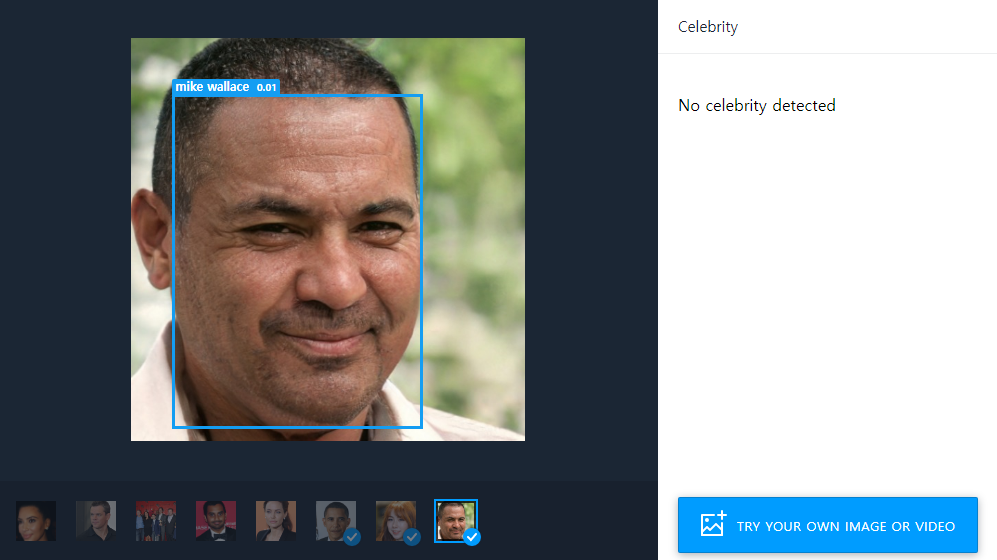
특히 다음과 같이 확률(probability) 자체가 매우 낮은 경우에는 다음과 같이 "No celebrity detected"라는 메시지가 출력되는 것을 알 수 있습니다.
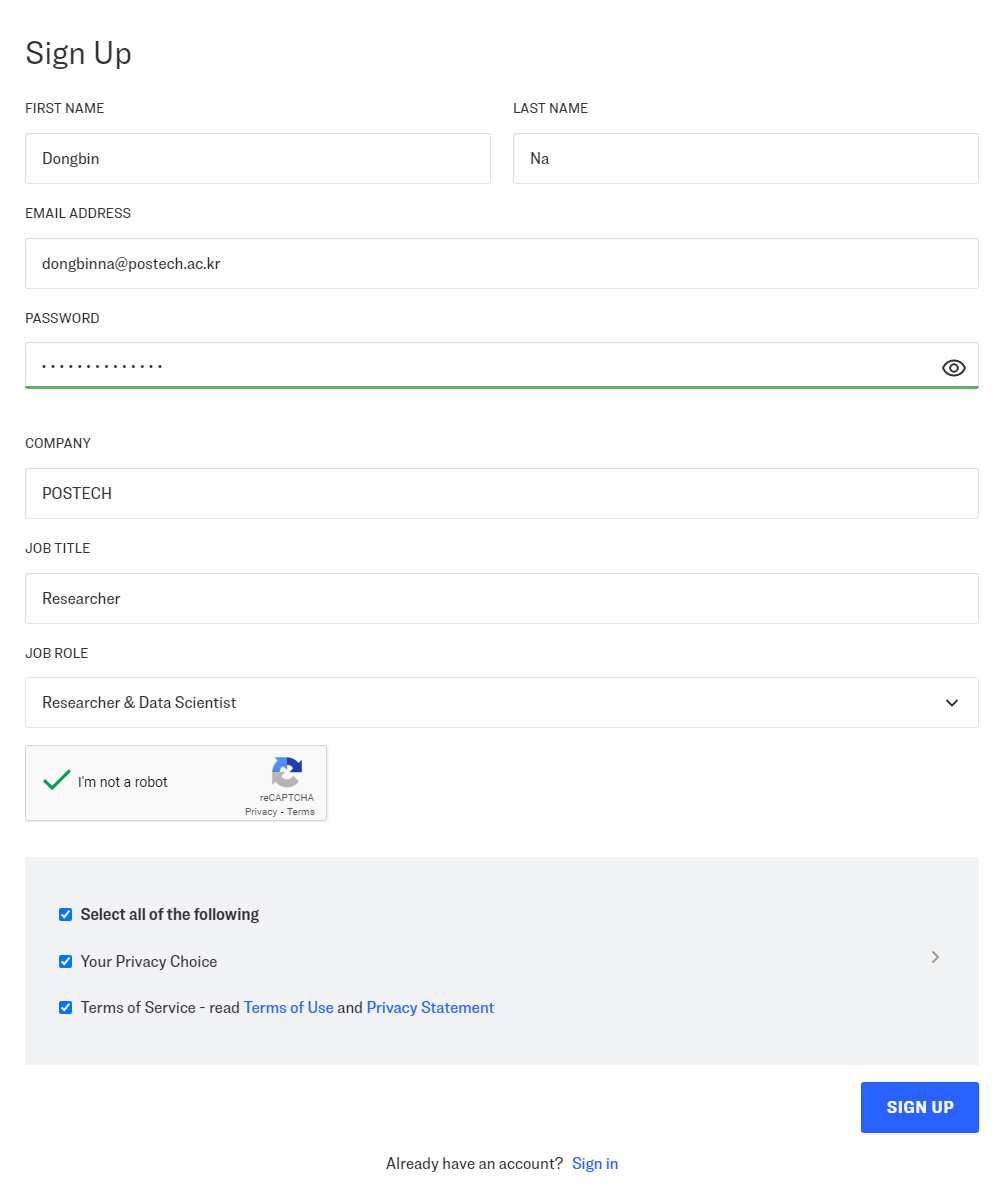
▶ Clarifai 서비스 회원가입(Sign Up): portal.clarifai.com/signup
Clarifai 서비스를 편리하게 사용하기 위해서는 회원가입을 진행하면 됩니다. 일단 저는 무료로 가입하고 무료 서비스를 사용해 보았습니다. Clarifai 서비스 회원가입 방법은 간단합니다. 이메일 인증이 필요하기 때문에 이메일 주소를 정확히 입력할 필요가 있습니다. 예를 들어 저는 다음과 같이 회원가입을 진행했습니다.
회원가입 이후에는 바로 애플리케이션(application)을 생성하여 사용해 볼 수 있습니다. 이때 API 키를 발급해 주기 때문에 발급받은 API 키를 이용해 다양한 프로그래밍 언어에서 Clarifai 서비스를 사용해 볼 수 있습니다.
※ Clarifai API 사용 방법 ※
뿐만 아니라 Clarifai는 각종 API를 지원하고 있습니다. 예를 들어 파이썬(Python)을 이용해 얼굴 인식(face recognition) 기능을 사용해 볼 수 있습니다. 자세한 내용은 다음의 깃허브 저장소에 방문하시면 확인 가능합니다.
