Windows 10 운영체제에 VirtualBox 및 우분투(Ubuntu) 설치하기
※ VirtualBox 설치 ※
개발 혹은 실습을 할 때, 윈도우(Windows) 10 운영체제의 컴퓨터에 리눅스 운영체제의 가상 환경을 갖추어야 하는 경우가 종종 있다. 이번 포스팅에서는 오라클(Oracle)에서 무료로 제공하는 소프트웨어인 VirtualBox를 이용하여 리눅스 가상 환경을 갖추어 보도록 하겠다.
▶ VirtualBox 웹 사이트: https://www.virtualbox.org/
바로 다운로드 버튼을 눌러서 다운로드를 진행하자.
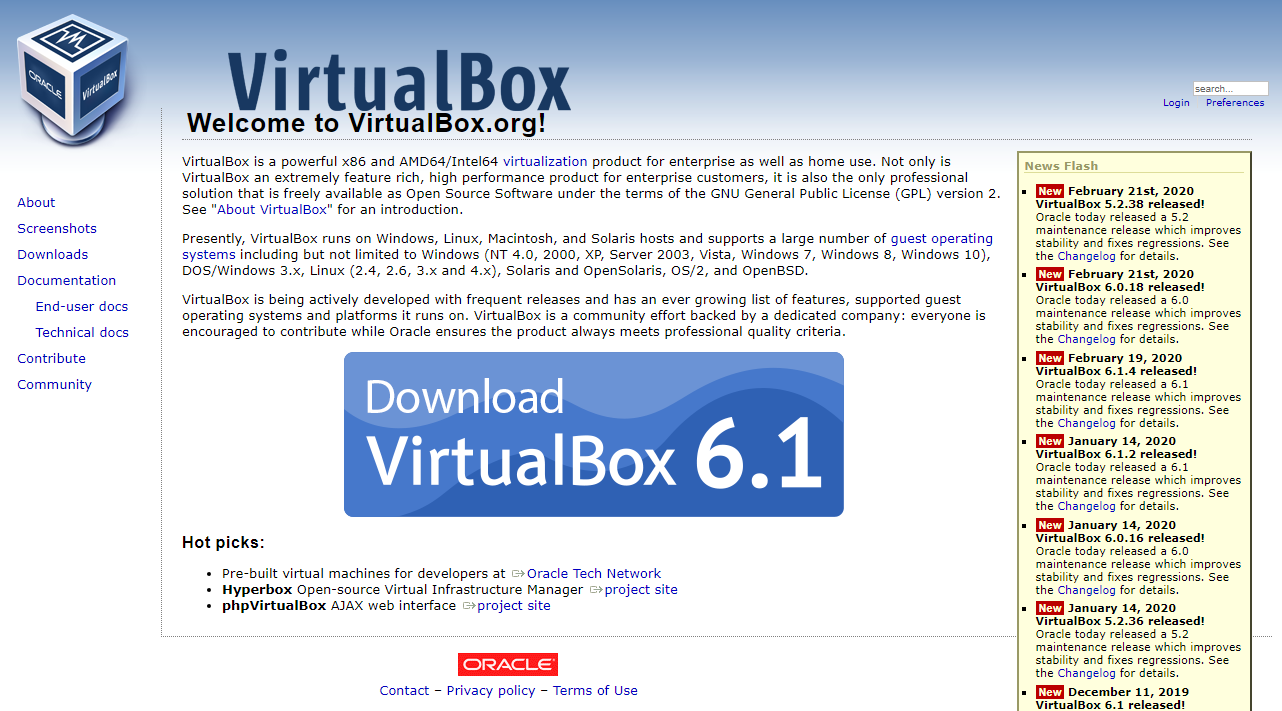
저자의 경우 호스트(Host) 운영체제가 윈도우(Windows)라서, 다음과 같이 [Windows hosts] 링크를 클릭하였다.
이제 VirtualBox 설치 프로그램을 실행하여, 설치를 진행하면 된다. 기본적인 설정 그대로 설치하는 것을 권장한다.
다음과 같이 [Next]를 눌러 설치를 진행한다.
기본적으로 가상 머신(Virtual Machine)을 설치하는 경우, 네트워크 인터페이스 또한 설정하는 경우가 많기 때문에 설치 과정 중에서 일시적으로 인터넷 연결이 끊길 수 있다.
이제 [Install] 버튼을 눌러서 설치를 진행한다.
설치 자체는 몇 분 이내로 적은 시간이 소요된다.
설치가 완료된 이후에는 Oracle VirtualBox를 실행할 수 있도록 한다.
실행된 VirtualBox의 형태는 다음과 같다.
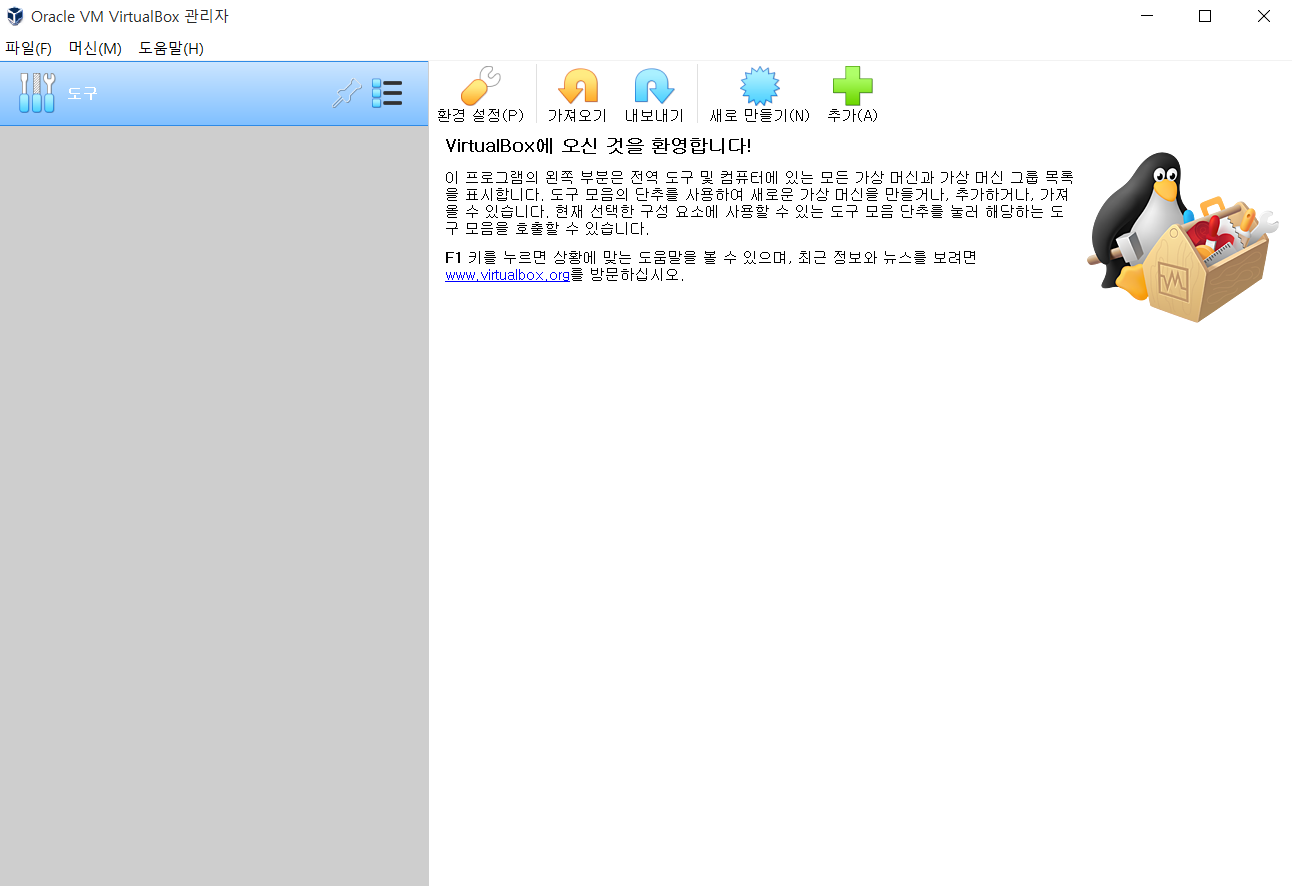
※ 리눅스 설치 ※
이제 리눅스를 설치해보자.
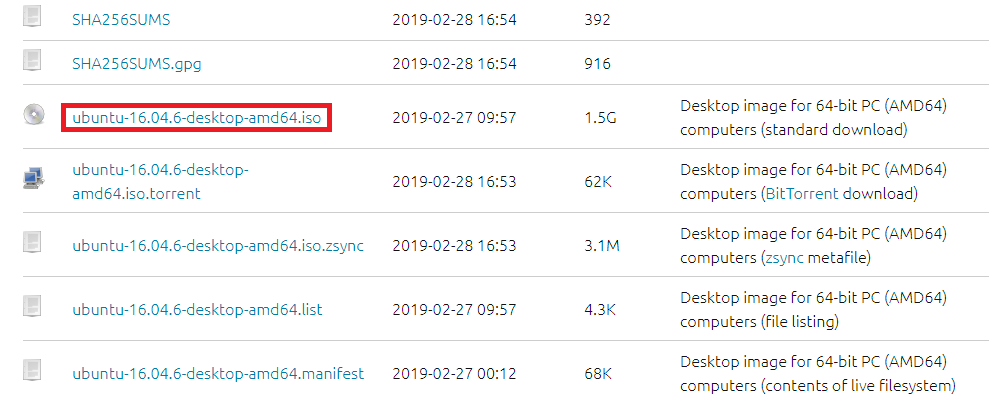
▶ 우분투 이미지 파일(ISO) 웹 사이트: http://releases.ubuntu.com/16.04/
[새로 만들기(N)] 버튼을 클릭하여 새롭게 가상 머신을 생성한다.
자신의 가상 머신에 이름을 붙이자. 아무렇게나 붙여도 된다.
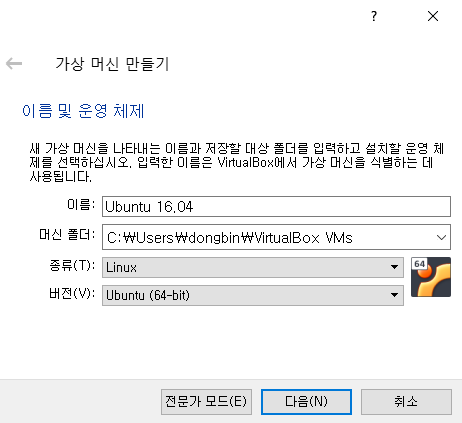
이제 메모리를 할당해야 한다. 저는 제 호스트 PC에 16GB의 메모리가 있기 때문에 2GB만큼 가상 머신에 할당하도록 하였다. 너무 과도하게 많은 메모리를 할당하는 경우, 설치 도중에 가상 머신이 갑자기 종료되거나 기타 다른 문제가 발생할 수 있다.

이어서 가상 머신에서 사용할 데이터 저장 목적의 하드 디스크를 추가할 수 있다. 일반적으로 새로운 가상 하드 디스크를 만들어 사용한다. 당연히 컴퓨터에 남은 하드 디스크 용량이 많아야 문제가 없을 것이다.
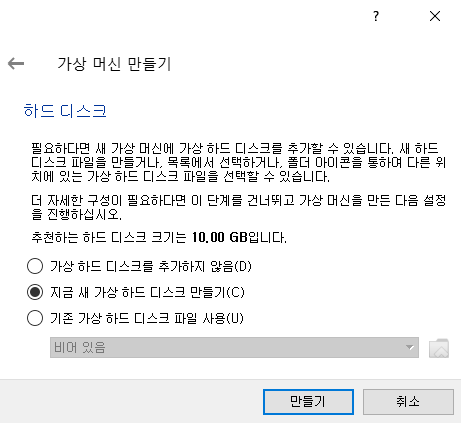
기본적인 하드 디스크 파일 종류인 VDI (VirtualBox Disk Image)를 선택하여 만들어 주자.
