Convolution 연산을 Python NumPy로 구현해보자! (단순 반복문을 이용한 구현, im2col을 이용한 구현)
Convolution 연산은 CNN을 포함한 다양한 딥러닝 네트워크에서 활용되는 중요한 연산이다. PyTorch와 같은 딥러닝 프레임워크에서는 Convolution 연산을 기본적으로 제공하고 있다. 이러한 Convolution 연산에 대해 더욱 자세히 이해하기 위하여 본 포스팅에서는 Convolution 연산을 Python NumPy만을 이용해 구현해보도록 하겠다.
예를 들어 입력 차원이 (배치 크기, 채널 크기, 높이, 너비) = (2, 3, 5, 5)인 예시를 확인해 보자. 이때 3 X 3짜리 커널을 3개 사용하여 stride = 2, padding = 0 설정으로 Convolution 연산을 수행하면 그 결과는 다음과 같다. 수식으로 표현하자면 출력 차원은 (배치 크기, 커널 개수, out_h, out_w) = (2, 3, 2, 2)가 된다.

※ 단순 반복문을 이용한 구현 ※
이러한 Convolution 연산을 어떻게 구현할 수 있을까? 가장 기본적인 방법은 바로 반복문을 이용하는 것이다. 기본적으로 출력 높이(out_h)와 출력 너비(out_w)는 다음의 공식을 이용해 구현할 수 있다.
out_h = (h + 2 * padding - filter_h) / stride + 1
out_w = (w + 2 * padding - filter_w) / stride + 1
또한, 일반적으로 패딩(padding)은 입력 데이터의 높이와 너비 차원에 대해서만 수행한다. 이를 위해 np.pad() 메서드를 사용할 수 있다. 아래 코드를 보면 높이와 너비 차원에 대해서만 패딩을 넣는 것을 알 수 있다.
결과적으로 출력 텐서(out)를 만든 뒤에 각각의 원소마다 Convolution 연산을 수행한 결과 값을 채워 넣는 것을 알 수 있다. NumPy에서 단순히 두 행렬에 대하여 곱셈 연산을 수행하면, 원소 단위(element-wise)로 곱셈 연산이 수행된다. 그래서 Convolution 연산을 다음과 같이 구현할 수 있다.
import numpy as np
def conv(X, filters, stride=1, pad=0):
n, c, h, w = X.shape
n_f, _, filter_h, filter_w = filters.shape
out_h = (h + 2 * pad - filter_h) // stride + 1
out_w = (w + 2 * pad - filter_w) // stride + 1
# add padding to height and width.
in_X = np.pad(X, [(0, 0), (0, 0), (pad, pad), (pad, pad)], 'constant')
out = np.zeros((n, n_f, out_h, out_w))
for i in range(n): # for each image.
for c in range(n_f): # for each channel.
for h in range(out_h): # slide the filter vertically.
h_start = h * stride
h_end = h_start + filter_h
for w in range(out_w): # slide the filter horizontally.
w_start = w * stride
w_end = w_start + filter_w
# Element-wise multiplication.
out[i, c, h, w] = np.sum(in_X[i, :, h_start:h_end, w_start:w_end] * filters[c])
return out
이제 앞서 다루었던 그림을 그대로 코드로 옮겨 결과를 확인해 보자.
X = np.asarray([
# image 1
[
[[1, 2, 9, 2, 7],
[5, 0, 3, 1, 8],
[4, 1, 3, 0, 6],
[2, 5, 2, 9, 5],
[6, 5, 1, 3, 2]],
[[4, 5, 7, 0, 8],
[5, 8, 5, 3, 5],
[4, 2, 1, 6, 5],
[7, 3, 2, 1, 0],
[6, 1, 2, 2, 6]],
[[3, 7, 4, 5, 0],
[5, 4, 6, 8, 9],
[6, 1, 9, 1, 6],
[9, 3, 0, 2, 4],
[1, 2, 5, 5, 2]]
],
# image 2
[
[[7, 2, 1, 4, 2],
[5, 4, 6, 5, 0],
[1, 2, 4, 2, 8],
[5, 9, 0, 5, 1],
[7, 6, 2, 4, 6]],
[[5, 4, 2, 5, 7],
[6, 1, 4, 0, 5],
[8, 9, 4, 7, 6],
[4, 5, 5, 6, 7],
[1, 2, 7, 4, 1]],
[[7, 4, 8, 9, 7],
[5, 5, 8, 1, 4],
[3, 2, 2, 5, 2],
[1, 0, 3, 7, 6],
[4, 5, 4, 5, 5]]
]
])
print('Images:', X.shape)
filters = np.asarray([
# kernel 1
[
[[1, 0, 1],
[0, 1, 0],
[1, 0, 1]],
[[3, 1, 3],
[1, 3, 1],
[3, 1, 3]],
[[1, 2, 1],
[2, 2, 2],
[1, 2, 1]]
],
# kernel 2
[
[[5, 1, 5],
[2, 1, 2],
[5, 1, 5]],
[[1, 1, 1],
[1, 1, 1],
[1, 1, 1]],
[[2, 0, 2],
[0, 2, 0],
[2, 0, 2]],
],
# kernel 3
[
[[5, 1, 5],
[2, 1, 2],
[5, 1, 5]],
[[1, 1, 1],
[1, 1, 1],
[1, 1, 1]],
[[2, 0, 2],
[0, 2, 0],
[2, 0, 2]],
]
])
print('Filters:', filters.shape)
out = conv(X, filters, stride=2, pad=0)
print('Output:', out.shape)
print(out)
실행 결과는 다음과 같다. 그림에서의 결과와 동일한 것을 확인할 수 있다.
Images: (2, 3, 5, 5)
Filters: (3, 3, 3, 3)
Output: (2, 3, 2, 2)
[[[[174. 191.]
[130. 122.]]
[[197. 244.]
[165. 159.]]
[[197. 244.]
[165. 159.]]]
[[[168. 171.]
[153. 185.]]
[[188. 178.]
[168. 200.]]
[[188. 178.]
[168. 200.]]]]
※ im2col을 이용한 구현 ※
앞서 단순 반복문을 이용해 Convolution 연산을 구현해 보았다. Convolution 연산을 수행할 때 단순히 반복문(for loops)을 이용하는 경우, 행렬 곱을 제대로 활용하지 못한다는 점에서 속도가 느리다. 따라서 메모리를 조금 더 많이 사용하여, 속도를 비약적으로 개선할 수 있는 방법으로 im2col 연산을 활용하는 방법이 있다.
다음과 같이 한 배치에 두 장의 이미지가 존재하여 마찬가지로 입력 차원이 (배치 크기, 채널 크기, 높이, 너비) = (2, 3, 5, 5)인 예시를 확인해 보자. 이러한 입력이 들어왔을 때, 이것을 행렬(matrix)로 형태를 변형하는 것이 im2col 연산이다. im2col 연산을 수행한 결과를 확인해 보자. (8, 27) 차원을 갖는 행렬이 생성되었다. 정확히는 (이미지 개수 X out_h X out_w, 입력 채널 개수 X kernel_h X kernel_w)의 차원을 갖는 행렬이 된다.