▶ 파이썬 clarifai 라이브러리: github.com/Clarifai/clarifai-python
Clarifai/clarifai-python
DEPRECATED Clarifai API Python Client, use clarifai-python-grpc instead - Clarifai/clarifai-python
github.com
특정 URL로부터 사진 파일을 받아와 간단한 사용 방법 예시는 다음과 같습니다.
from clarifai.rest import ClarifaiApp
from IPython.display import Image, display
image_url = 'https://samples.clarifai.com/celebrity.jpg'
display(Image(image_url))
app = ClarifaiApp(api_key=API_KEY)
model = app.public_models.celebrity_model
response = model.predict_by_url(url=image_url)
regions = response['outputs'][0]['data']['regions']
concepts = regions[0]['data']['concepts']
for concept in concepts:
print(f'Label: {concept["name"]} (Probability: {concept["value"]})')
(2022년 업데이트) 최근에는 공식 라이브러리가 Clarifai Python gRPC Client로 업데이트되었습니다. 그래서 다음과 같이 코드를 작성해야 합니다.
metadata = (('authorization', f'Key {API_KEY}'),)
image_url = 'https://samples.clarifai.com/celebrity.jpg'
display(Image(image_url))
request = service_pb2.PostModelOutputsRequest(
model_id=model_id, # You may use any public or custom model ID.
inputs=[
resources_pb2.Input(data=resources_pb2.Data(image=resources_pb2.Image(url=image_url)))
])
response = stub.PostModelOutputs(request, metadata=metadata)
if response.status.code != status_code_pb2.SUCCESS:
print("There was an error with your request!")
print("\tCode: {}".format(response.outputs[0].status.code))
print("\tDescription: {}".format(response.outputs[0].status.description))
print("\tDetails: {}".format(response.outputs[0].status.details))
raise Exception("Request failed, status code: " + str(response.status.code))
regions = response.outputs[0].data.regions
concepts = regions[0].data.concepts
for concept in concepts:
print(f'Label: {concept.name} (Probability: {concept.value})')
위 코드를 실행하면 다음과 같이 사진에서 유명인 얼굴을 추출한 결과가 나오게 됩니다.

또한 다음과 같이 파일 경로(file path)로부터 이미지를 읽어와 화면에 출력할 수도 있습니다.
from clarifai.rest import ClarifaiApp
from IPython.display import Image, display
image_path = 'aligned_images/barack_obama_01.png'
display(Image(image_path))
app = ClarifaiApp(api_key=API_KEY)
model = app.public_models.celebrity_model
response = model.predict_by_filename(filename=image_path)
regions = response['outputs'][0]['data']['regions']
concepts = regions[0]['data']['concepts']
for concept in concepts:
print(f'Label: {concept["name"]} (Probability: {concept["value"]})')
(2022년 업데이트) 최근에는 공식 라이브러리가 Clarifai Python gRPC Client로 업데이트되었습니다. 그래서 다음과 같이 코드를 작성해야 합니다.
metadata = (('authorization', f'Key {API_KEY}'),)
image_url = 'aligned_images/barack_obama_01.png'
display(Image(image_url))
with open(image_url, "rb") as f:
file_bytes = f.read()
request = service_pb2.PostModelOutputsRequest(
model_id=model_id, # You may use any public or custom model ID.
inputs=[
resources_pb2.Input(data=resources_pb2.Data(image=resources_pb2.Image(base64=file_bytes)))
])
response = stub.PostModelOutputs(request, metadata=metadata)
if response.status.code != status_code_pb2.SUCCESS:
print("There was an error with your request!")
print("\tCode: {}".format(response.outputs[0].status.code))
print("\tDescription: {}".format(response.outputs[0].status.description))
print("\tDetails: {}".format(response.outputs[0].status.details))
raise Exception("Request failed, status code: " + str(response.status.code))
regions = response.outputs[0].data.regions
concepts = regions[0].data.concepts
for concept in concepts:
print(f'Label: {concept.name} (Probability: {concept.value})')
실행 결과 예시는 다음과 같습니다.

참고로 API를 통해 얻은 결과는 공식 웹 사이트에 넣어서 얻은 결과와 동일한 확률 값을 내보내는 것을 알 수 있습니다.
▶ 참고 소스코드: github.com/ndb796/Clarifai-Python-Celebrity-Recognition
ndb796/Clarifai-Python-Celebrity-Recognition
Clarifai Python API: Celebrity Recognition Examples - ndb796/Clarifai-Python-Celebrity-Recognition
github.com
'기타' 카테고리의 다른 글
| SSH Key를 이용해 GitHub 계정의 저장소(repository) 코드에 접근하기 (0) | 2021.03.06 |
|---|---|
| PyTorch에서 ImageFolder와 유사한 클래스를 구현해야 할 때 사용할 수 있는 코드 템플릿 (0) | 2021.03.03 |
| 깃허브(GitHub)의 README 파일에 이미지/동영상 올리는 방법 (1) | 2021.03.01 |
| 얼굴 성별 분류(Gender Classification) 데이터셋 소개 및 다운로드 방법 (0) | 2021.02.27 |
| CelebA: 유명인(Celebrity) 얼굴 데이터셋(Face Dataset) 소개 (0) | 2021.02.27 |
깃허브(GitHub)의 README 파일에 이미지/동영상 올리는 방법
※ 깃허브 README 파일에 마크다운으로 이미지 올리는 법 ※
깃허브(GitHub)의 README 파일에 이미지(image)를 올리는 것은 간단하다. 먼저 [Issues] 탭으로 이동한 뒤에 하나의 이미지를 업로드한다. 그러면 깃허브 서비스 서버에 해당 이미지가 업로드된다.
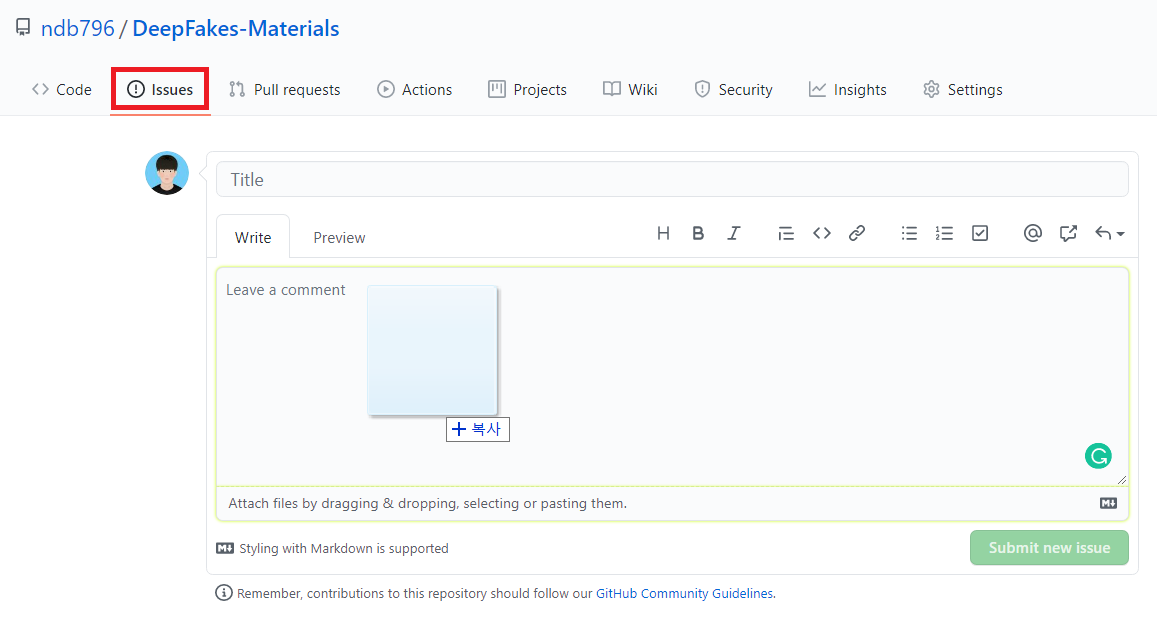
잠시 기다리면 다음과 같이 이미지 경로가 생성된다. 이 경로를 붙여넣으면 된다.