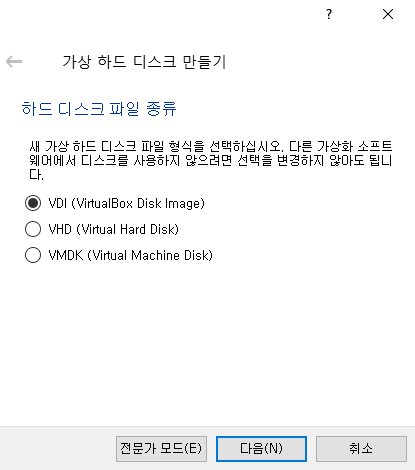
저자의 경우 SSD의 용량이 많이 남아 있었기 때문에, 고정 크기로 가상 하드 디스크를 만들었다.
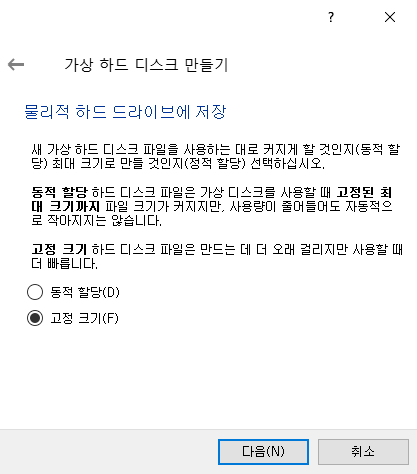
일단 기본 설정 그대로 10GB로 설정하여 만들어주자.
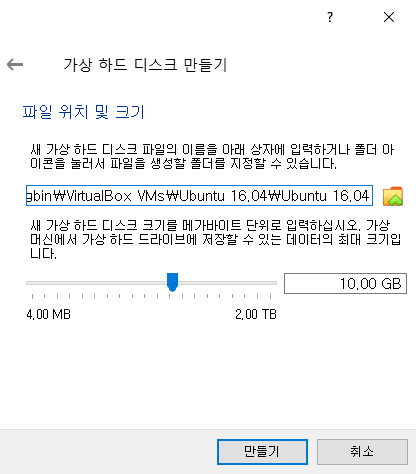
이제 하나의 가상 머신이 만들어 졌으므로, [설정(S)] 탭으로 이동하여 우분투 이미지를 적용해주자.
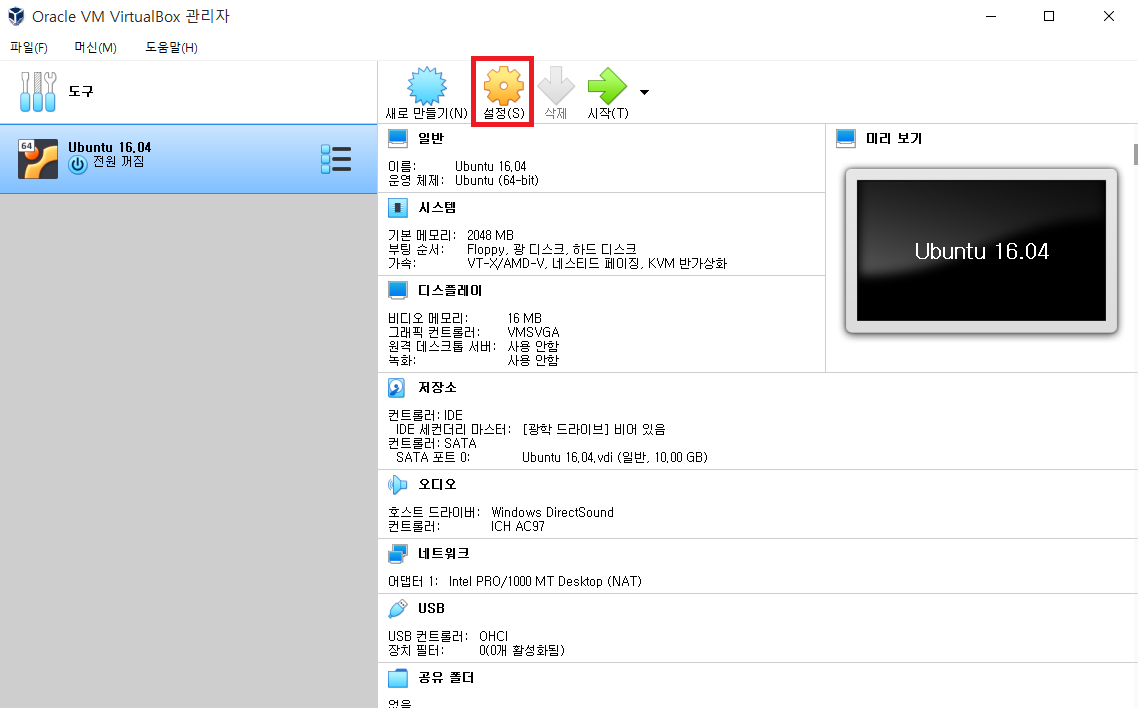
[저장소]에서 광학 드라이브(D)로 아까 전에 다운로드 받았던 우분투 ISO 파일을 선택해주면 된다.
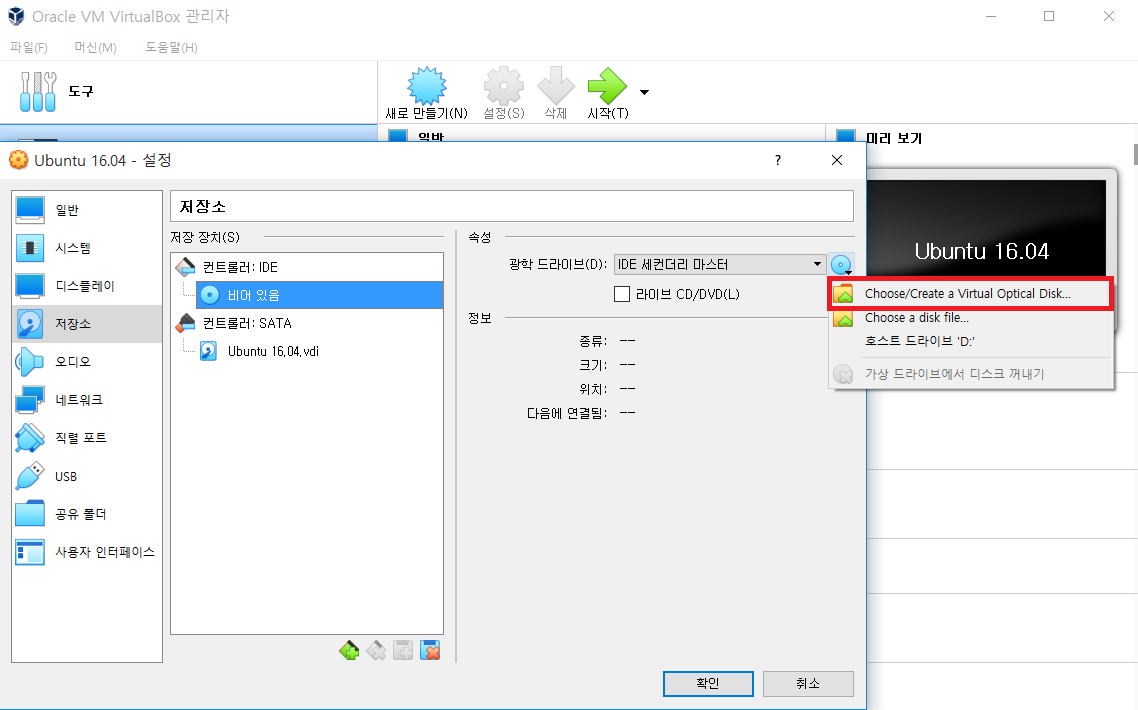
다음과 같이 정상적으로 선택되었다.
이제 [시작]을 누르면, 우분투 ISO 파일을 이용하여 우분투로 부팅이 진행된다.
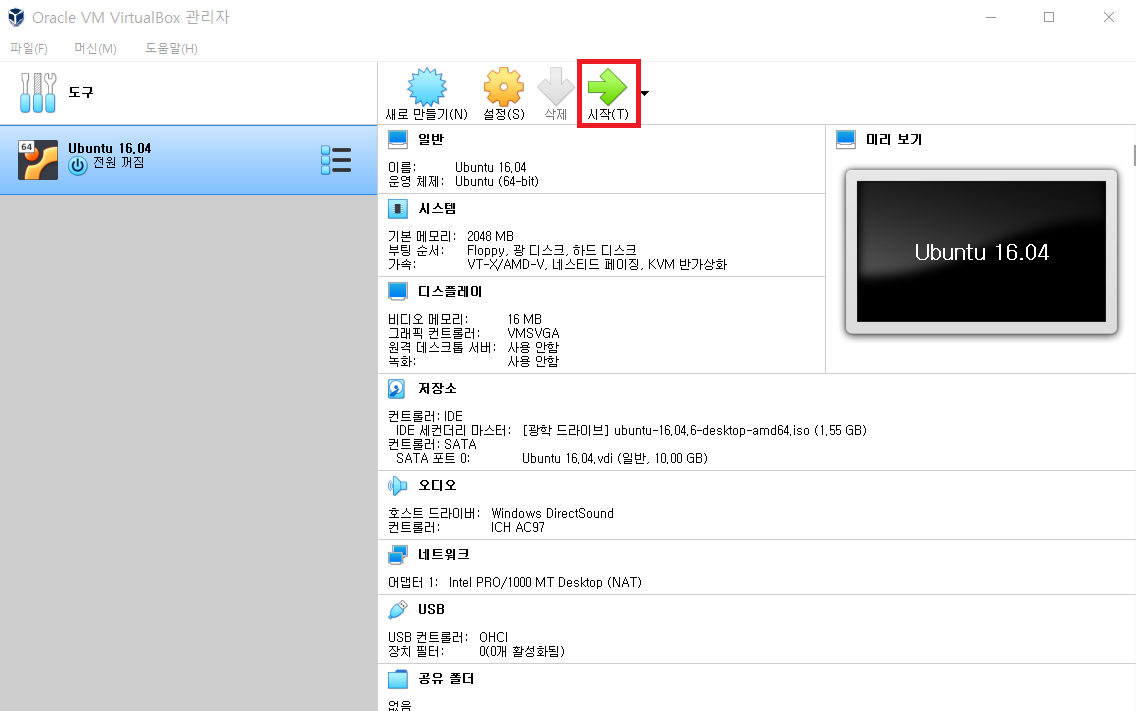
당연히 현재 가상 머신의 하드 디스크에는 실제로 우분투가 설치가 되어 있는 것은 아니므로, ISO 파일을 이용하여 이제 실제 우분투를 하드 디스크에 설치하면 된다. 따라서 [Install Ubuntu] 버튼을 클릭하여 우분투를 설치해준다.
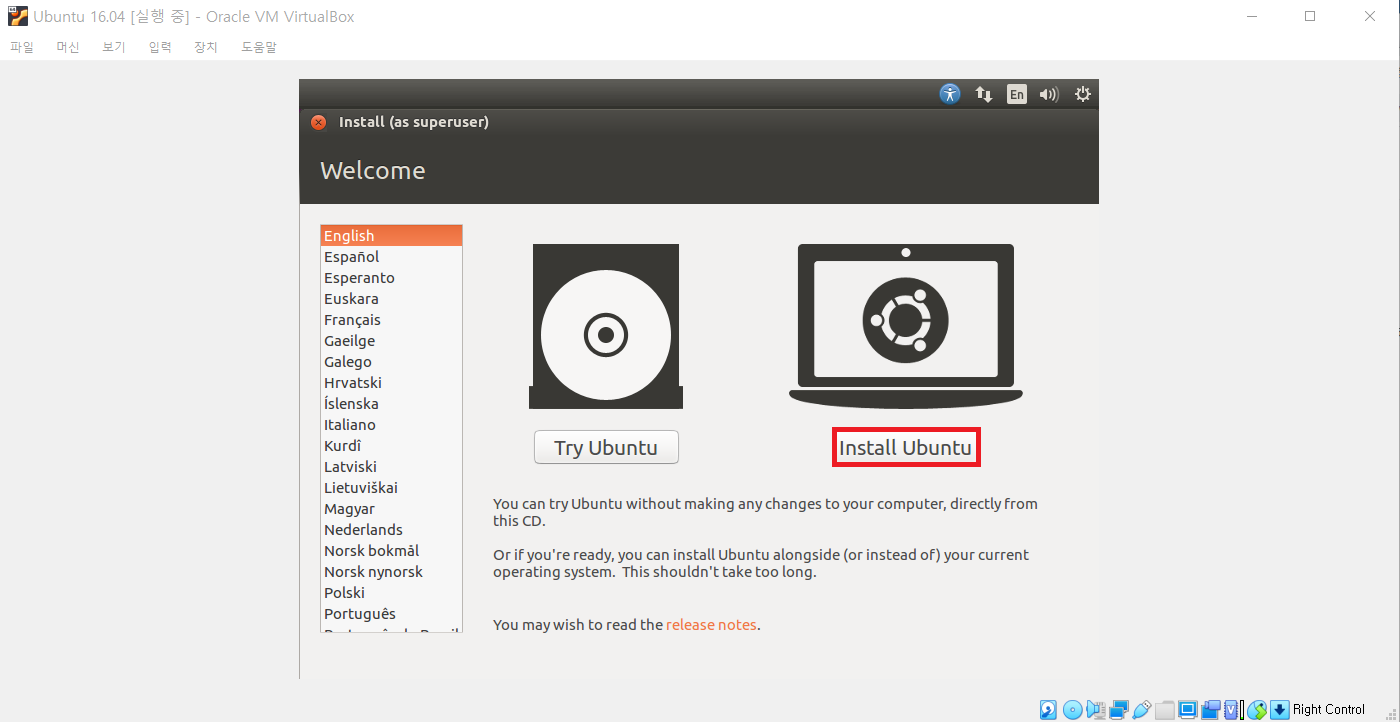
또한 우분투 설치 과정에서 자동으로 Update 파일 다운로드를 진행할 것인지 물어보는데, 어차피 나중에 대부분 설치해도 괜찮기 때문에 바로 [Continue]를 눌러서 설치를 진행해도 괜찮다.