im2col 연산은 다음과 같이 구현할 수 있다.
import numpy as np
def im2col(X, filters, stride=1, pad=0):
n, c, h, w = X.shape
n_f, _, filter_h, filter_w = filters.shape
out_h = (h + 2 * pad - filter_h) // stride + 1
out_w = (w + 2 * pad - filter_w) // stride + 1
# add padding to height and width.
in_X = np.pad(X, [(0, 0), (0, 0), (pad, pad), (pad, pad)], 'constant')
out = np.zeros((n, c, filter_h, filter_w, out_h, out_w))
for h in range(filter_h):
h_end = h + stride * out_h
for w in range(filter_w):
w_end = w + stride * out_w
out[:, :, h, w, :, :] = in_X[:, :, h:h_end:stride, w:w_end:stride]
out = out.transpose(0, 4, 5, 1, 2, 3).reshape(n * out_h * out_w, -1)
return out
X = np.asarray([
# image 1
[
[[1, 2, 9, 2, 7],
[5, 0, 3, 1, 8],
[4, 1, 3, 0, 6],
[2, 5, 2, 9, 5],
[6, 5, 1, 3, 2]],
[[4, 5, 7, 0, 8],
[5, 8, 5, 3, 5],
[4, 2, 1, 6, 5],
[7, 3, 2, 1, 0],
[6, 1, 2, 2, 6]],
[[3, 7, 4, 5, 0],
[5, 4, 6, 8, 9],
[6, 1, 9, 1, 6],
[9, 3, 0, 2, 4],
[1, 2, 5, 5, 2]]
],
# image 2
[
[[7, 2, 1, 4, 2],
[5, 4, 6, 5, 0],
[1, 2, 4, 2, 8],
[5, 9, 0, 5, 1],
[7, 6, 2, 4, 6]],
[[5, 4, 2, 5, 7],
[6, 1, 4, 0, 5],
[8, 9, 4, 7, 6],
[4, 5, 5, 6, 7],
[1, 2, 7, 4, 1]],
[[7, 4, 8, 9, 7],
[5, 5, 8, 1, 4],
[3, 2, 2, 5, 2],
[1, 0, 3, 7, 6],
[4, 5, 4, 5, 5]]
]
])
print('Images:', X.shape)
filters = np.asarray([
# kernel 1
[
[[1, 0, 1],
[0, 1, 0],
[1, 0, 1]],
[[3, 1, 3],
[1, 3, 1],
[3, 1, 3]],
[[1, 2, 1],
[2, 2, 2],
[1, 2, 1]]
],
# kernel 2
[
[[5, 1, 5],
[2, 1, 2],
[5, 1, 5]],
[[1, 1, 1],
[1, 1, 1],
[1, 1, 1]],
[[2, 0, 2],
[0, 2, 0],
[2, 0, 2]],
],
# kernel 3
[
[[5, 1, 5],
[2, 1, 2],
[5, 1, 5]],
[[1, 1, 1],
[1, 1, 1],
[1, 1, 1]],
[[2, 0, 2],
[0, 2, 0],
[2, 0, 2]],
]
])
print('Filters:', filters.shape)
out = im2col(X, filters, stride=2, pad=0)
print('Output:', out.shape)
print(out)
im2col 연산 예제 실행 결과는 다음과 같다.
Images: (2, 3, 5, 5)
Filters: (3, 3, 3, 3)
Output: (8, 27)
[[1. 2. 9. 5. 0. 3. 4. 1. 3. 4. 5. 7. 5. 8. 5. 4. 2. 1. 3. 7. 4. 5. 4. 6.
6. 1. 9.]
[9. 2. 7. 3. 1. 8. 3. 0. 6. 7. 0. 8. 5. 3. 5. 1. 6. 5. 4. 5. 0. 6. 8. 9.
9. 1. 6.]
[4. 1. 3. 2. 5. 2. 6. 5. 1. 4. 2. 1. 7. 3. 2. 6. 1. 2. 6. 1. 9. 9. 3. 0.
1. 2. 5.]
[3. 0. 6. 2. 9. 5. 1. 3. 2. 1. 6. 5. 2. 1. 0. 2. 2. 6. 9. 1. 6. 0. 2. 4.
5. 5. 2.]
[7. 2. 1. 5. 4. 6. 1. 2. 4. 5. 4. 2. 6. 1. 4. 8. 9. 4. 7. 4. 8. 5. 5. 8.
3. 2. 2.]
[1. 4. 2. 6. 5. 0. 4. 2. 8. 2. 5. 7. 4. 0. 5. 4. 7. 6. 8. 9. 7. 8. 1. 4.
2. 5. 2.]
[1. 2. 4. 5. 9. 0. 7. 6. 2. 8. 9. 4. 4. 5. 5. 1. 2. 7. 3. 2. 2. 1. 0. 3.
4. 5. 4.]
[4. 2. 8. 0. 5. 1. 2. 4. 6. 4. 7. 6. 5. 6. 7. 7. 4. 1. 2. 5. 2. 3. 7. 6.
4. 5. 5.]]
이렇게 구해진 im2col 결과 행렬(matrix)과 연산하기 위해 다음과 같이 커널(kernel) 또한 flatten을 진행하면 된다. 결과적으로 두 행렬(matrix)에 대하여 행렬 곱(matrix multiplication)을 수행하여 결과를 구할 수 있다.

따라서 최종적인 코드는 다음과 같다.
import numpy as np
def im2col(X, filters, stride=1, pad=0):
n, c, h, w = X.shape
n_f, _, filter_h, filter_w = filters.shape
out_h = (h + 2 * pad - filter_h) // stride + 1
out_w = (w + 2 * pad - filter_w) // stride + 1
# add padding to height and width.
in_X = np.pad(X, [(0, 0), (0, 0), (pad, pad), (pad, pad)], 'constant')
out = np.zeros((n, c, filter_h, filter_w, out_h, out_w))
for h in range(filter_h):
h_end = h + stride * out_h
for w in range(filter_w):
w_end = w + stride * out_w
out[:, :, h, w, :, :] = in_X[:, :, h:h_end:stride, w:w_end:stride]
out = out.transpose(0, 4, 5, 1, 2, 3).reshape(n * out_h * out_w, -1)
return out
X = np.asarray([
# image 1
[
[[1, 2, 9, 2, 7],
[5, 0, 3, 1, 8],
[4, 1, 3, 0, 6],
[2, 5, 2, 9, 5],
[6, 5, 1, 3, 2]],
[[4, 5, 7, 0, 8],
[5, 8, 5, 3, 5],
[4, 2, 1, 6, 5],
[7, 3, 2, 1, 0],
[6, 1, 2, 2, 6]],
[[3, 7, 4, 5, 0],
[5, 4, 6, 8, 9],
[6, 1, 9, 1, 6],
[9, 3, 0, 2, 4],
[1, 2, 5, 5, 2]]
],
# image 2
[
[[7, 2, 1, 4, 2],
[5, 4, 6, 5, 0],
[1, 2, 4, 2, 8],
[5, 9, 0, 5, 1],
[7, 6, 2, 4, 6]],
[[5, 4, 2, 5, 7],
[6, 1, 4, 0, 5],
[8, 9, 4, 7, 6],
[4, 5, 5, 6, 7],
[1, 2, 7, 4, 1]],
[[7, 4, 8, 9, 7],
[5, 5, 8, 1, 4],
[3, 2, 2, 5, 2],
[1, 0, 3, 7, 6],
[4, 5, 4, 5, 5]]
]
])
print('Images:', X.shape)
filters = np.asarray([
# kernel 1
[
[[1, 0, 1],
[0, 1, 0],
[1, 0, 1]],
[[3, 1, 3],
[1, 3, 1],
[3, 1, 3]],
[[1, 2, 1],
[2, 2, 2],
[1, 2, 1]]
],
# kernel 2
[
[[5, 1, 5],
[2, 1, 2],
[5, 1, 5]],
[[1, 1, 1],
[1, 1, 1],
[1, 1, 1]],
[[2, 0, 2],
[0, 2, 0],
[2, 0, 2]],
],
# kernel 3
[
[[5, 1, 5],
[2, 1, 2],
[5, 1, 5]],
[[1, 1, 1],
[1, 1, 1],
[1, 1, 1]],
[[2, 0, 2],
[0, 2, 0],
[2, 0, 2]],
]
])
print('Filters:', filters.shape)
stride = 2
pad = 0
X_col = im2col(X, filters, stride=stride, pad=pad)
n, c, h, w = X.shape
n_f, _, filter_h, filter_w = filters.shape
out_h = (h + 2 * pad - filter_h) // stride + 1
out_w = (w + 2 * pad - filter_w) // stride + 1
out = np.matmul(X_col, filters.reshape(n_f, -1).T)
out = out.reshape(n, out_h, out_w, n_f)
out = out.transpose(0, 3, 1, 2)
print('Output:', out.shape)
print(out)
실행 결과는 다음과 같으며, 앞서 반복문을 이용한 구현 결과와 동일하다.
Images: (2, 3, 5, 5)
Filters: (3, 3, 3, 3)
Output: (2, 3, 2, 2)
[[[[174. 191.]
[130. 122.]]
[[197. 244.]
[165. 159.]]
[[197. 244.]
[165. 159.]]]
[[[168. 171.]
[153. 185.]]
[[188. 178.]
[168. 200.]]
[[188. 178.]
[168. 200.]]]]'기타' 카테고리의 다른 글
| 크롬(Chrome) 브라우저 시크릿 모드 사용 방법 (+ 간단한 원리 설명) (0) | 2021.08.28 |
|---|---|
| 인터넷 속도(다운로드, 업로드, Ping) 간단 측정 방법! Feat. NIA 사이트 (0) | 2021.08.27 |
| 윈도우(Windows) 10에서 기본 브라우저 변경하는 방법 (0) | 2021.08.27 |
| Rufus를 이용해 윈도우 10 OS 이미지를 USB에 굽는 방법 (0) | 2021.08.26 |
| 텍스트를 음성(오디오)으로 바꾸어 주는 TTS 프로그램 발라볼카(Balabolka) 소개 (0) | 2021.08.26 |
크롬(Chrome) 브라우저 시크릿 모드 사용 방법 (+ 간단한 원리 설명)
구글 크롬(Chrome) 브라우저는 시크릿 모드를 제공합니다. 필자는 공용 PC를 사용하거나, 집에서 컴퓨터를 할 때에도 PC에 방문 기록을 남기지 않고자 할 때는 시크릿 모드를 사용합니다. 시크릿 모드는 크롬(Chrome) 브라우저를 실행한 뒤에 [새 시크릿 창] 버튼을 클릭하거나 [Ctrl + Shift + N]을 눌러서 간단하게 열 수 있습니다.