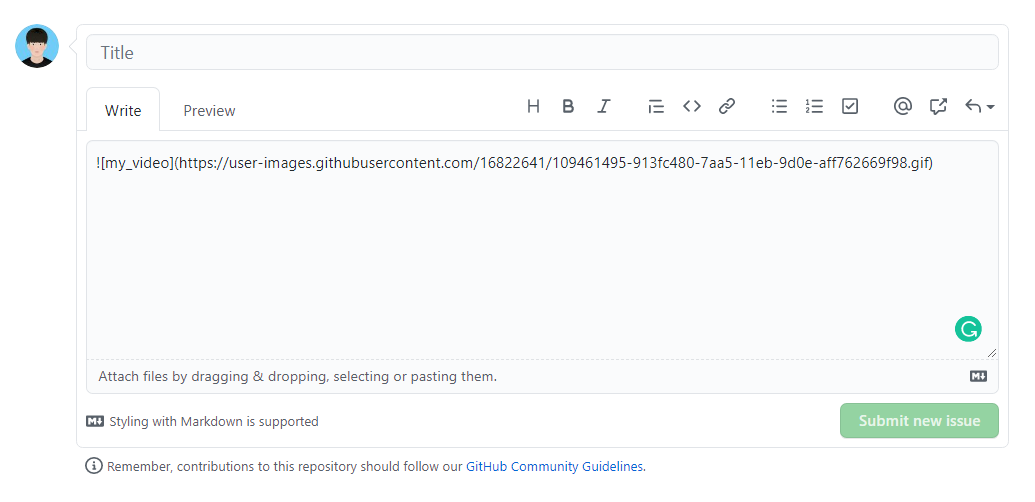
이제 해당 경로를 복사한 뒤에 README 파일에 마크다운(markdown) 양식에 맞게 다음과 같이 붙여넣으면 된다.
<img width="{해상도 비율}" src="{이미지 경로}"/>
필자의 경우 다음과 같이 붙여넣었다.
<img width="80%" src="https://user-images.githubusercontent.com/16822641/109461495-913fc480-7aa5-11eb-9d0e-aff762669f98.gif"/>
결과적으로 다음과 같이 붙여넣을 수 있다. 참고로 필자는 단순한 이미지 파일이 아닌 .gif 파일을 붙여넣었다. 그래도 정상적으로 잘 동작한다.
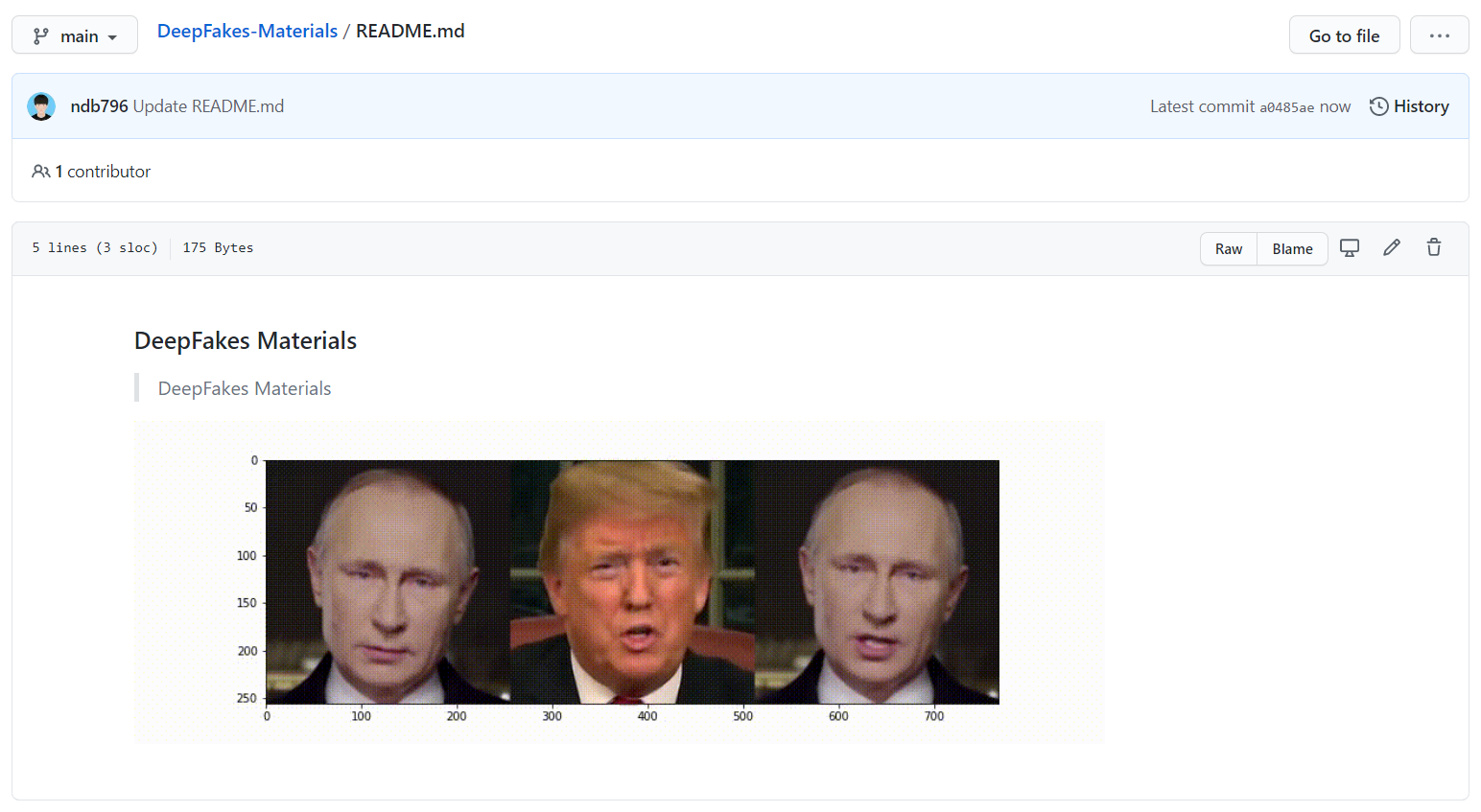
※ 참고: 동영상 파일(.mp4)을 .gif로 확장자로 만드는 방법 ※
깃허브(GitHub)에 동영상 파일을 직접적으로 업로드하기는 쉽지 않다. 그래서 일반적으로 MP4 확장자를 GIF 확장자로 변형한 뒤에 업로드한다. 아래 사이트에 방문하면 쉽게 변경할 수 있다.
▶ Cloud Convert MP4 to GIF 변환기: cloudconvert.com/mp4-to-gif
방문 이후에 [Select File] 버튼을 눌러 변환할 동영상 파일을 선택한다.
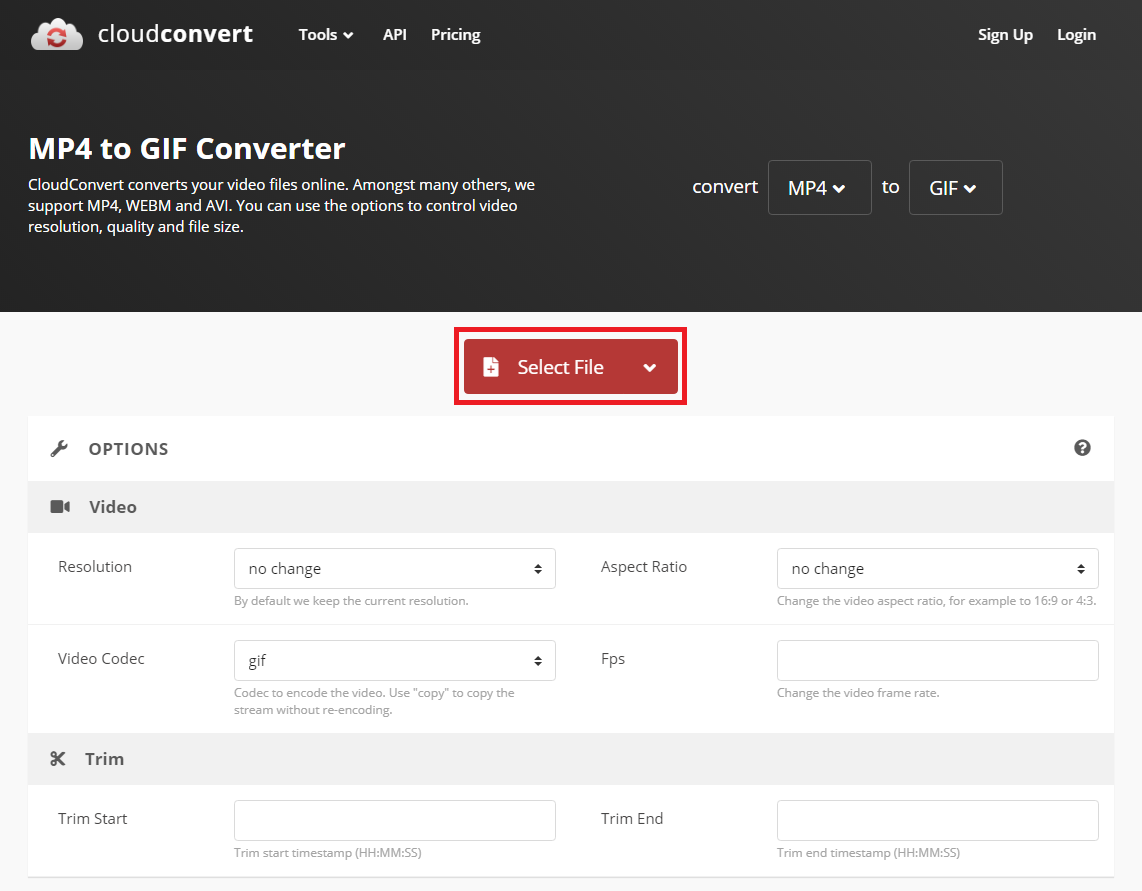
변환할 동영상 파일을 선택한 뒤에는 [Convert] 버튼을 눌러 변환을 진행한다.