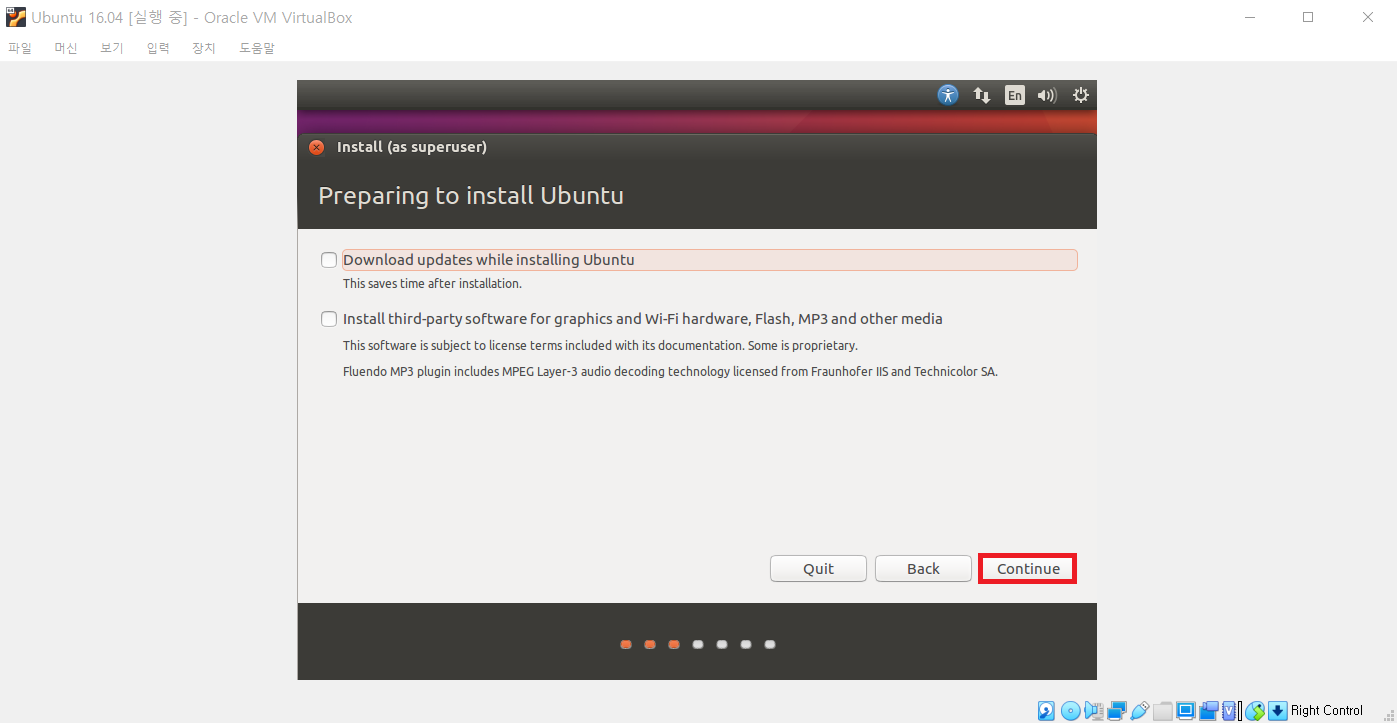
또한 우분투 OS를 설치할 떄는 기본적으로 디스크를 비운 뒤에 우분투 OS가 설치된다. 다만 여기에서 말하는 디스크란 가상 머신의 디스크 이므로, 그냥 [Install Now]를 눌러서 설치를 진행하면 된다.
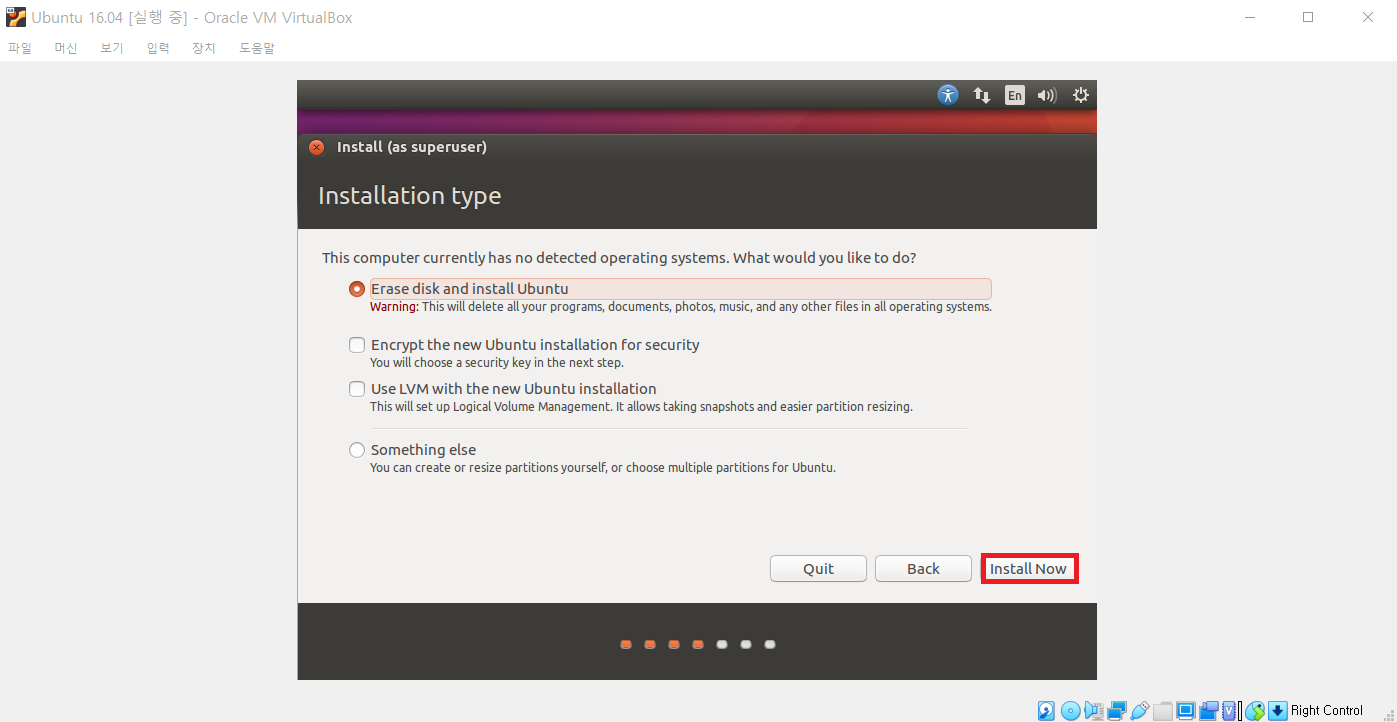
이후에 디스크 파티션 관련 내용이 나오는데 그냥 [Continue]를 눌러서 진행할 수 있다.
이후에 기본적인 날짜 설정을 위해 위치를 물어본다. 서울(Seoul)을 선택하도록 하자.
이후에 기본적인 언어(Language), 그리고 우분투 OS에서 사용할 관리자 계정의 비밀번호를 설정한 뒤에 설치를 진행하면 다음과 같은 화면이 나오면서 설치됩니다.
설치가 완료되고 나면 재시작 메시지가 나오는데, 재시작이 된 이후에는 다음과 같이 우분투가 정상적으로 실행된다.
우분투가 실행이 되면, 관리자 계정(root)으로 로그인을 해준다.
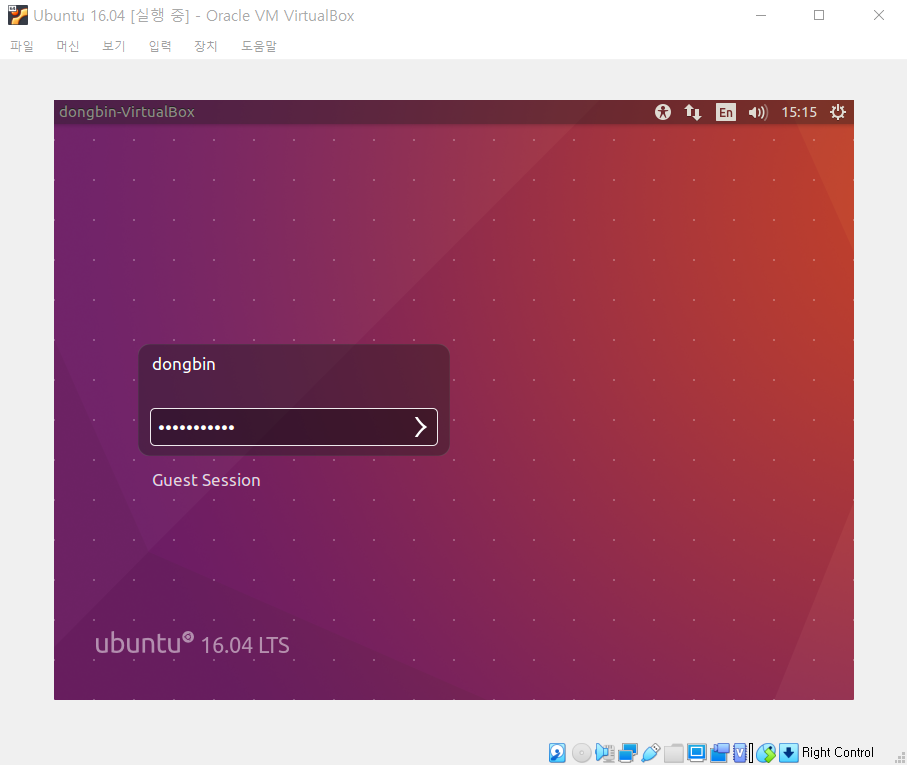
성공적으로 우분투가 실행된 모습이다.