시크릿 모드가 실행되면 다음과 같은 화면이 등장합니다. 스크릿 모드를 이용하면 방문 기록, 쿠키 및 사이트 데이터, 양식에 입력한 정보가 저장되지 않습니다. 다시 말해 이러한 정보가 현재 사용하고 있는 기기(컴퓨터)에 저장되지 않습니다. 그래서 나중에 내 컴퓨터를 다른 사람이 사용하더라도, 내가 어디에 접속했는지 알 수 없는 것입니다. (참고로 일반적인 경우에 자기 자신도 자기가 어디에 접속했었는지 알 수 없습니다. 머릿속으로 기억하고 있으면 좋지만, 기록상으로는 남기 때문에, 가끔 기억이 안 나서 낭패를 보는 일이 생깁니다.)
아무튼 시크릿 모드는 굉장히 유용합니다. 예를 들어 필자가 누나의 생일 선물을 사주려고 인터넷에 검색할 때 시크릿 모드를 사용하게 되면, 같은 컴퓨터를 사용하는 누나가 검색 기록을 알지 못하게 되는 것입니다. 다만, 시크릿 모드를 사용하더라도 파일을 다운로드하거나 북마크를 추가했다면 이러한 정보는 저장되므로, 시크릿 모드일 때 다운로드한 파일이 기록된다는 점을 기억하세요.

※ 참고사항 ※
참고로 시크릿 모드는 [닫은 탭 다시 열기] 기능을 제공하지 않습니다. 따라서 실수로 탭을 닫았을 때 혹은 이전에 방문했던 웹 페이지에 다시 방문하고 싶을 때, 기록이 남아 있지 않아서 낭패를 보는 경우가 발생할 수 있습니다. 그래서 시크릿 모드로 웹 페이지를 방문하다가, 좋은 정보가 포함된 웹 페이지를 찾았다면 그 링크는 별도로 기록할 필요가 있습니다.
또한 내 컴퓨터에 정보가 남지 않는 것이지, 실제로 웹 사이트에 접속했을 때, 웹 사이트의 관리자는 여러분의 방문 기록을 알 수 있습니다. 예를 들어 우리가 네이버(Naver)에 접속해 특정한 웹 페이지에 접속했다고 가정해 봅시다. 그러면 여러분의 컴퓨터에서 보내는 패킷은 네이버 서버에 도달하게 됩니다. 당연히 네이버 입장에서는 여러분의 IP나 패킷 정보를 처리하게 될 것입니다. 그렇기에 웹 사이트 관리자, 인터넷 서비스 제공업체(ISP), 네트워크 관리자의 입장에서는 방문 기록을 확인할 가능성이 있다고 보시면 됩니다.
그래서 여러분의 IP 정보를 포함해 완전히 여러분의 신원을 숨기고 싶다면, 시크릿 모드를 넘어서 VPN을 이용해 보시면 좋습니다. 물론 VPN을 이용한다고 하더라도, 여러분이 특정 웹 사이트에 로그인을 하는 등으로 정보를 노출한다면, 이 또한 활동 내역이 남게 될 여지가 있다는 점에 유의하세요. 실제로 웹 사이트 관리자 입장에서는 접속자가 로그인을 했을 때에만 중요한 정보를 노출하도록 하여, 어떤 사람이 어떤 기능을 이용했는지 처리하는 경우가 많습니다.
'기타' 카테고리의 다른 글
| Convolution 연산을 Python NumPy로 구현해보자! (단순 반복문을 이용한 구현, im2col을 이용한 구현) (0) | 2021.08.28 |
|---|---|
| 인터넷 속도(다운로드, 업로드, Ping) 간단 측정 방법! Feat. NIA 사이트 (0) | 2021.08.27 |
| 윈도우(Windows) 10에서 기본 브라우저 변경하는 방법 (0) | 2021.08.27 |
| Rufus를 이용해 윈도우 10 OS 이미지를 USB에 굽는 방법 (0) | 2021.08.26 |
| 텍스트를 음성(오디오)으로 바꾸어 주는 TTS 프로그램 발라볼카(Balabolka) 소개 (0) | 2021.08.26 |
인터넷 속도(다운로드, 업로드, Ping) 간단 측정 방법! Feat. NIA 사이트
다양한 이유로 인터넷 속도를 측정해야 할 때가 있다. 예를 들어 인터넷 방송을 하고 싶다면, 업로드 속도가 특정 속도 이상이 나와야 한다. 따라서 자신의 인터넷 속도를 측정하는 방법에 대해 알고 있으면 좋다. 이때 간단하게 사용할 수 있는 서비스로는 NIA에서 제공하는 [인터넷 속도 측정] 서비스가 있다. 아주 간단하게 사용해 볼 수 있다.
▶ NIA 인터넷 속도 측정: https://speed.nia.or.kr/index.asp
한국정보화진흥원 - 인터넷 품질측정 시스템
speed.nia.or.kr
웹 사이트에 접속한 뒤에는 필요한 프로그램을 다운로드한다.

이후에 다음과 같이 기본 설정 그대로 설치를 진행하면 된다.

필자의 경우 전체 설치 과정이 약 1분 내외의 시간을 요구했다.



결과적으로 다음과 같이 측정을 진행할 수 있다. 필자의 경우 SK의 기가 라이트(500Mbps) 인터넷 서비스를 사용하고 있다. 따라서 해당 정보를 기입한 뒤에 [측정하기] 버튼을 눌렀다.

결과적으로 다음과 같이 다운로드/업로드 속도 각각 500Mbps 정도의 속도가 나오는 것을 알 수 있다.

'기타' 카테고리의 다른 글
| Convolution 연산을 Python NumPy로 구현해보자! (단순 반복문을 이용한 구현, im2col을 이용한 구현) (0) | 2021.08.28 |
|---|---|
| 크롬(Chrome) 브라우저 시크릿 모드 사용 방법 (+ 간단한 원리 설명) (0) | 2021.08.28 |
| 윈도우(Windows) 10에서 기본 브라우저 변경하는 방법 (0) | 2021.08.27 |
| Rufus를 이용해 윈도우 10 OS 이미지를 USB에 굽는 방법 (0) | 2021.08.26 |
| 텍스트를 음성(오디오)으로 바꾸어 주는 TTS 프로그램 발라볼카(Balabolka) 소개 (0) | 2021.08.26 |
윈도우(Windows) 10에서 기본 브라우저 변경하는 방법
[기본 앱]을 검색하여 실행한다.

이후에 [웹 브라우저] 탭에서 원하는 브라우저를 선택한다. 필자는 [Chrome]을 선택했다.