변환이 완료된 이후에 [Download] 버튼을 눌러 완성된 파일을 받을 수 있다.

'기타' 카테고리의 다른 글
| PyTorch에서 ImageFolder와 유사한 클래스를 구현해야 할 때 사용할 수 있는 코드 템플릿 (0) | 2021.03.03 |
|---|---|
| Clarifai 이미지 인식 서비스 사용법 (Feat. 유명인 얼굴 인식 서비스) (1) | 2021.03.03 |
| 얼굴 성별 분류(Gender Classification) 데이터셋 소개 및 다운로드 방법 (0) | 2021.02.27 |
| CelebA: 유명인(Celebrity) 얼굴 데이터셋(Face Dataset) 소개 (0) | 2021.02.27 |
| Cat and Dog 데이터셋 (강아지/고양이 분류 데이터셋) (0) | 2021.02.23 |
얼굴 성별 분류(Gender Classification) 데이터셋 소개 및 다운로드 방법
얼굴 성별 분류(face gender classification) 데이터셋은 캐글(Kaggle)에서 다운로드 가능하다.
▶ 학습 데이터셋 개수: 남성/여성 각각 23,000개씩
▶ 평가 데이터셋 개수: 남성/여성 각각 5,500개씩
실제 용량은 약 280MB 정도이며, 전체 데이터셋에 포함된 이미지는 60,000개가 조금 안 된다. 각각 이미지 크기는 실제로 열어 보면 약 100 X 100 정도의 해상도(resolution)로 구성된 것을 알 수 있다.
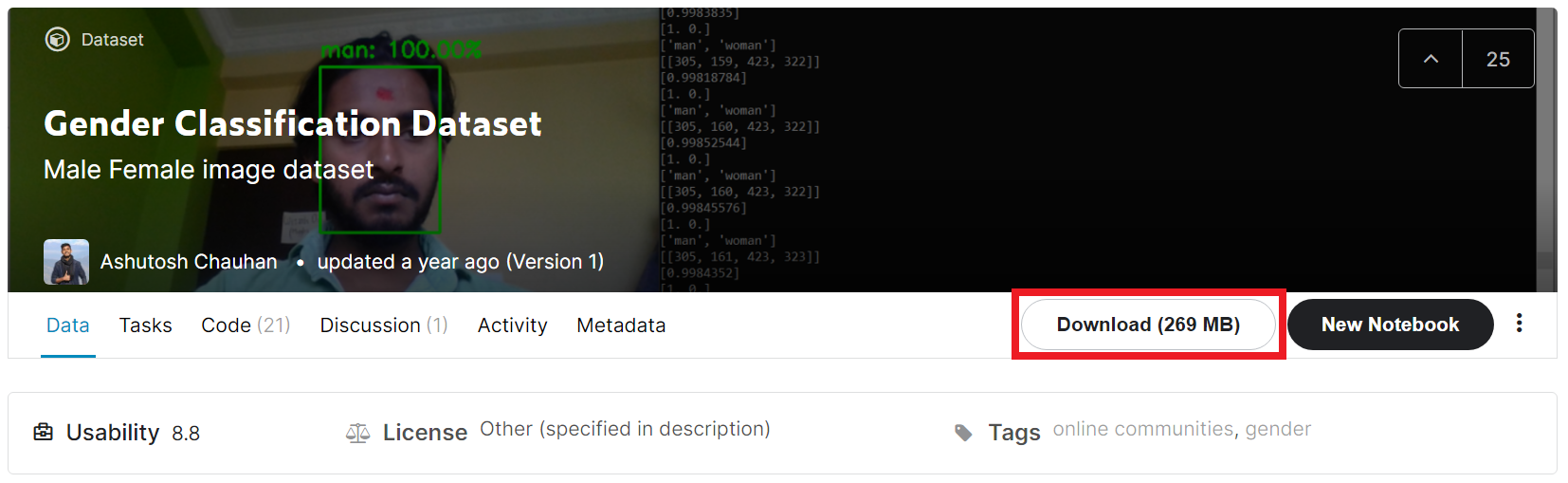
※ 얼굴 성별 분류 데이터셋: www.kaggle.com/cashutosh/gender-classification-dataset
Gender Classification Dataset
Male Female image dataset
www.kaggle.com
접속 이후에 [Download] 버튼을 눌러서 다운로드를 진행할 수 있다.
'기타' 카테고리의 다른 글
| Clarifai 이미지 인식 서비스 사용법 (Feat. 유명인 얼굴 인식 서비스) (1) | 2021.03.03 |
|---|---|
| 깃허브(GitHub)의 README 파일에 이미지/동영상 올리는 방법 (1) | 2021.03.01 |
| CelebA: 유명인(Celebrity) 얼굴 데이터셋(Face Dataset) 소개 (0) | 2021.02.27 |
| Cat and Dog 데이터셋 (강아지/고양이 분류 데이터셋) (0) | 2021.02.23 |
| PubFig 데이터셋과 PubFig83 데이터셋 설명 (0) | 2021.02.23 |
CelebA: 유명인(Celebrity) 얼굴 데이터셋(Face Dataset) 소개
CelebA 데이터셋은 대표적인 얼굴(face) 데이터셋이다. 이때 CelebA 데이터셋은 약 200,000개 정도의 얼굴 이미지로 구성된다. 기본적으로 10,000명가량의 사람이 포함되어 있다. 즉, 한 명당 20장 정도의 이미지가 있다고 보면 된다. 각 이미지는 178 x 218 해상도로 존재한다.
각 얼굴에 대해서는 40개의 이진 레이블(binary label)이 있다. 이때 각 얼굴에 대하여 다음과 같은 레이블이 각각 0 혹은 1의 값으로 붙어있다. 확인해 보면 젊은(young), 남성(male), 대머리(bald) 등의 예시가 붙어 있다.
예를 들어 데이터셋 중에서 000025.jpg 사진은 다음과 같다.

이 사진에 붙어 있는 레이블을 간단히 확인해 보면 다음과 같은 것을 알 수 있다.
대머리(Bale): -1, 큰 코(Big_Nose): 1, 남자(Male): 1, 웃는(Smiling): -1, 젊은(Young): 1
캐글(Kaggle) 사이트에 방문해서 다운로드할 수 있다.
▶ CelebA 데이터셋: www.kaggle.com/jessicali9530/celeba-dataset
CelebFaces Attributes (CelebA) Dataset
Over 200k images of celebrities with 40 binary attribute annotations
www.kaggle.com
사이트에 방문한 뒤에 [Download] 버튼을 누르면 다운로드할 수 있다.