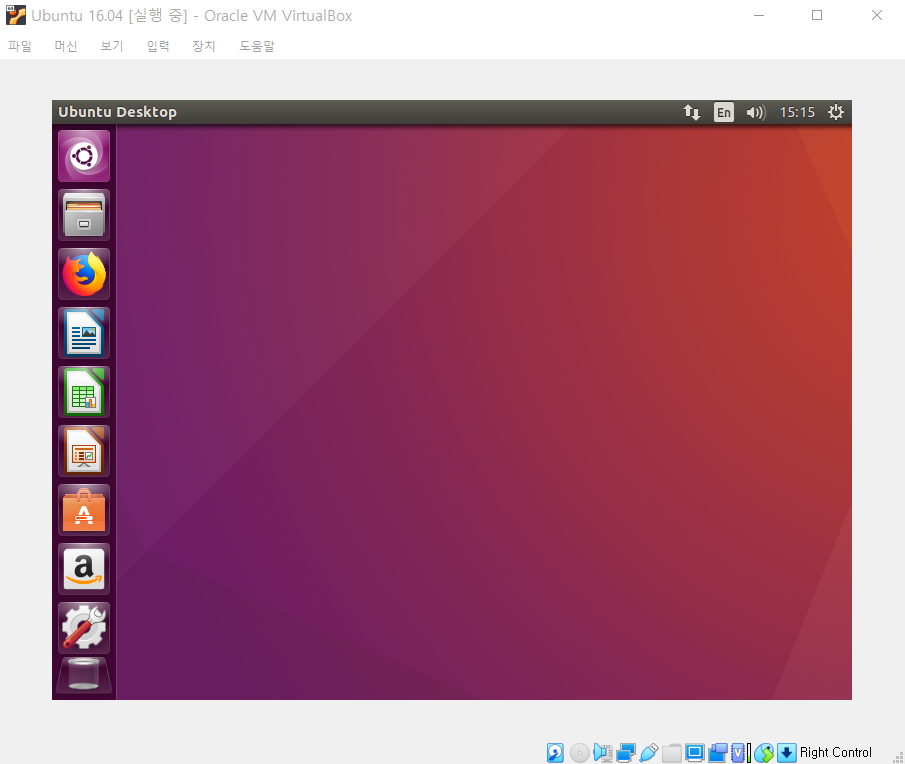
※ 흔히 발생하는 문제 1: 해상도 ※
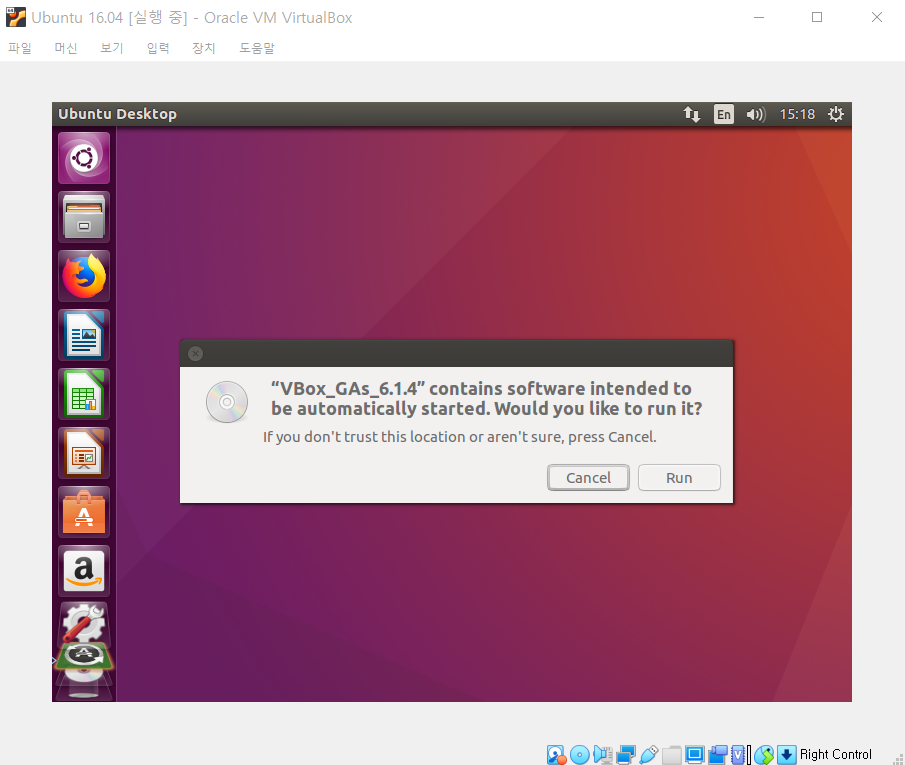
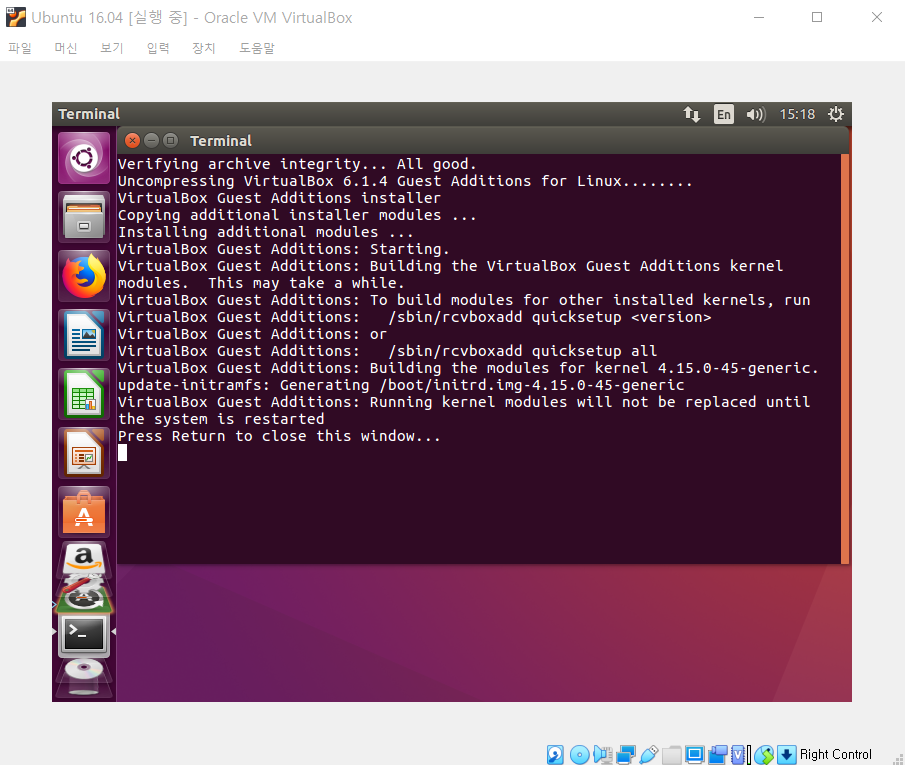
VirtualBox를 실행한 경우, 해상도가 굉장히 낮은 상태로 유지되는 경우가 있다. 이럴 때는 [장치] - [게스트 확장 CD 이미지 삽입]을 클릭한다. 이후에 소프트웨어를 설치하자. 이 과정에서 루트 계정으로 로그인을 요구할 수 있다.
설치가 완료된 이후에는 재부팅을 해주자.
이제 창의 크기에 맞게 VirtualBox의 해상도가 자동으로 조절되는 것을 확인할 수 있다.
※ 흔히 발생하는 문제 2: 클립보드 (복사, 붙여넣기) ※
VirtualBox의 가상 머신은 기본적으로 호스트 OS와 클립보드를 공유하지 않는다. 즉, 호스트 OS에서 복사된 텍스트를 게스트 OS에 붙여넣을 수 없다. 이를 위해서는 추가적인 [설정]이 필요하다.
이후에 다음과 같이 [일반] - [클립보드 공유(S)] 부분의 값을 "양방향"으로 해준다.
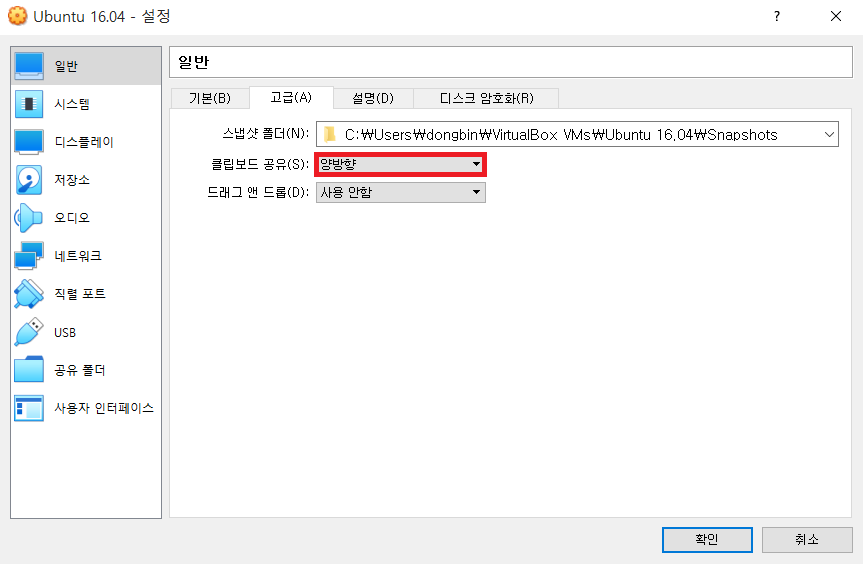
이후에 다시 가상 머신을 부팅하면, 호스트 OS에서 복사된 텍스트를 Ubuntu OS에서 [Ctrl + Shift + V]을 통하여 붙여넣기 할 수 있다. 하지만, 이렇게 해도 붙여넣기가 안 될 수도 있다. 그럴 때는 가상 머신을 삭제하고, 다시 생성하여 [클립보드 공유] 기능을 먼저 활성화 한 뒤에, 그 이후에 [게스트 확장 CD 이미지 삽입]을 해주면 해결 될 수도 있다.
※ 기본적으로 설치할 소프트웨어들 ※
일반적으로 깃(Git)과 같은 유틸리티는 많이 사용되기 때문에 미리 설치하는 것이 좋다. 이 때 우분투에서 매 번 sudo 명령을 입력하기 귀찮으면, sudo -s를 입력하여 root 계정의 권한으로 접속하도록 하자.
sudo apt install git
※ 기타 사항 ※
또한 터미널(Terminal) 상에서 현재 폴더를 GUI로 열고 싶다면, 노틸러스(Nautilus) 명령을 이용하면 된다. 다음의 명령을 입력하여 GUI 화면으로 폴더를 열 수 있다.
nautilus .
'기타' 카테고리의 다른 글
| Teensy 3.6 SD Card 다루기 예제 (0) | 2020.04.20 |
|---|---|
| Teensy를 활용해 Raw HID 소프트웨어 개발 시작하기 (0) | 2020.04.20 |
| 이전 버전의 Visual Studio를 설치하는 방법 (Visual Studio 2015) (0) | 2020.04.03 |
| 인공지능 보안(AI Security)에서 핵심이 되는 논문들 정리 및 리뷰 요약 (0) | 2020.03.30 |
| 블리자드 스타크래프트 1 무료 다운로드 및 실행 방법 (0) | 2020.03.27 |
이전 버전의 Visual Studio를 설치하는 방법 (Visual Studio 2015)
특정 분야의 개발을 진행하다 보면, 이전 버전의 Visual Studio가 필요할 때가 있다. 예를 들자면, 저자의 경우 펌웨어 개발 과정에서 Visual Studio 2015 with Update 3 버전에서의 개발 환경과 C 컴파일러가 필요했다.
하지만, 2020년 현재를 기준으로 Visual Studio 2017 이전 버전을 설치하는 것은 귀찮은 과정이며, 권장되지도 않는다. 그래서 가능하다면, 최신 버전의 Visual Studio를 이용하는 것이 좋다. 그래도 저자와 같이 어쩔 수 없이 이전 버전을 설치해야 하는 경우에는 다음의 과정을 따르도록 하자.
▶ Visual Studio 다운로드: https://my.visualstudio.com/Downloads
위 사이트에 접속하면, 아래와 같이 모든 제품군을 검색하여 설치할 수 있다. Visual Studio Community 2015를 검색한 뒤에 원하는 업데이트 버전을 골라 설치할 수 있다.