'기타' 카테고리의 다른 글
| 크롬(Chrome) 브라우저 시크릿 모드 사용 방법 (+ 간단한 원리 설명) (0) | 2021.08.28 |
|---|---|
| 인터넷 속도(다운로드, 업로드, Ping) 간단 측정 방법! Feat. NIA 사이트 (0) | 2021.08.27 |
| Rufus를 이용해 윈도우 10 OS 이미지를 USB에 굽는 방법 (0) | 2021.08.26 |
| 텍스트를 음성(오디오)으로 바꾸어 주는 TTS 프로그램 발라볼카(Balabolka) 소개 (0) | 2021.08.26 |
| 500만 원으로 개발자용/영상 작업용/게임용 목적의 데스크탑 PC 견적을 내보았다. (다나와, 컴퓨존) (0) | 2021.08.19 |
Rufus를 이용해 윈도우 10 OS 이미지를 USB에 굽는 방법
윈도우(Windows) 운영체제의 이미지 파일(ISO 파일)을 갖고 있다면, Rufus를 이용해 USB 드라이브에 구울 수 있다. Rufus 프로그램은 공식 웹 사이트에 접속하여 다운로드할 수 있다. 공식 웹 사이트는 주소는 다음과 같다.
▶ Rufus: https://rufus.ie/
Rufus - The Official Website (Download, New Releases)
rufus.ie
접속 이후에는 [Rufus 3.15] 다운로드 버튼을 눌러 다운로드를 진행한다.

다운로드 이후에는 Rufus 프로그램을 실행한다. 이후에 다음과 같이 Windows 운영체제 ISO 파일을 [선택]한다. 이후에 파티션 방식 및 UEFI 여부를 선택할 수 있는데, 필자는 2021년 기준 최신 메인보드를 이용하고 있기 때문에, 해당 설정 그대로 이미지를 구웠다.
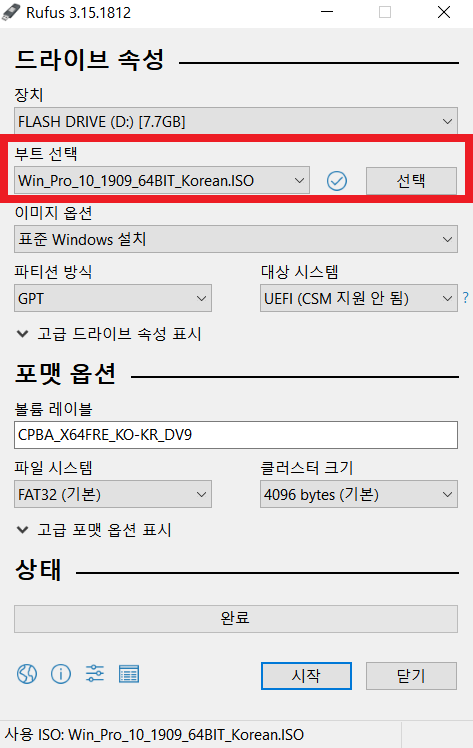
USB에 이미지를 완전히 구운 뒤에는 다음과 같이 [완료] 메시지가 출력된다.

이렇게 구워진 USB를 새로운 컴퓨터에 꽂은 뒤에 윈도우(Windows)로 부팅할 수 있다. 최신 Windows 운영체제는 기본적으로 Microsoft 계정을 필요로 한다는 점을 기억하자. 필자는 학교에서 제공하는 Microsoft 계정을 이용하여 로그인을 진행했고, 정상적으로 윈도우 운영체제를 사용할 수 있었다.
'기타' 카테고리의 다른 글
| 인터넷 속도(다운로드, 업로드, Ping) 간단 측정 방법! Feat. NIA 사이트 (0) | 2021.08.27 |
|---|---|
| 윈도우(Windows) 10에서 기본 브라우저 변경하는 방법 (0) | 2021.08.27 |
| 텍스트를 음성(오디오)으로 바꾸어 주는 TTS 프로그램 발라볼카(Balabolka) 소개 (0) | 2021.08.26 |
| 500만 원으로 개발자용/영상 작업용/게임용 목적의 데스크탑 PC 견적을 내보았다. (다나와, 컴퓨존) (0) | 2021.08.19 |
| Instance Normalization를 NumPy 및 PyTorch로 구현하는 방법! (0) | 2021.08.18 |
텍스트를 음성(오디오)으로 바꾸어 주는 TTS 프로그램 발라볼카(Balabolka) 소개
발라볼카(Balabolka)는 대표적인 TTS(Text-to-Speech) 프로그램 중 하나다. 이름에서부터 알 수 있듯이 말 그대로 텍스트(text)를 음성(speech)으로 변환해주는 소프트웨어다. 이러한 Balabolka는 프리웨어(freeware)이므로 무료로 이용할 수 있다는 점이 장점이다. Balabolka는 다음의 경로에 접속하여 다운로드할 수 있다.
▶ Balabolka 다운로드: http://www.cross-plus-a.com/kr/balabolka.htm
Balabolka
Balabolka는 텍스트 음성 변환(Text-To-Speech, TTS) 프로그램입니다. 당신의 시스템에 설치된 모든 컴퓨터 목소리는 Balabolka로 이용할 수 있습니다. 화면 상의 텍스트를 WAV, MP3, MP4, OGG 또는 WMA 파일로 저
www.cross-plus-a.com
웹 사이트에 접속한 뒤에 [Balabolka 다운로드] 버튼을 눌러 프로그램을 다운로드할 수 있다.

다운로드 이후에는 압축을 해제한다.

그리고 설치 프로그램인 setup.exe 파일을 실행하여 설치를 진행하면 된다. 먼저 언어(language)를 선택한 뒤에, 기본적인 내용 그대로 [Next]를 눌러 설치 과정을 진행하여도 큰 무리가 없다.

필자는 기본적인 설정 그대로 [Next]를 눌러 설치를 진행했다.

설치가 완료된 이후에는 [Finish] 버튼을 누르면 된다.

발라볼카(Balabolka)를 실행한 뒤에는 다음과 같이 텍스트를 입력하고, [재생] 버튼을 눌러 음성을 확인할 수 있다. 참고로 Rate는 음성의 속도, Pitch는 목소리의 높낮이, Volume은 목소리의 크기에 해당한다.
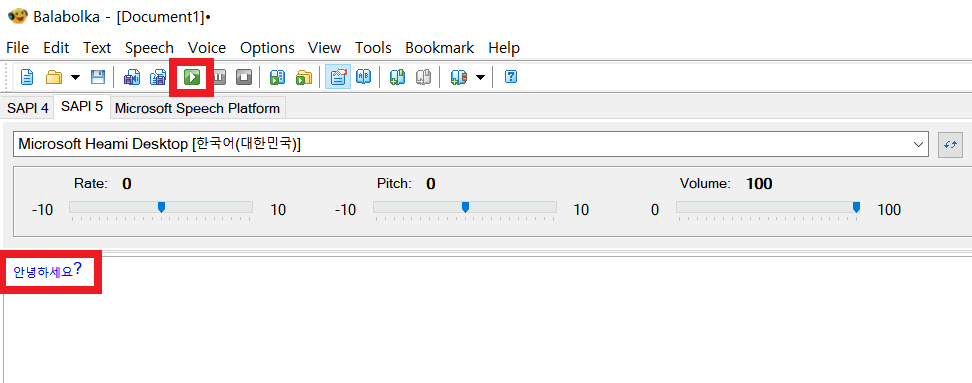
목소리를 오디오 파일로 저장하고 싶을 때는 다음과 같은 버튼을 누르면 된다.

'기타' 카테고리의 다른 글
| 윈도우(Windows) 10에서 기본 브라우저 변경하는 방법 (0) | 2021.08.27 |
|---|---|
| Rufus를 이용해 윈도우 10 OS 이미지를 USB에 굽는 방법 (0) | 2021.08.26 |
| 500만 원으로 개발자용/영상 작업용/게임용 목적의 데스크탑 PC 견적을 내보았다. (다나와, 컴퓨존) (0) | 2021.08.19 |
| Instance Normalization를 NumPy 및 PyTorch로 구현하는 방법! (0) | 2021.08.18 |
| 한국투자증권 모바일 앱으로 해외 주식 거래 하는 방법 (해외 주식 거래 신청 방법) (0) | 2021.08.17 |
어도비 프리미어(Adobe Premiere)에서 재생 해상도 낮게 설정하는 방법 (편집 중 튕김 방지)
프리미어 프로에서 편집을 진행하다가, 간혹 튕기는 경우가 있다. 이럴 때는 재생 해상도를 낮추는 것을 추천한다. 동영상이 재생되는 화면의 오른쪽 아래에서 [재생 해상도 선택] 탭을 누를 수 있다.