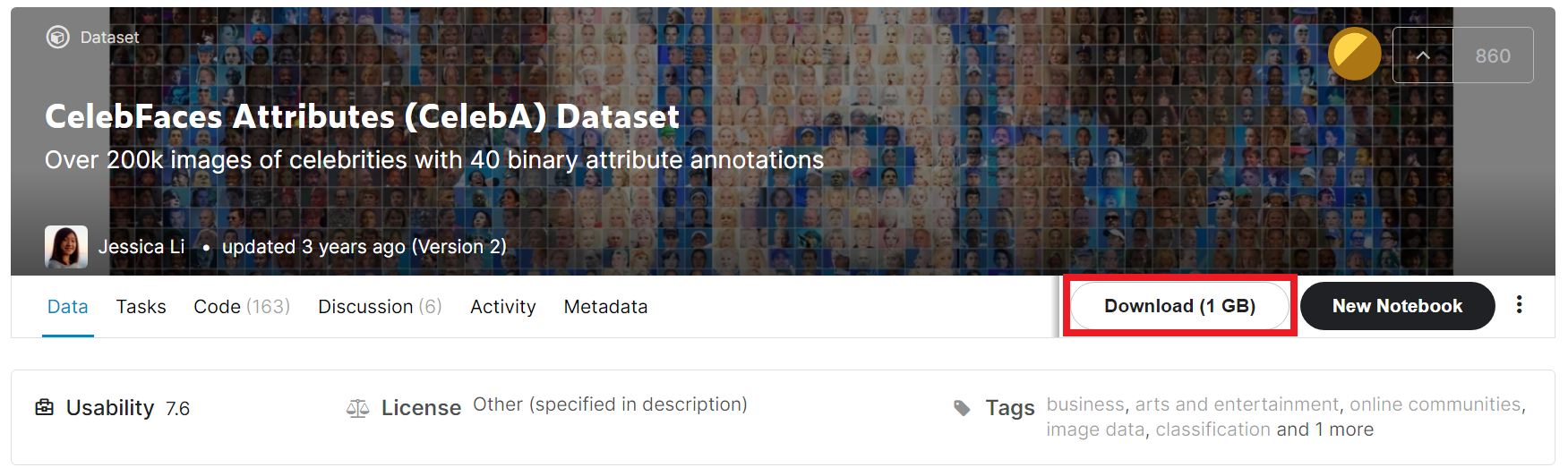
용량은 대략 1.4 GB 정도다.
'기타' 카테고리의 다른 글
| 깃허브(GitHub)의 README 파일에 이미지/동영상 올리는 방법 (1) | 2021.03.01 |
|---|---|
| 얼굴 성별 분류(Gender Classification) 데이터셋 소개 및 다운로드 방법 (0) | 2021.02.27 |
| Cat and Dog 데이터셋 (강아지/고양이 분류 데이터셋) (0) | 2021.02.23 |
| PubFig 데이터셋과 PubFig83 데이터셋 설명 (0) | 2021.02.23 |
| Raspberry Pi Zero W를 이용한 Custom Serial 데이터 전송 프로그램 (0) | 2021.02.22 |
Cat and Dog 데이터셋 (강아지/고양이 분류 데이터셋)
간단한 강아지/고양이 분류 데이터셋을 소개한다. 캐글(Kaggle)에 업로드된 데이터셋이며, 강아지와 고양이 사진이 한가득 존재한다. 이진 분류(binary classification) 작업을 수행하기에 적합하다.
학습 데이터와 테스트 데이터는 8:2로 적절하게 구분되어 있다.
1. 학습 데이터: 강아지 4,000장 / 고양이 4,000장
2. 테스트 데이터: 강아지 1,000장 / 고양이 1,000장
데이터는 다음의 경로에서 다운로드할 수 있다.
▶ Cat and Dog 데이터셋: www.kaggle.com/tongpython/cat-and-dog
Cat and Dog
Cats and Dogs dataset to train a DL model
www.kaggle.com
아래와 같이 [Download] 버튼을 눌러 다운로드하면 된다.
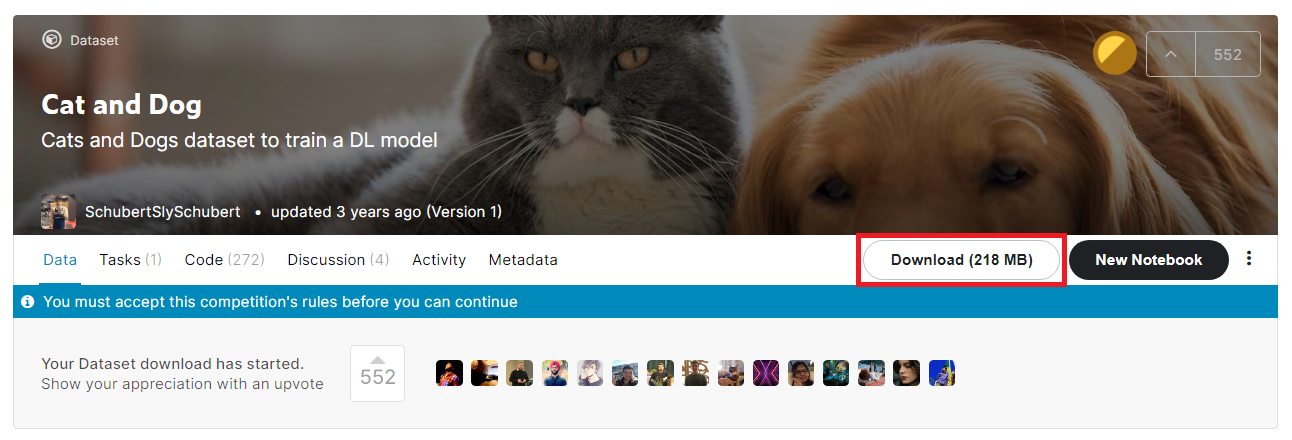
예를 들어 학습 데이터셋의 고양이 이미지는 다음과 같이 다양한 해상도와 종류로 존재하는 것을 알 수 있다.

'기타' 카테고리의 다른 글
| 얼굴 성별 분류(Gender Classification) 데이터셋 소개 및 다운로드 방법 (0) | 2021.02.27 |
|---|---|
| CelebA: 유명인(Celebrity) 얼굴 데이터셋(Face Dataset) 소개 (0) | 2021.02.27 |
| PubFig 데이터셋과 PubFig83 데이터셋 설명 (0) | 2021.02.23 |
| Raspberry Pi Zero W를 이용한 Custom Serial 데이터 전송 프로그램 (0) | 2021.02.22 |
| 키움증권 영웅문 4(HTS) - 주식 계좌 입금 및 출금 방법 (간단히 입출금하는 방법) (0) | 2021.02.22 |
PubFig 데이터셋과 PubFig83 데이터셋 설명
세계적으로 매우 많은 얼굴 데이터셋이 존재합니다. 오늘은 그중에서 PubFig라는 이름을 가지고 있는 두 개의 데이터셋을 소개하고자 합니다. 바로 PubFig와 PubFig83인데요. 재미있게도 이 두 개의 데이터셋은 이름은 같지만 서로 다른 데이터셋입니다.
1. PubFig (Public Figures Face Database)
PubFig 데이터셋은 200명에 대한 총 60,000개의 얼굴 이미지로 구성됩니다. 장면이나 포즈가 통제된(controlled) 상태가 아니고, 완전히 다양한 상황에서의 사진으로 구성되어 있습니다. 그런 측면에서 LFW (Labeled Faces in the Wild) 데이터셋과 유사합니다. 그래도 LFW에 비하면 사람당(클래스당) 이미지가 훨씬 많은 편입니다.
PubFig 데이터셋은 콜롬비아 대학교에서 배포하였으며, 다음의 경로에서 확인 가능합니다.
▶ 공식 사이트: www.cs.columbia.edu/CAVE/databases/pubfig/
Pubfig: Public Figures Face Database
Introduction The PubFig database is a large, real-world face dataset consisting of 58,797 images of 200 people collected from the internet. Unlike most other existing face datasets, these images are taken in completely uncontrolled situations with non-coop
www.cs.columbia.edu
이 데이터셋의 아쉬운 점은 URL 정보만 알려주고, 다운로드는 개발자가 직접하는 방식이라는 점입니다. 특히나 이미 시간이 오래 지나서 접근이 불가능한 이미지 경로가 많습니다. 다음과 같이 직접 URL에 접근해야 합니다.