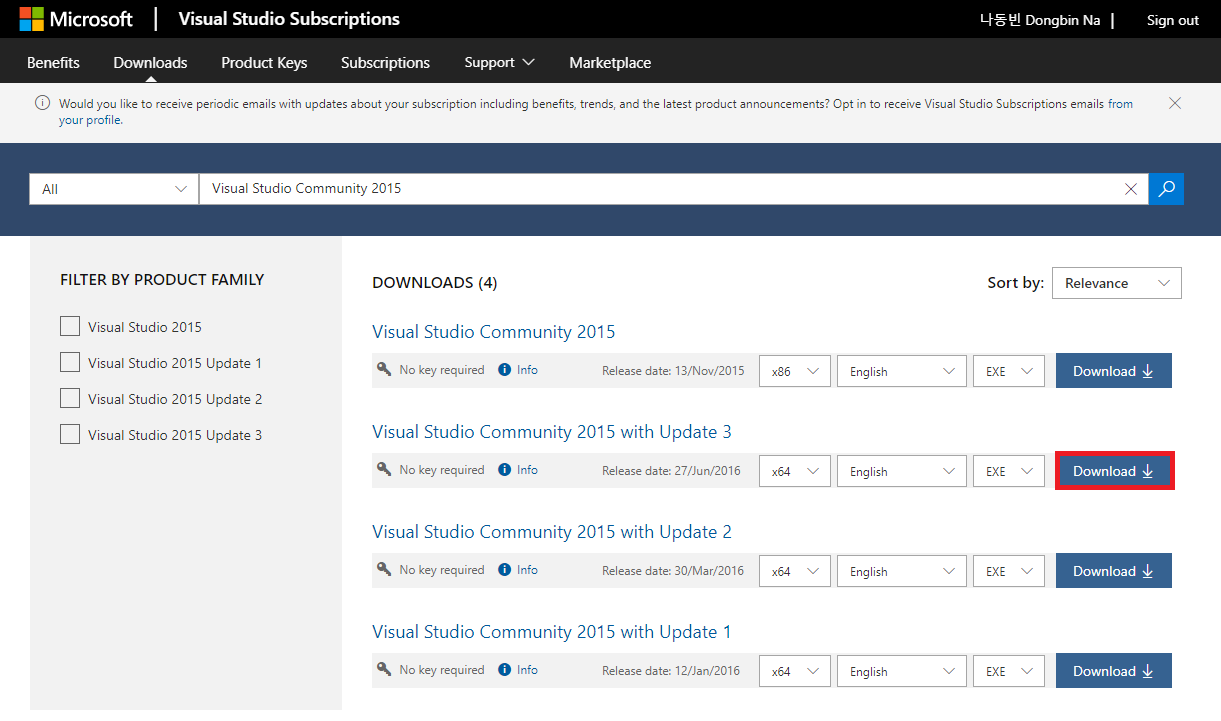
설치 프로그램 자체도 옛날 버전의 프로그램이다. 더불어 설치 시간이 매우 오래 걸리는 편이다. 저자의 경우 전체적으로 30분 가량의 시간이 소요되었다. 맨 처음에는 환경 설정(Configuration)만으로도 몇 분의 시간이 소요된다.
이후에 Visual Studio를 설치할 경로를 설정할 수 있다. 저자는 기본 설정(Default)으로 설치를 진행했다.
다음과 같이 필요한 패키지들이 설치되는 것을 확인할 수 있다.
설치가 완료되면 [LAUNCH] 버튼을 눌러서 Visual Studio를 실행할 수 있다.
결과적으로 다음과 같이 Visual Studio가 실행되는 것을 알 수 있다.
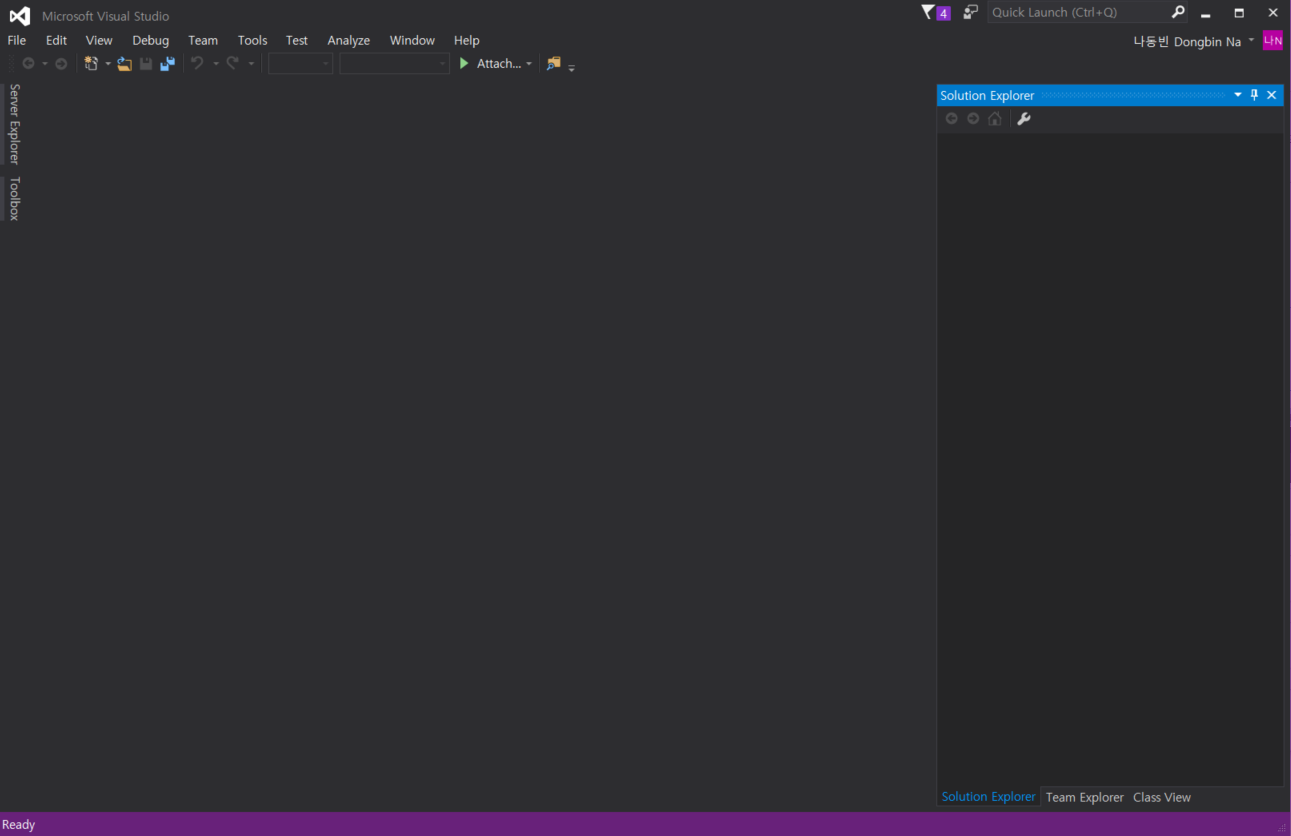
[New Project]에서 [Visual C++]로 하나의 프로젝트를 만들어 볼 수 있다. 기본적으로 C++ 개발 도구(Tools)가 설치되어 있지 않다면, C++ 개발 도구를 설치하라는 화면이 나온다.
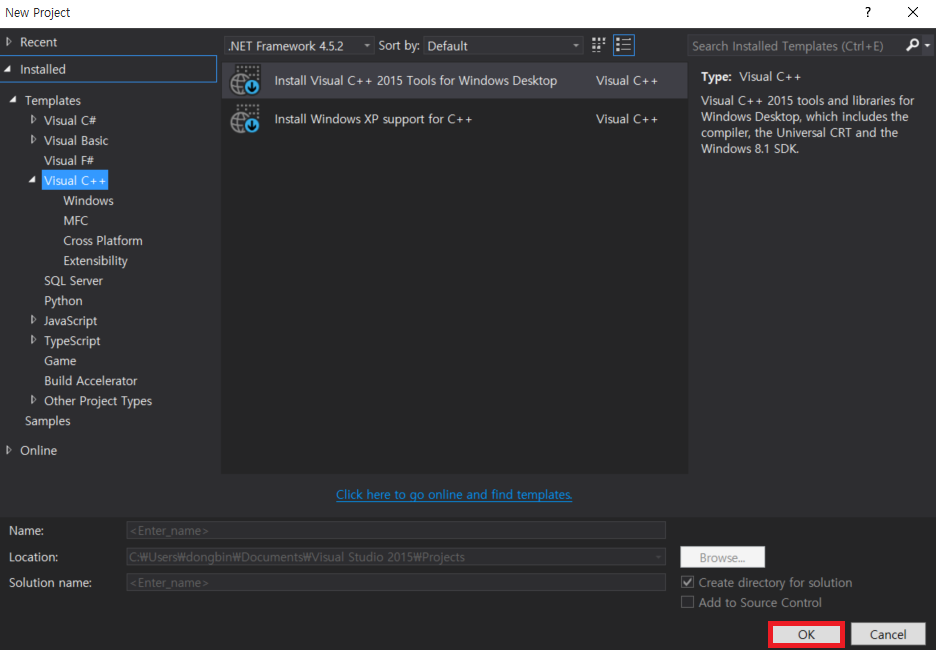
C++ 개발 도구가 설치된 이후에 [Empty Project]로 새로운 프로젝트를 생성할 수 있다.
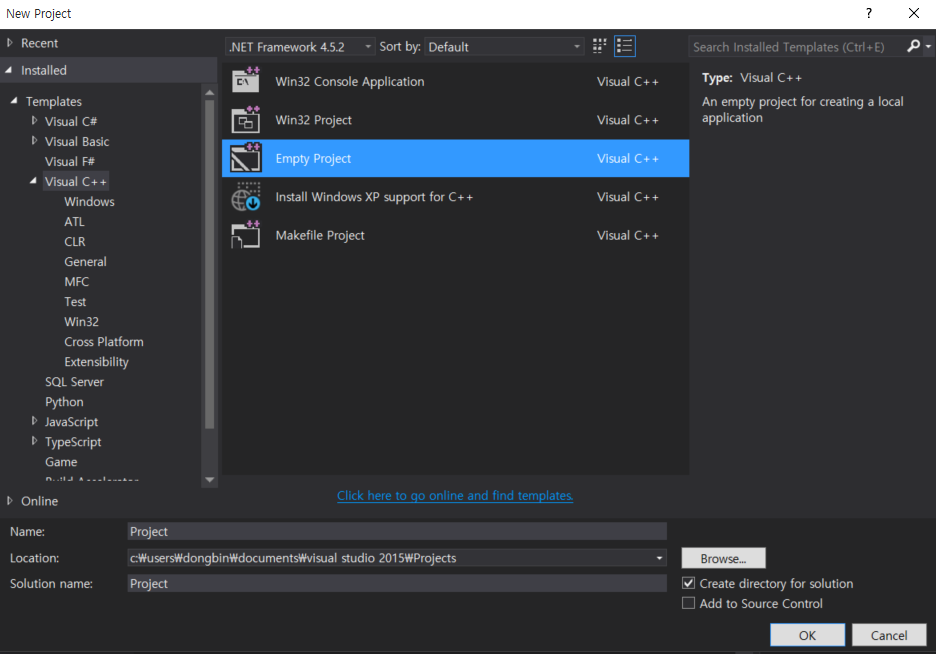
하나의 C언어 소스코드 파일을 작성한 뒤에 실행해보았더니, 잘 동작하였다.

'기타' 카테고리의 다른 글
| Teensy를 활용해 Raw HID 소프트웨어 개발 시작하기 (0) | 2020.04.20 |
|---|---|
| Windows 10 운영체제에 VirtualBox 및 우분투(Ubuntu) 설치하기 (3) | 2020.04.06 |
| 인공지능 보안(AI Security)에서 핵심이 되는 논문들 정리 및 리뷰 요약 (0) | 2020.03.30 |
| 블리자드 스타크래프트 1 무료 다운로드 및 실행 방법 (0) | 2020.03.27 |
| MinnowBoard MAX와 MinnowBoard Turbot를 위한 UEFI 펌웨어 빌드 및 업데이트 (0) | 2020.03.25 |
인공지능 보안(AI Security)에서 핵심이 되는 논문들 정리 및 리뷰 요약
인공지능 분야에는 다양한 연구 분야가 있습니다.
그 중에서, 인공지능 보안(AI Security) 분야는 주로 인공지능 모델이 가지는 보안 취약점을 해결하기 위한 연구 분야입니다. 최근 이러한 인공지능 보안(AI Security) 쪽에 관심을 가지는 분들이 많습니다.
실제로 인공지능 보안 분야의 대가 중 한 명인 Carlini가 조사한 내용에 따르면, 이미 2020년 1월 ~ 3월에 아카이브에 올라온 인공지능 보안 관련 논문만 1,000 편이 넘습니다.