여기에서 재생 해상도를 설정할 수 있는데, 편집을 할 때에는 최대한 렉이 걸리지 않도록 하기 위해 [1/4]로 설정하는 것을 추천한다. 어차피 동영상 [내보내기] 이후에 고화질로 동영상을 볼 수 있기 때문에, 편집할 때는 고전적인 프리미어 튕김 문제나 렉으로부터 시간을 덜 뺏기기 위해 재생 해상도를 [1/4]로 설정하도록 하자.

이후에 다음과 같이 동영상을 재생할 때의 해상도가 낮아지는 것을 확인할 수 있다.

'프리미어 동영상 편집' 카테고리의 다른 글
| 어도비 프리미어(Adobe Premiere)를 이용해 크로마키 합성하는 방법! (0) | 2021.07.31 |
|---|---|
| 어도비 프리미어(Premiere) 동영상/사진 점진적으로 확대하기 (0) | 2021.06.05 |
| 어도비 프리미어(Premiere) 동영상에 자막(캡션) 달기 (0) | 2021.06.05 |
| 어도비 프리미어(Premiere)에서 비네팅 효과로 동영상의 주변 부분을 어둡게 만드는 방법 (0) | 2021.05.29 |
| 어도비 프리미어(Premiere)를 이용해 동영상 내 휴대폰이나 TV에 또 따른 동영상/사진 넣기 (0) | 2021.05.22 |
500만 원으로 개발자용/영상 작업용/게임용 목적의 데스크탑 PC 견적을 내보았다. (다나와, 컴퓨존)
필자는 최근에 이사를 가서, 새로운 PC가 필요한 상황이다. 컴퓨터 견적을 내주는 사이트는 굉장히 다양하지만, 필자는 주로 ① 컴퓨존과 ② 다나와에서 검색해서 찾아보았다. 다나와 조립PC 메인 페이지는 다음과 같다.
▶ 다나와 조립PC 메인 페이지: http://shop.danawa.com/shopmain/
조립PC : 샵다나와
가정/사무용PC, 게임용PC, 하이엔드PC 등 다양한 조립PC를 한눈에 비교하고 저렴하게 구매하세요.
shop.danawa.com
이후에 [하이엔드PC] - [고사양 게임용]에 들어가면 고성능 PC 견적을 확인할 수 있다.

가격대를 확인하면서 둘러보면 된다. 이때 평가와 후기가 많은 상품을 선택하여 확인할 수 있다.

이후에 다음과 같이 해당 제품의 [기본사양]을 확인할 수 있다. 여기에서 어떤 제품으로 구성되어 있는지 확인해 보는 것에만 목적을 두는 것이 좋다. 왜냐하면 이 제품 구성 그대로 사는 것도 가능하기는 하지만, 동일한 제품 구성을 더욱 저렴하게 살 수 있는 경우도 있기 때문이다. 그러니까 일단 확인만 해보자. 기본 구성은 다음과 같다고 한다.
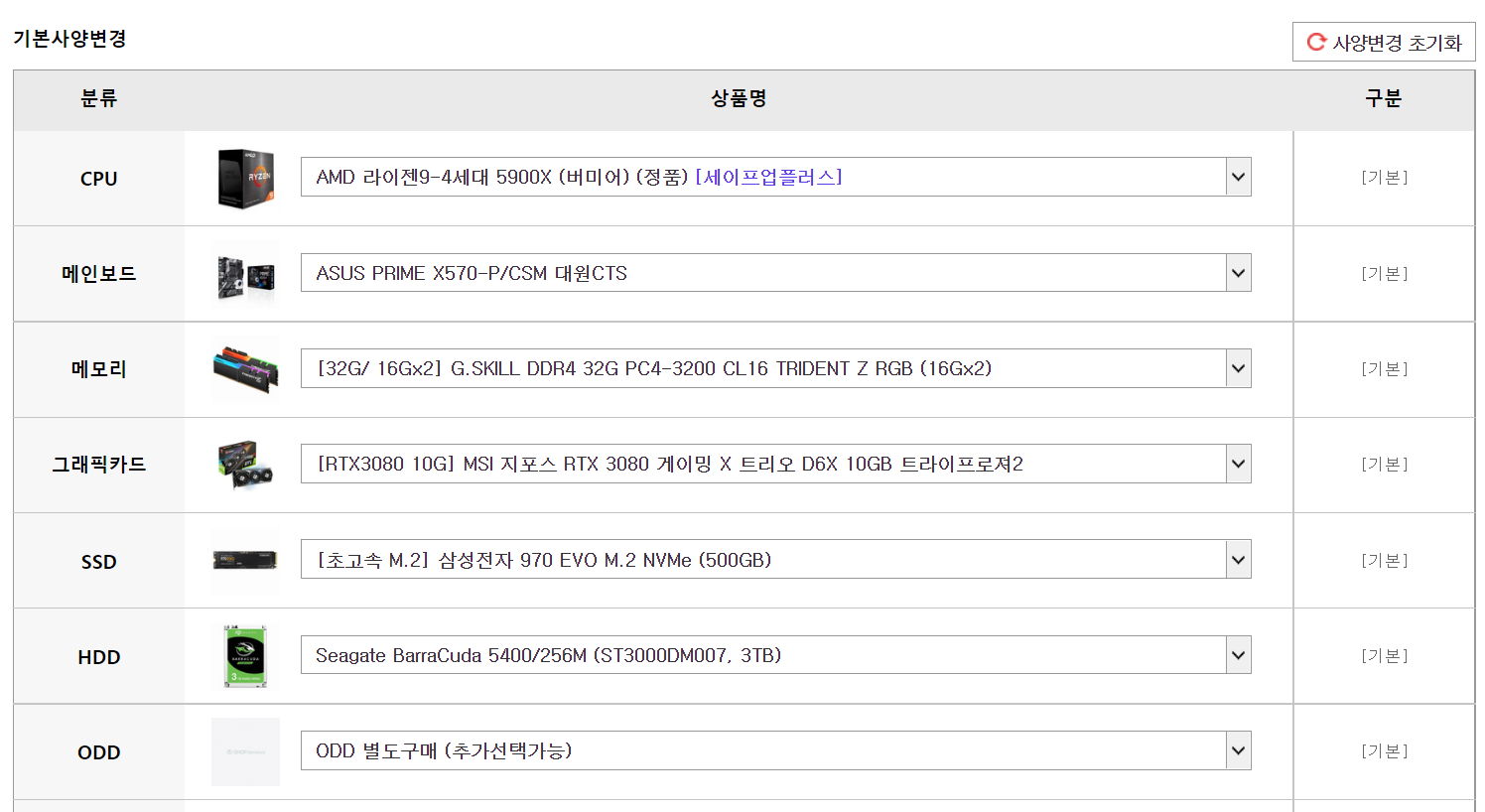
※ 필자가 선택한 부품 ※
다음과 같이 상품명을 조금씩 바꾸어 보며, 기본적인 스펙을 구성해 보았다. (이는 단순히 기본 스펙만 결정한 것으로, 최종적으로는 상당수 부품을 다시 골랐다.) 참고로 이와 같이 상품을 직접 선택하여 구매하면 가격이 상당히 높게 형성될 수 있다. 그래서 필자의 경우, 이러한 제품 페이지에서 직접 구매하는 것을 추천하지는 않는다. 그래서 웬만하면 컴퓨존이나 다나와에서 부품을 개별적으로 검색하여 최종적인 최저가를 찾은 뒤에, 해당 최저 가격으로 구매하는 것이 좋다.