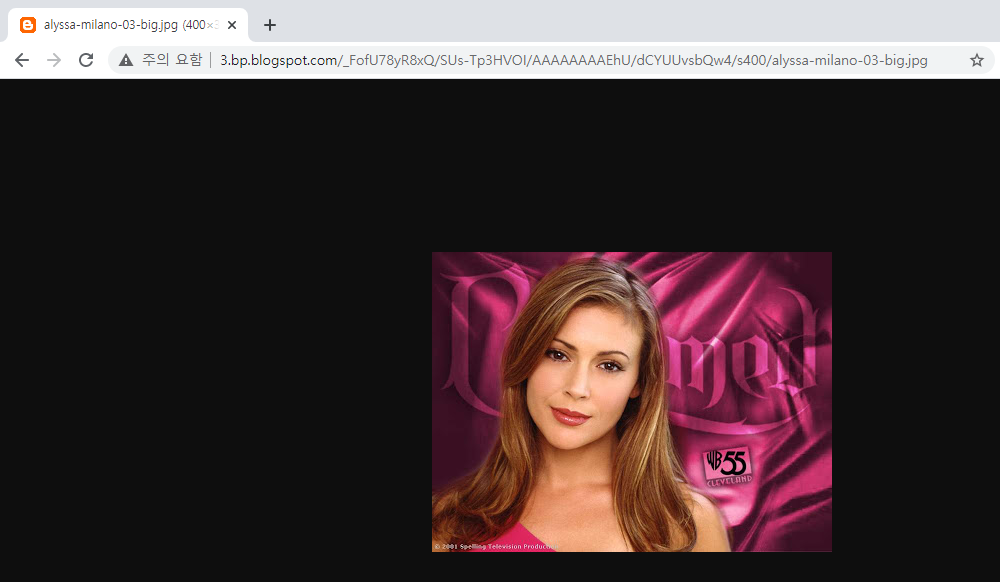
2. PubFig83 (A resource for studying face recognition in personal photo collections)
PubFig83 데이터셋은 83명에 대한 만 개가량의 이미지로 구성됩니다. 참고로 PugFig83 데이터셋에 등장하는 사람은 대체로 유명인(celebrity)입니다. 예를 들어 윌 스미스(Will Smith), 휴 잭맨(Hugh Jackman)과 같은 사람의 이미지가 들어 있습니다.
PubFig83 데이터셋은 하버드 대학교에서 배포하였으며, 다음의 경로에서 확인 가능합니다.
▶ 공식 사이트: vision.seas.harvard.edu/pubfig83/
PubFig83
PubFig83: A resource for studying face recognition in personal photo collections This is a downloadable dataset of 8300 cropped facial images, made up of 100 images for each of 83 public figures. It was derived from the list of URLs compiled by Neeraj K
vision.seas.harvard.edu
이미지 파일을 다운로드해서 열어 보니 100 x 100 크기로 잘라진(croppe) 이미지 파일 형태로 존재하네요.

'기타' 카테고리의 다른 글
| CelebA: 유명인(Celebrity) 얼굴 데이터셋(Face Dataset) 소개 (0) | 2021.02.27 |
|---|---|
| Cat and Dog 데이터셋 (강아지/고양이 분류 데이터셋) (0) | 2021.02.23 |
| Raspberry Pi Zero W를 이용한 Custom Serial 데이터 전송 프로그램 (0) | 2021.02.22 |
| 키움증권 영웅문 4(HTS) - 주식 계좌 입금 및 출금 방법 (간단히 입출금하는 방법) (0) | 2021.02.22 |
| File Storage Gadget (0) | 2021.02.22 |
Raspberry Pi Zero W를 이용한 Custom Serial 데이터 전송 프로그램
리눅스에서는 USB Gadget 목적으로 사용할 수 있는 usb_f_gser.ko 리눅스 커널 모듈을 제공한다. 이는 단순히 하나의 Bulk Transfer를 기반으로 하는 Interface를 생성할 수 있도록 해준다. 사실 일반적으로 Serial 통신을 사용다고 하면 CDC(Communication Device Class)를 이용하는데, 이러한 CDC는 ACM, OBEX 등 다양한 서브 클래스를 가진다. CDC는 시리얼 통신을 기반으로 동작하는데, 비단 Serial 뿐 아니라 Ethernet 등의 기능도 제공할 수 있도록 한다.
하지만 만약에 그냥 Raw Bulk Transfer를 이용하는 인터페이스를 이용하고자 한다면 기본적인 Serial Function인 usb_f_gser.ko를 이용하면 된다. 예를 들어 자신이 직접 USB 장치를 만들고, 필요하다면 호스트 쪽 드라이버를 직접 작성하고자 한다면 이것이 좋은 선택이 될 수 있다.
※ USB Configuration 파일 생성 ※
간단히 USB Configuration 파일을 생성해보자. 단순히 두 개의 Bulk Transfer를 정의한 상태이다. 필자는 /usr/bin/my_usb라는 경로에 해당 설정 파일을 만들었고, chmod 명령어로 실행 권한을 부여했다.
#!/bin/bash
cd /sys/kernel/config/usb_gadget/
mkdir -p my_usb
cd my_usb
# 기본적인 USB 클래스 명시
echo 0x1D6B > idVendor # Linux Foundation
echo 0x0104 > idProduct # Multifunction Composite Gadget
echo 0x0100 > bcdDevice # v1.0.0
echo 0x0200 > bcdUSB # USB 2.0
# 내가 만들 USB 장치의 기본적인 이름
mkdir -p strings/0x409
echo "0123456789abcdef" > strings/0x409/serialnumber
echo "Dongbin Na" > strings/0x409/manufacturer
echo "My USB" > strings/0x409/product
# 하나의 Configuration 정보 작성
mkdir -p configs/c.1/strings/0x409
echo "My USB Config 1" > configs/c.1/strings/0x409/configuration
echo 250 > configs/c.1/MaxPower
################# Bulk Transfer 1 #################
mkdir -p functions/gser.usb0
ln -s functions/gser.usb0 configs/c.1/
################# Bulk Transfer 2 #################
mkdir -p functions/gser.usb1
ln -s functions/gser.usb1 configs/c.1/
# UDC (Usb Device Controller)
ls /sys/class/udc > UDC
이후에 해당 환경 파일을 실행하면, Rapsberry Pi Zero W가 2개의 Bulk Transfer 통신 기능을 가지는 기기로 동작한다. 다만 CDC ACM과 같이 이미 잘 알려진 클래스를 사용하는 것이 아니기 때문에 다음과 같이 "드라이버를 찾을 수 없다"는 메시지가 출력되는 것을 확인할 수 있다.
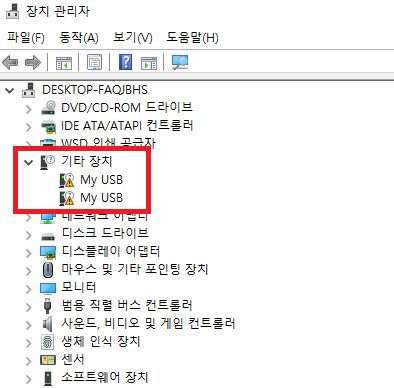
물론 이처럼 드라이버를 찾을 수 없다고 출력이 되더라도 USB Descriptor는 정상적으로 전달이 되기 때문에, 호스트(Host) PC 입장에서는 해당 Bulk Transfer의 엔드포인트(endpoint)에 접근할 수 있다. 실제로 USB Descriptor를 확인할 수 있는 프로그램을 사용하여 정보를 출력하면 다음과 같이 나온다. 이때 윈도우(Windows)의 Thesycon USB Descriptor Dumper를 사용하거나, 우분투(Ubuntu)의 lsusb 명령어를 사용할 수 있다.