참조: https://nicholas.carlini.com/writing/2019/all-adversarial-example-papers.html
A Complete List of All Adversarial Example Papers
by Nicholas Carlini 2019-06-15 It can be hard to stay up-to-date on the published papers in the field of adversarial examples, where we have seen massive growth in the number of papers written each year. I have been somewhat religiously keeping track of th
nicholas.carlini.com
이처럼 나날이 논문 등재 수가 증가하고 있으며, 인공지능 학회들(ICML, ICLR, NIPS, CVPR, ICCV 등) 및 보안 학회들(CCS, S&P, NDSS, USENIX Security 등)에서는 별도의 세션을 마련하여 인공지능 보안 분야의 논문들을 게재하고 있습니다.
국내에서도 많은 랩들이 인공지능 보안 분야로 들어오고 있는 것으로 알고 있는데요. 다른 분야에 비해서 아직 학습용 자료가 많지 않은 것 같아서, 직독직해 논문 리뷰 컨텐츠를 공유하고자 글을 남깁니다. 다음의 유튜브 링크들은, 제가 인공지능 보안 분야의 논문을 100편여 가량 이상을 읽으면서 '가장 핵심이 되는' 좋은 논문을 몇 가지 추려서 리뷰한 동영상들입니다.
아래에 제시되어 있는 7가지의 논문만 읽어도, 최신 인공지능 보안 분야의 논문들을 따라오는 데에 어려움이 없을 겁니다. 다만 제가 아래 리뷰를 진행함에 있어서 PPT를 준비하여 발표하는 것이 아니라, 직독직해 방식으로 직접 논문의 내용을 차근차근 읽어나갑니다. 그래서 꼼꼼히 공부해보려고 하시는 분들에게 더 많은 도움이 될 수 있을 것 같습니다.
1. Explaining and Harnessing Adversarial Examples (ICLR 2015)
- Adversarial Examples가 존재하는 이유(뉴럴 네트워크 모델의 선형성)에 대해서 설명
- Adversarial Examples를 빠르게 만드는 방법(FGSM)을 제안
링크: https://www.youtube.com/watch?v=99uxhAjNwps&list=PLRx0vPvlEmdBQw6kRaod33aUkJ1YHLz3Y&index=1
2. Towards Evaluating the Robustness of Neural Networks (S&P 2017)
- Norm 기반의 매우 강력한 Adversararial Examples을 만드는 방법(CW Attack)에 대해서 소개
- 기존에 존재하던 방어 기법(Defensive Distillation)의 한계점을 지적하고 뚫음
링크: https://www.youtube.com/watch?v=9kRWHKPyfwQ&list=PLRx0vPvlEmdBQw6kRaod33aUkJ1YHLz3Y&index=2
3. Towards Deep Learning Models Resistant to Adversarial Attacks (ICLR 2018)
- Adversarial Examples에 대항하기 위한 효과적인 학습 방법(PGD Adversarial Training) 제안
- 아직까지 살아 남은 몇 안 되는 휴리스틱한 방어 기법
링크: https://www.youtube.com/watch?v=6RBpdAC9nwY&list=PLRx0vPvlEmdBQw6kRaod33aUkJ1YHLz3Y&index=3
4. Adversarial Examples Are Not Bugs, They Are Features (NIPS 2019)
- Adversarial Examples을 Non-robust Features의 일종으로 보는 새로운 시각 제시
- Robust Dataset과 Non-robust Dataset을 분리할 수 있음을 보임
링크: https://www.youtube.com/watch?v=Y7O47Kq8pmU&list=PLRx0vPvlEmdBQw6kRaod33aUkJ1YHLz3Y&index=4
5. Certified Robustness to Adversarial Examples with Differential Privacy (S&P 2019)
- Differential Privacy의 개념을 이용해, 수학적으로 '증명된' Norm 기반의 방어 방법(Pixel DP) 제안
- 증명론적인 논문 중에서 상당히 읽기 쉬우며 재미있는 논문
링크: https://www.youtube.com/watch?v=ySJUlEVlXfk&list=PLRx0vPvlEmdBQw6kRaod33aUkJ1YHLz3Y&index=5
6. Obfuscated Gradients Give a False Sense of Security (ICML 2018)
- 2018년 이전에 등재된 상당수 방어 기법들이 가지는 문제점을 정리 및 지적
- Adversarial Training을 제외한 사실상 대부분의 방어 기법을 뚫음
- 미분이 불가능한 연산을 우회하여 뚫는 BPDA 제안
링크: https://www.youtube.com/watch?v=0O_Bxln9bTw&list=PLRx0vPvlEmdBQw6kRaod33aUkJ1YHLz3Y&index=6
7. Constructing Unrestricted Adversarial Examples with Generative Models (NIPS 2018)
- Norm 기반이 아닌 제약 조건이 없는(Unrestricted) 공격을 제안
- 기존에 존재하던 강력한 방어 방법(Adversarial Training, Certifed Defense 등)을 뚫음
링크: https://www.youtube.com/watch?v=IDtaVjJoV4g&list=PLRx0vPvlEmdBQw6kRaod33aUkJ1YHLz3Y&index=7
'기타' 카테고리의 다른 글
| Windows 10 운영체제에 VirtualBox 및 우분투(Ubuntu) 설치하기 (3) | 2020.04.06 |
|---|---|
| 이전 버전의 Visual Studio를 설치하는 방법 (Visual Studio 2015) (0) | 2020.04.03 |
| 블리자드 스타크래프트 1 무료 다운로드 및 실행 방법 (0) | 2020.03.27 |
| MinnowBoard MAX와 MinnowBoard Turbot를 위한 UEFI 펌웨어 빌드 및 업데이트 (0) | 2020.03.25 |
| 윈도우(Windows)에서 CMake 설치하는 방법 (1) | 2020.02.11 |
블리자드 스타크래프트 1 무료 다운로드 및 실행 방법
이제는 블리자드(Blizzard) 스타크래프트를 무료로 다운로드 할 수 있습니다. 블리자드 계정만 있으면 바로 설치하여, 게임을 즐기실 수 있습니다. 다운로드를 위해서는 블리자드 스타크래프트 공식 웹 사이트에 접속하셔야 합니다.
▶ 블리자드 스타크래프트 공식 웹 사이트: https://kr.shop.battle.net/ko-kr/product/starcraft
https://kr.shop.battle.net/ko-kr/product/starcraft
kr.shop.battle.net
접속하신 뒤에는 [무료로 플레이하기] 버튼을 누르셔서 스타크래프트를 바로 설치하실 수 있습니다.
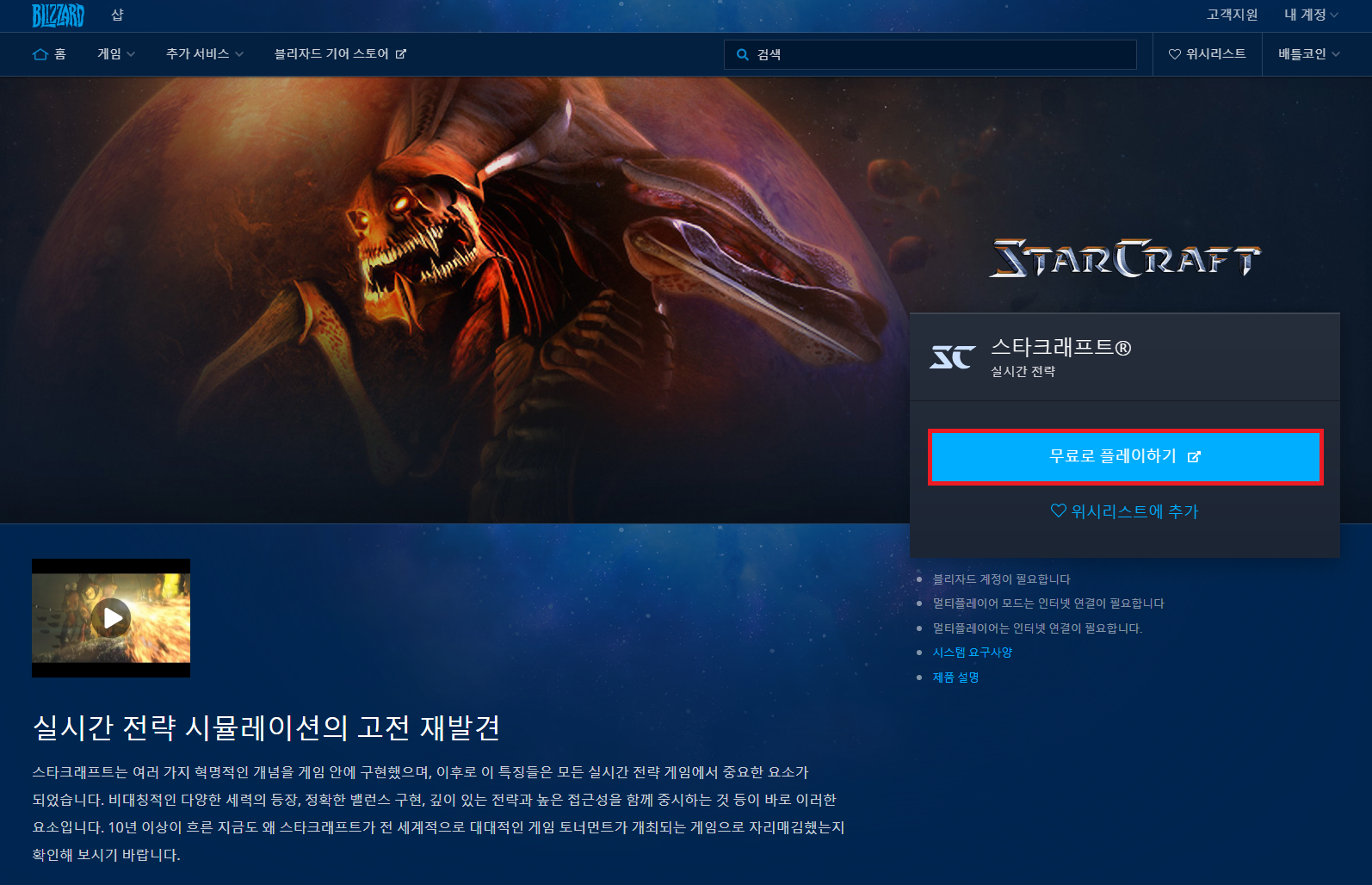
설치하실 때는 [클래식 게임] - [스타크래프트] - [PC]를 눌러서 설치 프로그램을 다운로드 받아줍니다.
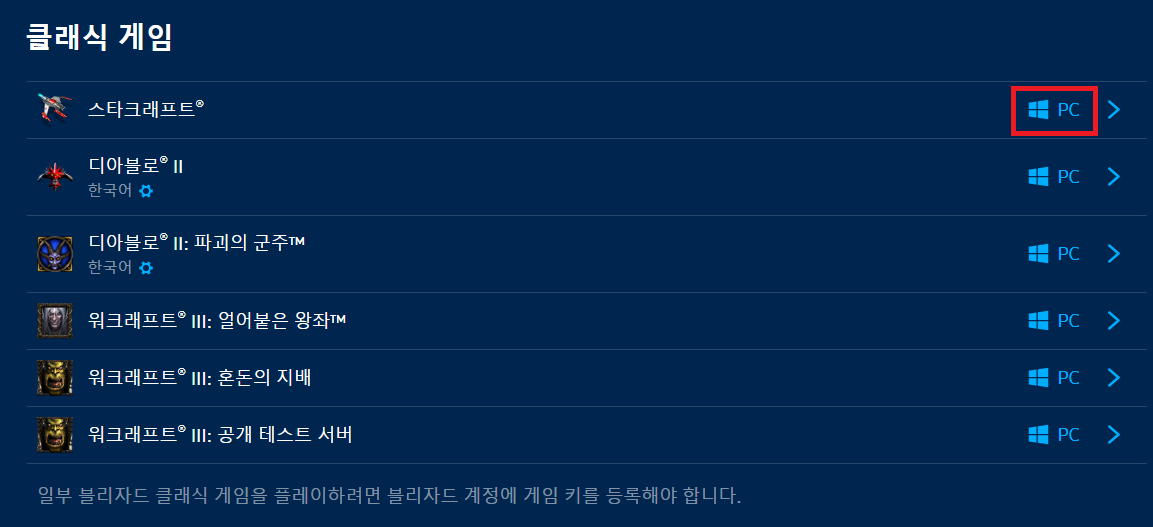
설치 프로그램을 실행하면, 먼저 언어를 선택해야 합니다.