※ 필자의 최종 선택 ※
결과적으로 필자는 다음과 같이 부품을 구성했다.
▶ CPU = AMD 라이젠9-4세대 5900X: 현 시점에서 가격은 60만 원이 넘지만, CPU 중에서는 베이스라인이 되는 꽤 괜찮은 스펙의 제품이다.
▶ 메인보드 = TUF GAMING X570-PLUS: 가격은 약 27만 원 정도로, M.2 소켓이 2개 있다. 무난한 스펙의 메인보드다.
▶ 메인 메모리 = 삼성전자 DDR4-3200 (32GB): 가격은 약 18만 원 정도로, 32GB를 2개 설치하면 총 36만 원 정도의 가격으로 총 64GB만큼의 메인 메모리를 확보할 수 있다.
▶ 그래픽 카드 = GeForce RTX 3080 Ti 12GB: 가격은 약 218만 원 정도로, 고사양 게임이나 영상 편집 작업에서 GPU 작업이 필요하다면 무난하게 소화할 수 있다.
▶ SSD = 970 EVO Plus series 2TB M.2 NVMe 2TB MZ-V7S2T0BW: 가격은 약 43만 원 정도로, 충분히 많은 프로그램을 설치하기 위해서는 2TB 정도의 용량이 필요하다는 생각이 들었다.
▶ 파워 = Classic II 1050W 80PLUS GOLD 230V EU 풀모듈러: 가격은 약 18만 원 정도로, 무난한 파워 제품이다.
▶ 하드(HDD) = Western Digital WD BLUE 5400/256M (WD40EZAZ, 4TB): 가격은 약 11만 원 정도로, 별도로 저장할 필요가 있는 데이터에 대하여 저장할 수 있도록 4TB 정도의 큰 용량으로 준비했다.
▶ 쿨러 = 쿨러마스터 MasterLiquid ML360L V2 ARGB: 가격은 15만 원 정도로, 다른 사람들이 많이 사용하는 제품인 것 같아서 이를 구매했다.
▶ 모니터 = LG UHD 모니터 32UN650: 가격은 약 60만 원 정도로, 해상도는 3840 X 2160 (4K UHD)이며, 리뷰가 좋은 제품이라는 점에서 이를 구매했다.
▶ 키보드 = [COX] 유선 무접점 키보드, Empress (엠프리스) RGB PBT, 35G: 가격은 약 16만 원 정도로, 필자는 키압이 가벼운 것을 선호하기 때문에 35g 정도의 가벼운 키압의 키보드를 선택했다.
▶ 마우스 = 로지텍 G102 LIGHTSYNC: 가격은 2만 원 정도로, 대충 저렴한 것을 선택했다.
▶ 케이스 = darkFlash DLX21 RGB MESH 강화유리: 가격은 약 9만 원 정도로, 많이 사용되는 모델이라서 선택했다.
▶ 마우스 패드 = 펠로우즈 플러쉬터치 마우스패드: 가격은 약 1만 원 정도로, 개인적으로 손목이 불편해서 손목 보호대가 포함된 마우스 패드를 선택했다.
※ 최종 결제 ※
▶ 다나와 PC견적 내보기 (링크): CPU, 메인보드, 그래픽카드 등 부품을 하나씩 선택할 수 있다.
▶ 컴퓨존 온라인 견적 내보기 (링크): 다나와 사이트와 마찬가지로 부품을 하나씩 선택할 수 있다.
이와 같이 모든 컴퓨터 부품을 결정했다면, ① 컴퓨존과 ② 다나와에서 각각 부품을 검색한 뒤에, 최종적인 금액이 더 저렴한 것을 선택하는 것이 좋다. 또한 네이버 페이와 같은 추가 할인 혜택이 있는지 확인해 보는 것이 좋다. 필자는 결과적으로 컴퓨존에서 구매하기로 했고, 원하는 제품들을 모두 선택했더니 다음과 같이 나왔다.

이제 [사양검토요청] 버튼을 눌러 각 제품이 서로 호환이 되는지 확인할 수 있다.
다음과 같이 문의할 내용을 작성한 뒤에, [사양검토 요청하기] 버튼을 누르면 된다.

그러면 일정 시간이 지난 뒤에 사양검토에 대한 답변 메일이 날라 온다. 필자의 경우에는 "고객님 확인해 보았습니다. 선택하신 제품들간에 호환성 및 안전성에는 문제가 없습니다. 이정도 사양이면 말씀하신 용도로 사용시 문제없이 사용을 하실수 있습니다. 특별히 변경할 제품은 없습니다."라고 답변받을 수 있었다.
실제로 제품을 주문하기 위해서는 각 제품을 [장바구니]에 담아야 하는데, 장바구니에 담을 수 없는 제품은 자동으로 제외된다. 예를 들어 10개 이상 구매해야 주문이 가능한 제품들이 있다. 그런 제품의 경우, 다른 제품으로 바꿀 필요가 있는지 확인해보도록 하자. 아무튼 결과적으로 다음과 같이 장바구니에 모든 물품이 담기도록 하면 된다. 또한 일부 제품의 경우 주문할 때 재고가 없어서 [품절] 상태일 수 있는데, 품절 상태라면 다른 유사한 제품을 대신 찾아서 장바구니를 다시 채우면 된다.

최종적으로 주문할 때는 조립과 관련한 내용을 선택할 수 있다. 필자는 다음과 같이 [일반 조립]을 선택했다.

결과적으로 [전체 주문하기] 버튼을 눌러 이와 같이 주문하면, 조립이 된 상태로 PC가 도착하게 된다. 필자는 컴퓨터의 가격대가 있다 보니, 가능한 퀵으로 안전하고 빠르게 받고 싶어서 [퀵서비스]를 선택했다.

또한 [무통장 입금]을 선택하고, 다음과 같이 현금영수증 신청을 선택하여 결제를 진행했다.

필자는 결제를 하자마자, 거의 5분 만에 바로 컴퓨존 담당자 분으로부터 연락을 받았다. 컴퓨존에서는 선택한 케이스와 메인보드가 완벽히 호환이 되지는 않기 때문에, 전면에 있는 C 타입 단자 하나를 사용하지 못하게 될 것 같다고 하셨다. 필자는 C 타입 단자 하나 정도는 사용하지 않아도 된다고 말씀을 드렸기에, 필자가 선택한 대로 조립을 해주시기로 하셨다. 그리고 무통장 입금으로 돈을 바로 보내면, 당일 오후에 바로 퀵으로 도착한다고 해주셨다. 그래서 필자는 현금영수증을 신청한 형태로, 무통장 입금으로 바로 돈을 보내서 결제를 마쳤다.
※ 참고사항 ※
필자는 컴퓨존에서 조립해 준 PC를 받기만 하고, 윈도우(Windows) 운영체제는 필자가 자체적으로 설치했다. 다만, 윈도우 운영체제 설치 후 부팅 단계에서 "CPU Fan Error!" 라는 오류가 발생했다. 메인보드 펌웨어 단에서 잡지 않고, 윈도우 OS 단에서 잡아준 오류라서 컴퓨존에서 놓친 것이라고 생각한다. 확인해 보니, CPU 팬(fan) 파워 케이블이 올바르지 않은 곳에 꽂혀 있었다. 그래서 필자가 CPU 팬 파워 케이블을 올바른 곳에 다시 꽂았더니, 정상적으로 OS 부팅이 진행되었다. 필자는 전공자이므로 어렵지 않게 문제를 해결했지만, 만약 컴퓨터를 잘 모르는 사람이었다면 많이 헤맸을지도 모른다. 그렇지만 개인적으로는 컴퓨존의 PC 조립 서비스에는 상당히 만족했다.
'기타' 카테고리의 다른 글
| Rufus를 이용해 윈도우 10 OS 이미지를 USB에 굽는 방법 (0) | 2021.08.26 |
|---|---|
| 텍스트를 음성(오디오)으로 바꾸어 주는 TTS 프로그램 발라볼카(Balabolka) 소개 (0) | 2021.08.26 |
| Instance Normalization를 NumPy 및 PyTorch로 구현하는 방법! (0) | 2021.08.18 |
| 한국투자증권 모바일 앱으로 해외 주식 거래 하는 방법 (해외 주식 거래 신청 방법) (0) | 2021.08.17 |
| 내 집 장만 혹은 이사갈 때 사야 할 것/해야 할 일 목록 총정리 (0) | 2021.08.17 |
Instance Normalization를 NumPy 및 PyTorch로 구현하는 방법!
Instance Normalization은 Single Feature Map에 대하여 Normalization을 수행하는 기법이다. Instance Normalization은 Style Transfer나 StyleGAN과 같이 다양한 기술 및 아키텍처에서 활용되기 때문에, 알아 두면 상당히 좋다.
※ Batch Normalization ※
먼저 Batch Normalization에 대해 알아보자. 매우 많은 딥러닝 네트워크에서 활용되고 있는 정규화 레이어이며, Batch Normalization은 채널별로 현재 배치에 포함된 모든 이미지에 대하여 정규화를 수행한다. 그래서 각 채널별로 mean과 variance를 계산하는 것을 확인할 수 있다.

※ Instance Normalization ※
Instance Normalization은 개별적인 이미지에 대하여 채널별로 정규화를 수행한다는 점이 특징이다. Batch Normalization과 상당히 유사하지만, Instance Normalization은 개별적인 이미지 인스턴스(instance) 단위로 채널별로 정규화를 수행한다.