확인 결과 2개의 인터페이스(Interface)가 존재하며, 필요한 최소한의 엔드포인트만을 가지고 있는 것을 알 수 있다. 참고로 CDC ACM과 같은 클래스는 단순히 Bulk Transfer만 가지고 있는 것이 아니며, 더 많은 기능을 포함하고 있어서 엔드포인트(endpoint)가 더 많이 붙어 있다. 아무튼 Interface Descriptor를 출력한 결과는 다음과 같다.
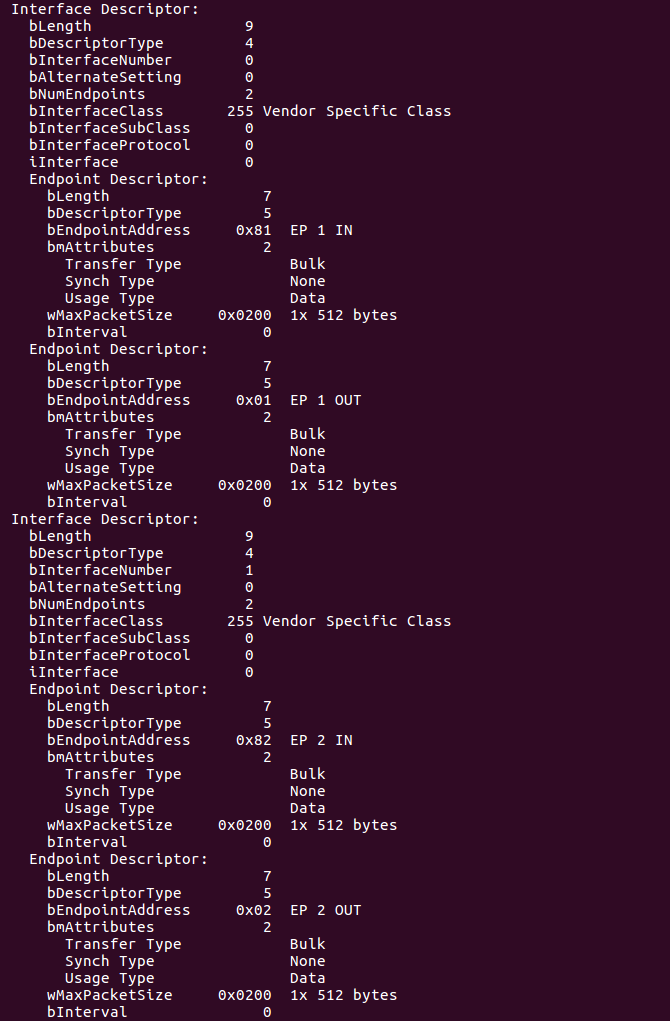
※ Device 프로그램 ※
Device 쪽 프로그램에서는 단순히 데이터를 읽어 올 때는 cat /dev/{장치명}을 하고, 데이터를 출력할 때는 echo를 이용해 /dev/{장치명}에 데이터를 쓰면 된다. 참고로 단순히 데이터를 보내게 되면 개행 문자가 자동으로 치환되어서 raw 데이터가 잘 안 보내질 수 있다. 따라서 다음의 명령어를 먼저 실행해준다.
sudo stty -F /dev/ttyGS1 raw
sudo stty -F /dev/ttyGS2 raw
매번 다음의 명령어를 실행해주지 않는다면, 호스트(Host) PC에서 개행문자를 포함할 때에만 정상적으로 데이터가 전송된다. 따라서 이를 참고하자.
'기타' 카테고리의 다른 글
| Cat and Dog 데이터셋 (강아지/고양이 분류 데이터셋) (0) | 2021.02.23 |
|---|---|
| PubFig 데이터셋과 PubFig83 데이터셋 설명 (0) | 2021.02.23 |
| 키움증권 영웅문 4(HTS) - 주식 계좌 입금 및 출금 방법 (간단히 입출금하는 방법) (0) | 2021.02.22 |
| File Storage Gadget (0) | 2021.02.22 |
| '암호화용 인증서의 비밀번호가 다릅니다.' 오류 (0) | 2021.02.22 |
키움증권 영웅문 4(HTS) - 주식 계좌 입금 및 출금 방법 (간단히 입출금하는 방법)
※ 나의 주식 계좌 확인하는 방법 ※
영웅문 HTS를 실행한 뒤에, [주식주문] - [주식종합] 페이지로 이동하면 나의 주식 계좌 목록을 확인할 수 있다. 일반적인 [위탁종합] 계좌인 경우 8자리 계좌번호로 XXXX-XXXX로 구성된다.
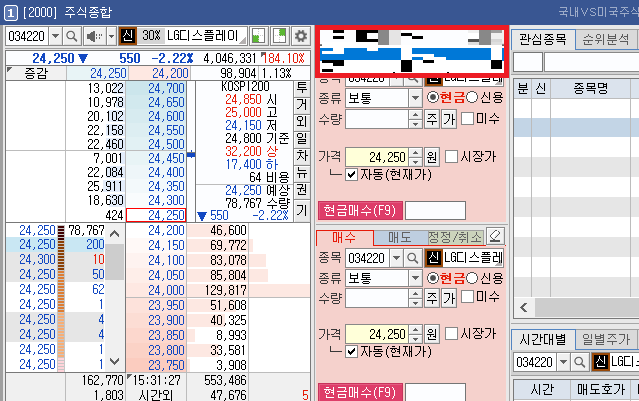
※ 주식 계좌에 돈 입금하는 방법 ※
키움증권 주식 계좌를 만든 뒤에, 해당 주식 계좌 번호로 돈을 입금하면, 주식 투자를 할 수 있게 된다. 그냥 키움증권 계좌번호로 입금하면 된다. 정확히는 일반적으로 은행 앱에서 키움증권으로 입금할 때는 [증권사] - [키움증권]을 선택한 뒤에 자신의 주식 계좌로 돈을 입금하면 된다. 필자의 경우 NH은행 앱을 이용해 입금했다. 입금을 완료한 뒤에는 영웅문HTS 프로그램에서 [주식주문] - [계좌정보] - [실시간 잔고] 창을 열어 정상적으로 예수금이 입금되었는지 확인할 수 있다.
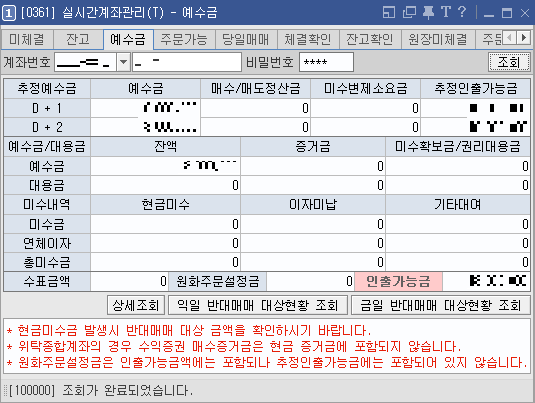
※ 주식 계좌에서 돈 출금하는 방법 ※
개인적으로 영웅문 프로그램은 기능이 너무 많아서 헷갈린다. 주식계좌에 있는 돈을 출금하고 싶은데, 출금 기능을 찾지 못해서 헤맸다. 자신의 주식계좌에 있는 돈을 꺼내고 싶다면 [온라인업무] - [인터넷뱅킹] - [즉시이체출금]으로 들어가면 된다.
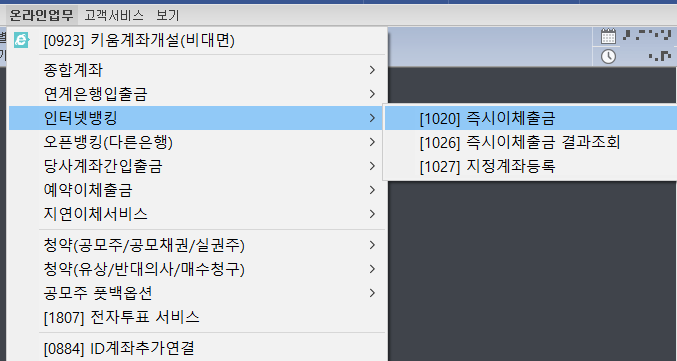
이후에 받을 계좌번호를 입력하고 [이체실행]을 눌러 이체를 진행하면 된다.