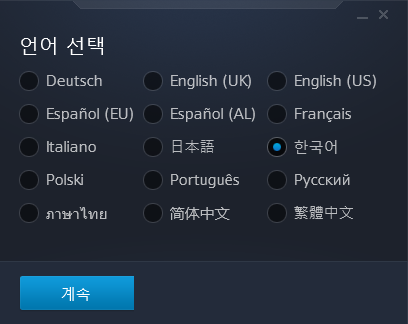
다음과 같이 기본적인 설정 그대로 스타크래프트 설치를 진행해주세요.
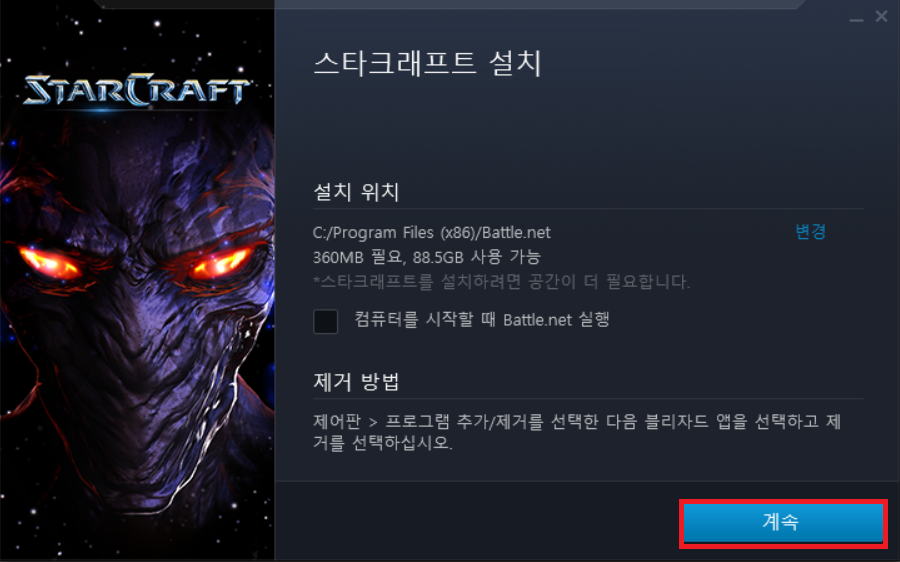
기본적으로 블리자드 계정을 통해서 로그인을 해야만 게임에 접속하실 수 있습니다. 따라서 블리자드 계정이 없으시다면 회원가입을 먼저 하시고, 로그인을 진행해주세요.

이후에 스타크래프트가 설치되어 있지 않은 PC라면, 스타크래프트 설치 메시지가 나옵니다. 결과적으로 설치가 다 완료되면 다음과 같이 [게임 실행] 버튼을 눌러서 실행하실 수 있습니다.

실행 화면은 다음과 같습니다.
'기타' 카테고리의 다른 글
| 이전 버전의 Visual Studio를 설치하는 방법 (Visual Studio 2015) (0) | 2020.04.03 |
|---|---|
| 인공지능 보안(AI Security)에서 핵심이 되는 논문들 정리 및 리뷰 요약 (0) | 2020.03.30 |
| MinnowBoard MAX와 MinnowBoard Turbot를 위한 UEFI 펌웨어 빌드 및 업데이트 (0) | 2020.03.25 |
| 윈도우(Windows)에서 CMake 설치하는 방법 (1) | 2020.02.11 |
| 윈도우(Windows)에서 MinGW 설치 방법 (0) | 2020.02.11 |
MinnowBoard MAX와 MinnowBoard Turbot를 위한 UEFI 펌웨어 빌드 및 업데이트
최근 MinnowBoard를 이용하여 프로젝트를 진행하고 있는데, UEFI 펌웨어를 수정해서 업로드를 해야하는 일이 생겼다. EDK2는 크로스 플랫폼 펌웨어 개발 환경이다. UEFI 명세를 따르고 있기 때문에, 이를 이용하여 UEFI 펌웨어 개발을 진행할 수 있다. 특히 EDK2는 MinnowBoard를 지원한다는 점이 특징이다. 그래서 EDK2 개발 환경을 이용하여 MinnowBoard UEFI 업데이트를 진행하고자 한다.
기본적으로 인텔(Intel)에서 공식적으로 제공하고 있는 문서는 다음과 같다.
https://software.intel.com/en-us/articles/minnowboard-maxturbot-uefi-firmware
MinnowBoard MAX* and MinnowBoard Turbot* - UEFI Firmware
MinnowBoard MAX* and MinnowBoard Turbot* firmware releases that include functional and security updates.
software.intel.com
기본적으로 문서에서 요구하는 대로 진행하면 어려움 없이 UEFI 펌웨어가 빌드(Build) 되기는 하지만, 개발환경에 따라서 조금씩 시행착오가 있을 수 있다. 따라서, 본인은 EDK2 UEFI 펌웨어를 개발할 때 개인 PC 개발환경을 이용하는 것보다는 Ubuntu 16.04 가상머신을 이용하는 것을 추천한다.
※ UEFI 펌웨어 개발 환경 구축 ※
웬만하면 구름(Goorm IDE) 서비스를 이용하여 Ubuntu 16.04 LTS 운영체제의 개발 환경을 이용하자. 빈 프로젝트(Blank Project)로 시작하는 것이 깔끔하며, 기본적으로 gcc 5.4 버전이 설치되어 있어서 바로 사용할 수 있다. 이후에 다음과 같은 과정을 따르면 된다.
1) 워크스페이스 경로로 이동
일단 EDK2 개발 환경으로 이용할 워크스페이스 폴더를 생성한다. 이러한 워크스페이스 폴더에 프로젝트 파일을 옮겨서 개발을 진행할 것이다. 따라서 가장 먼저 워크스페이스 폴더를 생성하고 그 폴더로 이동하자. 이후에 다음의 과정을 따라가면 된다.
2) EDK2 소스코드 다운로드
git clone https://github.com/tianocore/edk2.git -b UDK2017
cd edk2
git checkout vUDK2017
cd ..
3) EDK2 MinnowBoard 플랫폼 소스코드 다운로드
git clone https://github.com/tianocore/edk2-platforms.git -b devel-MinnowBoardMax-UDK2017
cd edk2-platforms
git checkout 2a5f80b862e46de213a3f3635c43394deacdfb05
cd ..
4) BaseTools 바이너리 다운로드
git clone https://github.com/tianocore/edk2-BaseTools-win32.git
cd edk2-BaseTools-win32
git checkout 0e088c19ab31fccd1d2f55d9e4fe0314b57c0097
cd ..
5) 바이너리 오브젝트 모듈 설치
일단 워크스페이스 경로에 'silicon' 이라는 이름의 폴더를 생성한다. 이후에 다음의 웹 사이트에 접속한 뒤에 "MinnowBoard_MAX-1.01-Binary.Objects.zip"를 설치하여 압축을 풀어준다.
http://firmware.intel.com/projects/minnowboard-max
압축 폴더 안에 포함된 다음의 세 폴더를 워크스페이스 내 'silicon' 폴더 안으로 옮긴다. (구름 IDE를 이용하는 경우, 압축 파일을 옮겨서 해결할 수 있다.)
IA32FamilyCpuPkg
Vlv2BinaryPkg
Vlv2MiscBinariesPkg
결과적으로 최종적인 워크스페이스 내 폴더 구성은 다음과 같다.
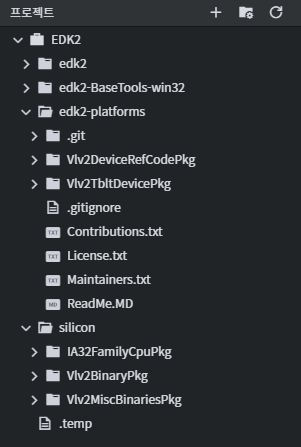
※ 리눅스 환경에서 빌드 ※
이제 Ubuntu 16.04 환경에서 EDK2 프로젝트를 빌드(Build)하는 방법을 자세히 알아보도록 하자. 일단 필수적인 패키지들을 설치하여, 빌드 환경을 구축한다.
sudo apt-get update
sudo apt-get install build-essential
sudo apt-get install uuid-dev
sudo apt-get install git
만약에 패키지 리스트 업데이트 과정에서 공개키 관련 오류가 발생한다면 다음과 같이 키 설정을 해준다.
gpg --keyserver keyserver.ubuntu.com --recv 5DC22404A6F9F1CA
gpg --export --armor 5DC22404A6F9F1CA | sudo apt-key add -
이후에 필요한 라이브러리들을 설치해준다. (UEFI 펌웨어 빌드를 위해 꼭 필요한 라이브러리들이다.) 구체적으로 NASM와 ACPICA를 설치해주어야 하는데, 두 가지 방법이 있다.
1) NASM 및 ACPICA 설치 첫 번째 방법
다음의 네 명령어를 이용하면, 간단히 설치를 진행할 수 있다.
sudo apt-get install nasm
sudo apt-get install bison
sudo apt-get install flex
sudo apt-get install acpica-tools
2) NASM 및 ACPICA 설치 두 번째 방법
여기에서 소개할 방법은 인텔 공식 문서에 기재되어 있는 방법이다. 먼저 NASM을 설치한다. 이를 위해 다음의 공식 사이트에 접속하자.
https://www.nasm.us/pub/nasm/releasebuilds/2.12.02
위 사이트에 접속한 뒤에 nasm-2.12.02.tar.gz 파일을 다운로드해서 임의의 폴더에 압축을 풀어준다. (구름 IDE로 옮길 때, 잘 안 옮겨진다면 .zip 파일로 변경해서 옮겨보자.) 이후에 nasm 도구를 설치할 것이다. 다만 만약에 폴더에 Makefile.in 파일만 존재하고, Makefile이 없는 경우 Makefile.in 파일을 Makefile로 변경해주면 된다.
chmod +x configure
sudo ./configure
sudo make
sudo make install
설치가 완료된 이후에는 nasm --v를 입력하여 설치된 NASM의 버전을 확인할 수 있다. 이제 ACPICA를 설치한다. 다음의 공식 사이트에 접속하자.
https://acpica.org/downloads
위 사이트에 접속한 뒤에 acpica-unix-20170728.tar.gz 파일을 다운로드해서 임의의 폴더에 압축을 풀어준다. 이제 bison과 flex를 설치한다.
sudo apt-get install bison flex
이후에 ACPICA를 설치할 수 있다.
sudo make clean
sudo make iasl
sudo make install
참고로 이러한 과정에서 nasm 및 acpica-tools 라이브러리를 반드시 제대로 설치해주어야 한다. 라이브러리가 설치되어 있지 않은 경우, 빌드 과정에서 특정한 프로그램 혹은 파일을 찾을 수 없다는 오류가 발생할 수 있다.
※ UEFI 빌드를 위한 OpenSSL 설치 ※
cd /워크스페이스/edk2/CryptoPkg/Library/OpensslLib/
git clone https://github.com/openssl/openssl openssl
cd openssl
git checkout OpenSSL_1_1_0e
이 과정에서 openssl 폴더로 들어간 뒤에 checkout 명령을 이용해 반드시 버전을 변경해야 한다. 그러면, 요구하는 특정한 .c 파일이 없다는 메시지가 나오며 빌드에 실패하게 된다.
※ 빌드 진행 ※
1) 먼저 빌드에 필요한 스크립트 및 바이너리 파일을 실행 가능하도록 설정한다.
chmod +x /워크스페이스/edk2/edksetup.sh
chmod -R 777 /워크스페이스/edk2/BaseTools/
cd /워크스페이스/edk2-platforms/Vlv2TbltDevicePkg
chmod +x bld_vlv.sh Build_IFWI.sh GenBiosId
2) 릴리즈(Release) 모드로 빌드를 진행한다.
cd /워크스페이스/edk2-platforms/Vlv2TbltDevicePkg
. Build_IFWI.sh MNW2 Release
릴리즈 모드로 빌드를 하면, 8MB 크기의 .bin 파일이 생성된다. 이제 이 파일을 MinnowBoard로 옮긴 뒤에 실제로 MinnowBoard에서 플래시(Flash)를 진행하면 된다.
※ 펌웨어 업로드 및 플래시(Flash) ※
실제로 빌드가 된 펌웨어 바이너리(Binary) 파일을 플래시하기 위해서는 두 가지가 필요하다.