※ NumPy로 Instance Normalization 구현하기 ※
Numpy로 Instance Normalization을 구현해보자. 아래 코드를 보면, 각 이미지에 대하여 채널별로 variance와 mean을 계산하는 것을 알 수 있다.
import numpy as np
def calc_mean_std(feat, eps=1e-5):
n, c, h, w = feat.shape
feat_var = np.var(feat.reshape(n, c, -1), axis=2) + eps
feat_std = np.sqrt(feat_var).reshape(n, c, 1, 1)
feat_mean = np.mean(feat.reshape(n, c, -1), axis=2).reshape(n, c, 1, 1)
return feat_mean, feat_std
X = np.asarray([
# image 1
[
[[1, 2, 9, 2, 7],
[5, 0, 3, 1, 8],
[4, 1, 3, 0, 6],
[2, 5, 2, 9, 5],
[6, 5, 1, 3, 2]],
[[4, 5, 7, 0, 8],
[5, 8, 5, 3, 5],
[4, 2, 1, 6, 5],
[7, 3, 2, 1, 0],
[6, 1, 2, 2, 6]],
[[3, 7, 4, 5, 0],
[5, 4, 6, 8, 9],
[6, 1, 9, 1, 6],
[9, 3, 0, 2, 4],
[1, 2, 5, 5, 2]]
],
# image 2
[
[[7, 2, 1, 4, 2],
[5, 4, 6, 5, 0],
[1, 2, 4, 2, 8],
[5, 9, 0, 5, 1],
[7, 6, 2, 4, 6]],
[[5, 4, 2, 5, 7],
[6, 1, 4, 0, 5],
[8, 9, 4, 7, 6],
[4, 5, 5, 6, 7],
[1, 2, 7, 4, 1]],
[[7, 4, 8, 9, 7],
[5, 5, 8, 1, 4],
[3, 2, 2, 5, 2],
[1, 0, 3, 7, 6],
[4, 5, 4, 5, 5]]
]
])
print('Images:', X.shape)
# size = X.shape
feat_mean, feat_std = calc_mean_std(X)
print('Std:', feat_std.shape)
print('Mean:', feat_mean.shape)
out = (X - feat_mean) / feat_std
# We can get the same result by the below code.
# out = (X - np.broadcast_to(feat_mean, size)) / np.broadcast_to(feat_std, size)
print(out)
실행 결과는 다음과 같다.
Images: (2, 3, 5, 5)
Std: (2, 3, 1, 1)
Mean: (2, 3, 1, 1)
[[[[-1.01167305 -0.6341831 2.0082465 -0.6341831 1.25326661]
[ 0.49828672 -1.38916299 -0.25669316 -1.01167305 1.63075655]
[ 0.12079678 -1.01167305 -0.25669316 -1.38916299 0.87577667]
[-0.6341831 0.49828672 -0.6341831 2.0082465 0.49828672]
[ 0.87577667 0.49828672 -1.01167305 -0.25669316 -0.6341831 ]]
[[ 0.03335184 0.45024982 1.28404578 -1.63424008 1.70094375]
[ 0.45024982 1.70094375 0.45024982 -0.38354614 0.45024982]
[ 0.03335184 -0.80044412 -1.2173421 0.8671478 0.45024982]
[ 1.28404578 -0.38354614 -0.80044412 -1.2173421 -1.63424008]
[ 0.8671478 -1.2173421 -0.80044412 -0.80044412 0.8671478 ]]
[[-0.46796399 0.99442348 -0.10236712 0.26322975 -1.5647546 ]
[ 0.26322975 -0.10236712 0.62882661 1.36002035 1.72561722]
[ 0.62882661 -1.19915773 1.72561722 -1.19915773 0.62882661]
[ 1.72561722 -0.46796399 -1.5647546 -0.83356086 -0.10236712]
[-1.19915773 -0.83356086 0.26322975 0.26322975 -0.83356086]]]
[[[ 1.24161152 -0.77399159 -1.17711222 0.03224965 -0.77399159]
[ 0.43537027 0.03224965 0.83849089 0.43537027 -1.58023284]
[-1.17711222 -0.77399159 0.03224965 -0.77399159 1.64473214]
[ 0.43537027 2.04785276 -1.58023284 0.43537027 -1.17711222]
[ 1.24161152 0.83849089 -0.77399159 0.03224965 0.83849089]]
[[ 0.17149843 -0.25724764 -1.11473978 0.17149843 1.02899057]
[ 0.6002445 -1.54348585 -0.25724764 -1.97223192 0.17149843]
[ 1.45773663 1.8864827 -0.25724764 1.02899057 0.6002445 ]
[-0.25724764 0.17149843 0.17149843 0.6002445 1.02899057]
[-1.54348585 -1.11473978 1.02899057 -0.25724764 -1.54348585]]
[[ 1.07948803 -0.20561677 1.50785629 1.93622455 1.07948803]
[ 0.2227515 0.2227515 1.50785629 -1.49072156 -0.20561677]
[-0.63398503 -1.06235329 -1.06235329 0.2227515 -1.06235329]
[-1.49072156 -1.91908982 -0.63398503 1.07948803 0.65111976]
[-0.20561677 0.2227515 -0.20561677 0.2227515 0.2227515 ]]]]
※ PyTorch로 Instance Normalization 구현하기 ※
이어서 PyTorch로 Instance Normalization을 구현하는 방법은 다음과 같다. 위 코드와 같은 로직이다.
import numpy as np
import torch
def calc_mean_std(feat, eps=1e-5):
n, c, h, w = feat.shape
feat_var = feat.view(n, c, -1).var(dim=2) + eps
feat_std = feat_var.sqrt().view(n, c, 1, 1)
feat_mean = feat.view(n, c, -1).mean(dim=2).view(n, c, 1, 1)
return feat_mean, feat_std
X = torch.from_numpy(np.asarray([
# image 1
[
[[1, 2, 9, 2, 7],
[5, 0, 3, 1, 8],
[4, 1, 3, 0, 6],
[2, 5, 2, 9, 5],
[6, 5, 1, 3, 2]],
[[4, 5, 7, 0, 8],
[5, 8, 5, 3, 5],
[4, 2, 1, 6, 5],
[7, 3, 2, 1, 0],
[6, 1, 2, 2, 6]],
[[3, 7, 4, 5, 0],
[5, 4, 6, 8, 9],
[6, 1, 9, 1, 6],
[9, 3, 0, 2, 4],
[1, 2, 5, 5, 2]]
],
# image 2
[
[[7, 2, 1, 4, 2],
[5, 4, 6, 5, 0],
[1, 2, 4, 2, 8],
[5, 9, 0, 5, 1],
[7, 6, 2, 4, 6]],
[[5, 4, 2, 5, 7],
[6, 1, 4, 0, 5],
[8, 9, 4, 7, 6],
[4, 5, 5, 6, 7],
[1, 2, 7, 4, 1]],
[[7, 4, 8, 9, 7],
[5, 5, 8, 1, 4],
[3, 2, 2, 5, 2],
[1, 0, 3, 7, 6],
[4, 5, 4, 5, 5]]
]
], dtype=np.float64))
print('Images:', X.shape)
# size = X.shape
feat_mean, feat_std = calc_mean_std(X)
print('Mean:', feat_mean.shape)
print('Std:', feat_std.shape)
out = (X - feat_mean) / feat_std
# out = (X - feat_mean.expand(size)) / feat_std.expand(size)
print(out)
실행 결과는 다음과 같다.
Images: torch.Size([2, 3, 5, 5])
Mean: torch.Size([2, 3, 1, 1])
Std: torch.Size([2, 3, 1, 1])
tensor([[[[-0.9912, -0.6214, 1.9677, -0.6214, 1.2279],
[ 0.4882, -1.3611, -0.2515, -0.9912, 1.5978],
[ 0.1184, -0.9912, -0.2515, -1.3611, 0.8581],
[-0.6214, 0.4882, -0.6214, 1.9677, 0.4882],
[ 0.8581, 0.4882, -0.9912, -0.2515, -0.6214]],
[[ 0.0327, 0.4412, 1.2581, -1.6012, 1.6666],
[ 0.4412, 1.6666, 0.4412, -0.3758, 0.4412],
[ 0.0327, -0.7843, -1.1927, 0.8496, 0.4412],
[ 1.2581, -0.3758, -0.7843, -1.1927, -1.6012],
[ 0.8496, -1.1927, -0.7843, -0.7843, 0.8496]],
[[-0.4585, 0.9743, -0.1003, 0.2579, -1.5331],
[ 0.2579, -0.1003, 0.6161, 1.3325, 1.6908],
[ 0.6161, -1.1749, 1.6908, -1.1749, 0.6161],
[ 1.6908, -0.4585, -1.5331, -0.8167, -0.1003],
[-1.1749, -0.8167, 0.2579, 0.2579, -0.8167]]],
[[[ 1.2165, -0.7584, -1.1533, 0.0316, -0.7584],
[ 0.4266, 0.0316, 0.8215, 0.4266, -1.5483],
[-1.1533, -0.7584, 0.0316, -0.7584, 1.6115],
[ 0.4266, 2.0065, -1.5483, 0.4266, -1.1533],
[ 1.2165, 0.8215, -0.7584, 0.0316, 0.8215]],
[[ 0.1680, -0.2521, -1.0922, 0.1680, 1.0082],
[ 0.5881, -1.5123, -0.2521, -1.9324, 0.1680],
[ 1.4283, 1.8484, -0.2521, 1.0082, 0.5881],
[-0.2521, 0.1680, 0.1680, 0.5881, 1.0082],
[-1.5123, -1.0922, 1.0082, -0.2521, -1.5123]],
[[ 1.0577, -0.2015, 1.4774, 1.8971, 1.0577],
[ 0.2183, 0.2183, 1.4774, -1.4606, -0.2015],
[-0.6212, -1.0409, -1.0409, 0.2183, -1.0409],
[-1.4606, -1.8803, -0.6212, 1.0577, 0.6380],
[-0.2015, 0.2183, -0.2015, 0.2183, 0.2183]]]],
dtype=torch.float64)'기타' 카테고리의 다른 글
| 텍스트를 음성(오디오)으로 바꾸어 주는 TTS 프로그램 발라볼카(Balabolka) 소개 (0) | 2021.08.26 |
|---|---|
| 500만 원으로 개발자용/영상 작업용/게임용 목적의 데스크탑 PC 견적을 내보았다. (다나와, 컴퓨존) (0) | 2021.08.19 |
| 한국투자증권 모바일 앱으로 해외 주식 거래 하는 방법 (해외 주식 거래 신청 방법) (0) | 2021.08.17 |
| 내 집 장만 혹은 이사갈 때 사야 할 것/해야 할 일 목록 총정리 (0) | 2021.08.17 |
| 딥러닝(Deep Learning) 학회에 논문을 제출한 뒤에, 리뷰(Review) 평가 분석 및 Rebuttal 쓰는 방법 (0) | 2021.08.13 |
한국투자증권 모바일 앱으로 해외 주식 거래 하는 방법 (해외 주식 거래 신청 방법)
※ 미국 주식시장 ※
미국 주식은 국내 주식보다 세금 부과를 더 많이 하는 편이다. 그럼에도 더 많은 수익률을 노리기 위하여 미국 주식을 구매하고자 하는 경우가 많다. 기본적으로 미국 주식시장의 개장 시간은 미국 동부 기준으로 주중 9시 30분 ~ 16시다. 한국 기준으로 저녁 23시 30분부터 그다음 날 새벽 6시까지 미국 주식시장에서 거래를 진행할 수 있다. 참고로 서머타임과 같은 제도가 있기 때문에, 실제로 거래가 가능한 정확한 시간을 확인할 필요가 있다. 본 포스팅에서는 한국투자증권 앱을 이용해 해외 주식을 사고파는 방법을 소개한다.
※ 한국투자증권 해외 주식 거래 신청 ※
한국투자증권 앱을 실행한 뒤에 [메뉴] - [계좌/서비스] - [거래서비스신청] - [해외주식거래신청]을 눌러 신청한다. 다음과 같이 [거래신청] 버튼을 누른다. 기본적으로 한국투자증권은 기존에 가지고 있던 계좌를 이용해 해외 주식도 구매할 수 있도록 해주므로, 매우 편리하다. 또한 해외증권 거래신청을 할 때는 [투자성향]을 확인한 뒤에 신청해야 한다. 만약 본인의 투자 성향에 대해 작성하지 않았다면, 투자 성향을 체크하는 절차를 거쳐야 한다.