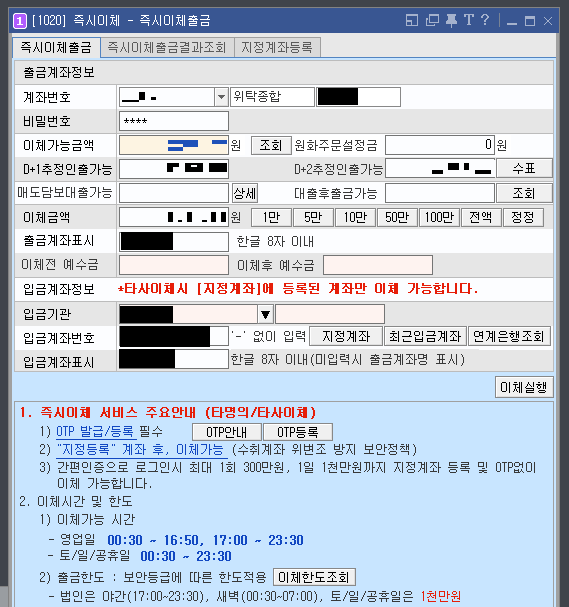
(참고) 필자의 경우 딱히 OTP가 필요하거나 그렇지 않았다. [이체실행] 버튼을 누르면 다음과 같이 이체 확인 페이지가 등장하는데, [확인] 버튼을 눌러서 이체를 진행하면 된다.

이후에 다음과 같이 인증서 비밀번호를 입력하면 이체가 완료된다.
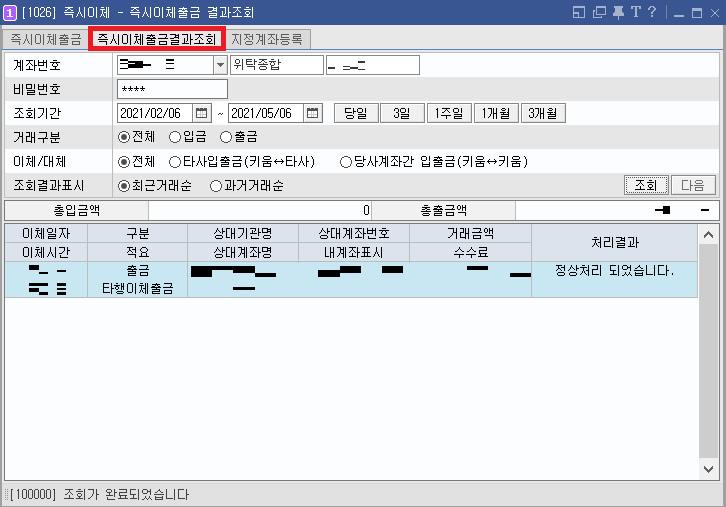
나중에 출금 결과를 조회하고 싶다면 [온라인업무] - [인터넷뱅킹] - [즉시이체출금결과조회]로 들어가면 된다. 여기에서 비밀번호 및 적절한 조회기간을 입력하면 다음과 같이 언제, 어디로, 얼마를 출금했는지 확인할 수 있다. 기본적으로 늦은 저녁에도(정해진 특정 시간대를 제외하고) 출금(이체)이 가능하기 때문에, 사실상 원할 때 출금할 수 있다.
'기타' 카테고리의 다른 글
| PubFig 데이터셋과 PubFig83 데이터셋 설명 (0) | 2021.02.23 |
|---|---|
| Raspberry Pi Zero W를 이용한 Custom Serial 데이터 전송 프로그램 (0) | 2021.02.22 |
| File Storage Gadget (0) | 2021.02.22 |
| '암호화용 인증서의 비밀번호가 다릅니다.' 오류 (0) | 2021.02.22 |
| 유튜버 정보(채널 요약, 광고 단가 등) 소개 사이트 (0) | 2021.02.13 |
File Storage Gadget
FSG란 File Storage Gadget의 약자이다. 리눅스(Linux) 기반 장치에서 Mass Storage Gadget(MSG) 클래스의 기능을 제공하기 위해 FSG를 사용할 수 있다. 자세한 내용은 커널 공식 문서를 참고할 수 있다. 기본적으로 FSG는 USB 스펙에서 bulk-in과 bulk-out 엔드포인트를 필요로 하고, 별도의 블록 장치(block device)를 만든 뒤에 이를 특정한 LUN에 적용하여 사용할 수 있다. 이때 LUN(Logical Unit Number)이란 각각의 논리 장치(저장 장치)를 식별하기 위해 사용하는 번호를 의미한다.
기본적으로 Mass Storage Gadget의 구현은 커널의 drivers/usb/gadget/function/f_mass_storage.c에서 확인할 수 있다. (참고: elixir.bootlin.com/linux/latest/source/drivers/usb/gadget/function/f_mass_storage.c) 참고로 여기에서 커널 모듈을 불러오기 위한 파라미터는 fsg_config_from_params 함수 내부에서 확인할 수 있다.
하나의 FSG는 여러 개의 LUN을 가질 수 있으며, 하나의 LUN은 다음과 같이 정의된다.
struct fsg_lun_config {
const char *filename;
char ro;
char removable;
char cdrom;
char nofua;
char inquiry_string[INQUIRY_STRING_LEN];
};'기타' 카테고리의 다른 글
| Raspberry Pi Zero W를 이용한 Custom Serial 데이터 전송 프로그램 (0) | 2021.02.22 |
|---|---|
| 키움증권 영웅문 4(HTS) - 주식 계좌 입금 및 출금 방법 (간단히 입출금하는 방법) (0) | 2021.02.22 |
| '암호화용 인증서의 비밀번호가 다릅니다.' 오류 (0) | 2021.02.22 |
| 유튜버 정보(채널 요약, 광고 단가 등) 소개 사이트 (0) | 2021.02.13 |
| 지금 유튜브 동영상에서 나오고 있는 음악을 찾고 싶을 때 사용할 수 있는 크롬 확장 프로그램 소개 (0) | 2021.02.13 |
'암호화용 인증서의 비밀번호가 다릅니다.' 오류
최근에 스마트폰에 있던 인증서를 PC로 옮겼다. 이때 농협 인터넷 뱅킹을 이용하여 스마트폰의 인증서를 PC로 옮겼다. 이후에 농협 인터넷 뱅킹에서는 공인인증서(공동인증서)를 정상적으로 사용할 수 있었다. 하지만 동일하게 PC에 저장된 인증서를 우체국 인터넷 뱅킹에서 사용하려고 할 때 다음과 같은 오류 메시지가 등장했다.
'암호화용 인증서의 비밀번호가 다릅니다. 복구하시려면 재발급이 필요합니다.'

정확한 원인은 알 수 없으나 직접적으로 우체국 뱅킹에서 [인증서 가져오기] 기능을 사용하지 않았기 때문에 그런 것 같다. 하지만 재미있게도 그냥 [확인] 버튼을 눌러서 계속 진행하도록 만들면 정상적으로 로그인되었다.
'기타' 카테고리의 다른 글
| 키움증권 영웅문 4(HTS) - 주식 계좌 입금 및 출금 방법 (간단히 입출금하는 방법) (0) | 2021.02.22 |
|---|---|
| File Storage Gadget (0) | 2021.02.22 |
| 유튜버 정보(채널 요약, 광고 단가 등) 소개 사이트 (0) | 2021.02.13 |
| 지금 유튜브 동영상에서 나오고 있는 음악을 찾고 싶을 때 사용할 수 있는 크롬 확장 프로그램 소개 (0) | 2021.02.13 |
| MIRFLICKR 이미지 데이터셋 소개 (0) | 2021.02.10 |