결과적으로 모든 약관을 잘 읽어 본 뒤에 [동의]하고, [거래 신청]을 완료하면 된다. 최종적으로 다음과 같이 해외증권 거래 신청이 완료되는 것을 확인할 수 있다.


※ 한국투자증권 해외 ETP(ETF) 거래 신청 ※
또한 S&P 500과 같은 ETF에도 투자하고 싶다면, 해외 ETP(ETF) 거래 항목 또한 신청할 필요가 있다. 한국투자증권 앱을 실행한 뒤에 [메뉴] - [계좌/서비스] - [거래서비스신청] - [해외ETP(ETF)거래신청]을 눌러 신청을 진행한다.



이후에 다음과 같이 마찬가지로 [해외ETP거래신청] 탭에서도 투자성향을 확인하고, 약관에 동의한 뒤에 신청을 완료하면 된다. 단순히 요구하는 대로 [확인]만 진행하면 큰 어려움 없이 신청 가능하다.



※ 한국투자증권 통합증거금 신청 ※
또한 한국투자증권에서는 통합증거금을 신청할 수 있다. 통합증거금 서비스를 이용하면, 가지고 있는 원화로 바로 거래가 가능하기 때문에 편리하다. 다시 말해 내가 직접 환전하지 않아도 자동환전되기 때문에 편리한 것이다.


이후에 마찬가지로 통합증거금 신청에 대하여 설명서를 확인하고 [동의] 버튼을 누르면 된다.



※ 한국투자증권을 이용해 해외 주식 구매하는 방법 ※
위와 같이 ① 해외 주식 거래 신청, ② 해외 ETP(ETF) 거래 신청, ③ 통합증거금 신청을 모두 마쳤다면, 편하게 해외 주식을 구매할 수 있다. 해외 주식을 구매할 때는 검색 페이지로 이동한 뒤에 [해외 주식]을 선택하고 이름을 입력하면 된다. 예를 들어 Invesco QQQ Trust (ETF)를 사고 싶다면, [인베스코 QQQ]를 검색하여 해당 주식을 구매할 수 있다. 앞서 언급했듯이 미국 주식은 우리나라 시간으로 늦은 저녁 시간에 구매할 수 있기 때문에, 해당 시간에 거래하기 어렵다면 [예약주문]을 이용하면 된다. 단, 한국투자증권에서는 예약 주문이 체결된 이후에도 해당 예약 주문을 취소해야 할 필요가 있다고 한다.
필자가 실제로 구매를 해보았는데, 과정은 매우 간단했다. [주문] - [검색]으로 들어간 뒤에, [해외주식] 탭을 선택하고,자신이 원하는 외국 회사 이름을 검색한다. 필자는 QQQ를 검색했다. 검색 이후에는 구매할 주식 개수를 검색한 뒤에 [사자] 버튼을 누르고 구매하면 된다.

이후에 다음과 같이 주문 내역을 자세히 확인한 뒤에 [사자 주문 전송하기] 버튼을 눌러 구매를 진행할 수 있다. 나중에 자신이 구매한 해외 주식을 확인하고 싶을 때는 [잔고] 페이지로 이동한 뒤에 [해외] - [체결잔고] 탭으로 들어가면 된다.


'기타' 카테고리의 다른 글
| 500만 원으로 개발자용/영상 작업용/게임용 목적의 데스크탑 PC 견적을 내보았다. (다나와, 컴퓨존) (0) | 2021.08.19 |
|---|---|
| Instance Normalization를 NumPy 및 PyTorch로 구현하는 방법! (0) | 2021.08.18 |
| 내 집 장만 혹은 이사갈 때 사야 할 것/해야 할 일 목록 총정리 (0) | 2021.08.17 |
| 딥러닝(Deep Learning) 학회에 논문을 제출한 뒤에, 리뷰(Review) 평가 분석 및 Rebuttal 쓰는 방법 (0) | 2021.08.13 |
| Python 코드를 활용하여 동전 던지기로 주사위 굴리기와 같은 결과 만들기(Rejection Sampling과 확률론) (0) | 2021.08.12 |