① 펌웨어 업데이트 유틸 ② 펌웨어 바이너리 파일
따라서 가장 먼저, 아래 사이트에 접속하여 펌웨어 업데이트 유틸을 다운로드 해준다.
https://software.intel.com/en-us/articles/minnowboard-maxturbot-uefi-firmware
이제 UEFI Shell에 접속한 뒤에, 펌웨어 업데이트 유틸을 이용하여 업데이트를 진행하면 된다. 기본적으로 MinnowBoard에 전원을 공급하여, 모니터를 연결하면 UEFI Shell로 접속하게 된다. 이 때, MinnowBoard에 USB나 SD Card를 삽입하면 해당 파일 시스템에 접속할 수 있게 된다.
일반적으로 fs0 번호로 파일 시스템이 적용되므로, UEFI Shell에서 fs0:을 입력한다. 이후에 ls를 입력하여 펌웨어 업데이트 유틸, 펌웨어 바이너리 파일을 확인하자. 이제 해당 유틸을 이용하여 펌웨어 업데이트를 진행하면 된다. 자세한 내용은 아래 문서를 참고하자.
https://software.intel.com/sites/default/files/managed/4e/e1/using-the-minnowboard-max-flash-utility-1.1.pdf
※ 참고해야 할 사항 ※
기본적으로 펌웨어 프로그램이 제대로 빌드(Build)되지 않는다고 하더라도 Stitch 폴더 안에는 .bin 파일이 생성된다. 다만, 제대로 펌웨어 프로그램이 만들어지지 않은 경우에는 펌웨어 프로그램의 크기가 8MB가 아니게 된다.
심지어 저자의 경우에는 빌드 과정에서 경고(warning) 메시지만 나오고 오류(error) 메시지는 나오지 않았음에도 만들어진 펌웨어 프로그램의 크기가 7MB였다. 이처럼 기본적으로 인텔(Intel) 문서상에 명시되어 있는 툴 체인의 버전을 최대한 맞춘다고 하더라도, 빌드 오류를 만나거나 빌드 결과가 잘못 될 수 있다는 점을 기억하자.
결과적으로 저자의 경우 리눅스 환경을 버리고, 인텔 문서에서 제공하고 있는 윈도우 빌드 환경을 따랐다. (마찬가지로 윈도우 버전의 가이드를 그대로 따라가면 된다. Visual Studio 2015를 설치해야 하는 것을 제외하고는, 리눅스 빌드 환경과 사실상 동일하다. 다만 Visual Studio가 미리 설치되어 있는 컴퓨터인 경우에는 기존의 Visual Studio를 완전히 삭제해 버리고, Visual Studio 2015 Update 3 버전을 재설치 해주어야 한다.)
아무튼 윈도우에서 빌드를 수행하니, 성공적으로 8MB 의 펌웨어 파일이 만들어졌고, 빌드가 된 펌웨어 파일과 펌웨어 업데이트 유틸리티를 USB에 담아서 미노보드에 꽂아 실행해보았다. 결과적으로 펌웨어 업데이트는 다음과 같이 성공적으로 수행되었다.
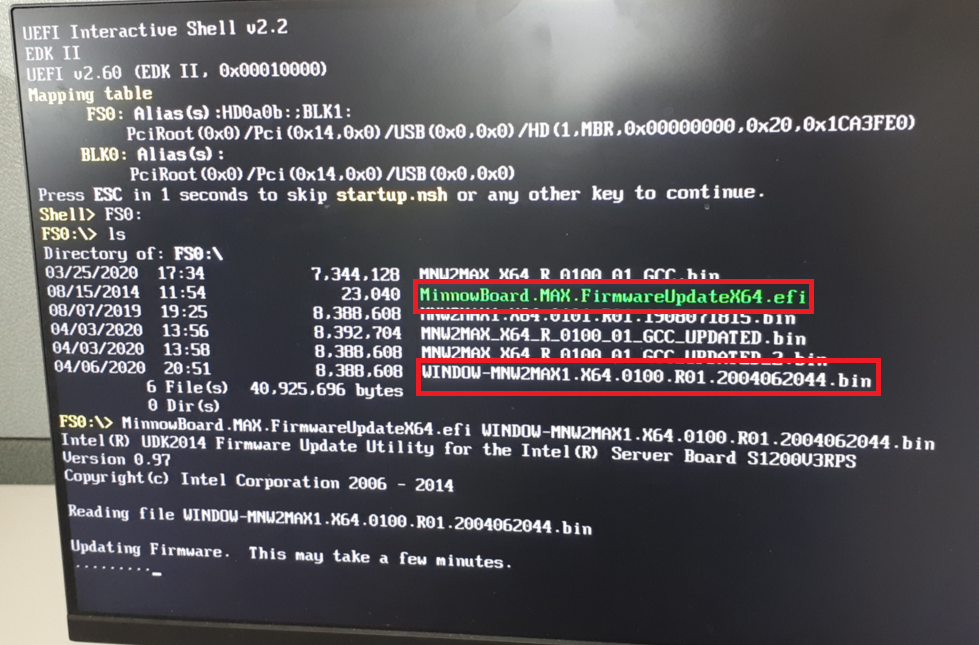
'기타' 카테고리의 다른 글
| 인공지능 보안(AI Security)에서 핵심이 되는 논문들 정리 및 리뷰 요약 (0) | 2020.03.30 |
|---|---|
| 블리자드 스타크래프트 1 무료 다운로드 및 실행 방법 (0) | 2020.03.27 |
| 윈도우(Windows)에서 CMake 설치하는 방법 (1) | 2020.02.11 |
| 윈도우(Windows)에서 MinGW 설치 방법 (0) | 2020.02.11 |
| 윈도우(Windows)에서 Zephyr OS 개발환경 구축하여 시작하기 (2) | 2020.02.11 |
윈도우(Windows)에서 CMake 설치하는 방법
C언어 프로젝트는 빌드(Build)를 위한 순서를 Makefile을 이용해서 명시하곤 합니다. 이를 더욱 간단하게 만들기 위해서 CMake라는 도구가 도입되었습니다. 다시 말해 CMake는 대표적인 C/C++ 프로젝트 빌드(Build) 도구입니다. 흔히 어떤 오픈소스 프로젝트를 빌드하거나 할 때 CMake를 이용하여 빌드했던 경험을 떠올려보세요.
윈도우(Windows)에서 CMake를 설치하는 방법은 간단합니다. 가장 먼저 CMake의 공식 홈페이지에서 다운로드 페이지로 접속합니다.
▶ 설치 경로: https://cmake.org/download/
저는 윈도우(Windows) 운영체제를 이용하고 있으므로 윈도우 버전으로 설치했습니다.

설치 과정에서는 기본적으로 [Next] 버튼을 눌러서 쭉 설치를 진행하시면 됩니다.
또한 CMake를 언제 어디서든 이용할 수 있도록 하기 위해서 시스템 경로(System Path)에 추가할 수 있도록 합니다.
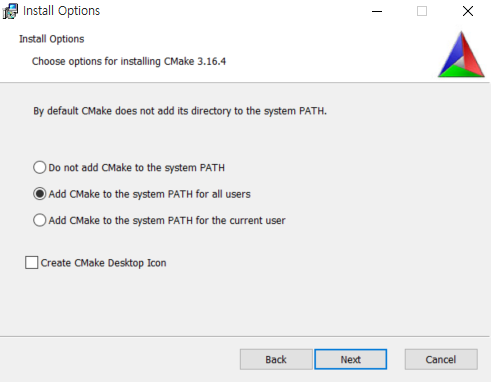
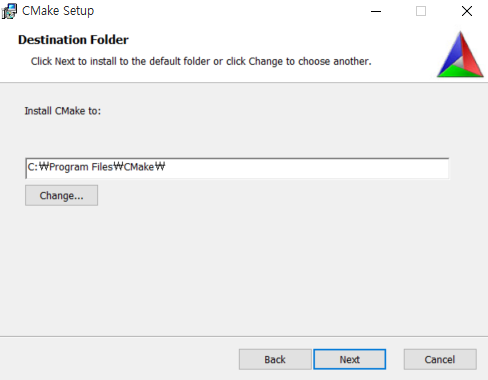

설치가 완료되었습니다.
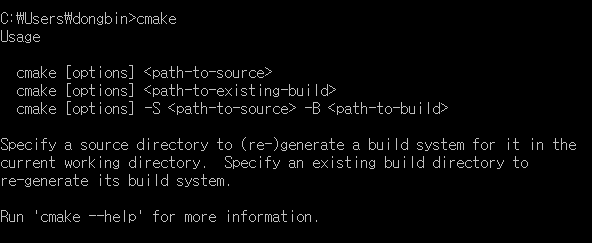
설치 이후에는 다음과 같이 명령 프롬프트(CMD)에서 cmake 명령을 입력하면 사용 방법(Usage)에 대한 내용이 등장합니다.
'기타' 카테고리의 다른 글
| 블리자드 스타크래프트 1 무료 다운로드 및 실행 방법 (0) | 2020.03.27 |
|---|---|
| MinnowBoard MAX와 MinnowBoard Turbot를 위한 UEFI 펌웨어 빌드 및 업데이트 (0) | 2020.03.25 |
| 윈도우(Windows)에서 MinGW 설치 방법 (0) | 2020.02.11 |
| 윈도우(Windows)에서 Zephyr OS 개발환경 구축하여 시작하기 (2) | 2020.02.11 |
| Visual Studio 2017 이전 버전 다운로드 (0) | 2020.02.11 |
윈도우(Windows)에서 MinGW 설치 방법
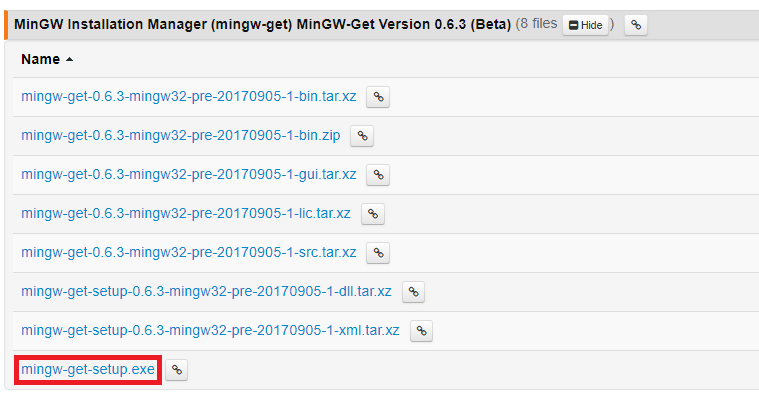
2020년 02월 기준으로 최신 MinGW 설치 프로그램은 다음의 경로에서 설치 가능하다.
https://osdn.net/projects/mingw/releases/68260
mingw-get-setup.exe 파일을 다운로드 받아서 설치를 진행하면 된다.
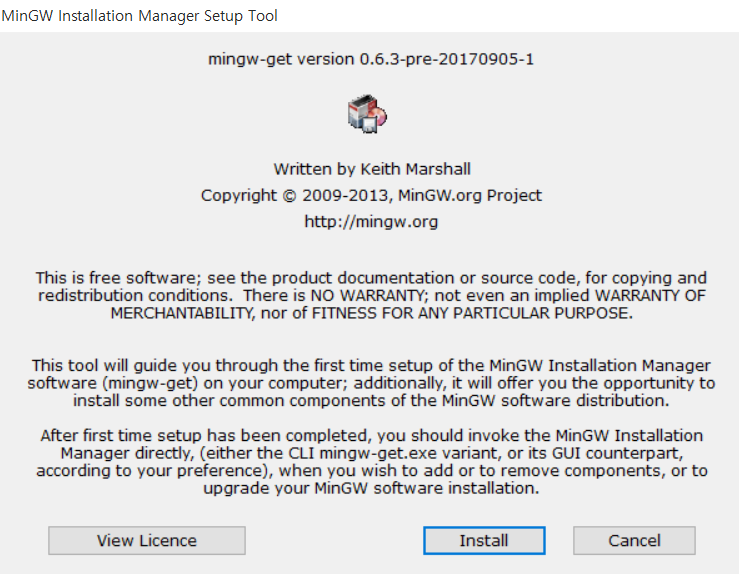
기본적인 설정 그대로 설치를 진행한다.
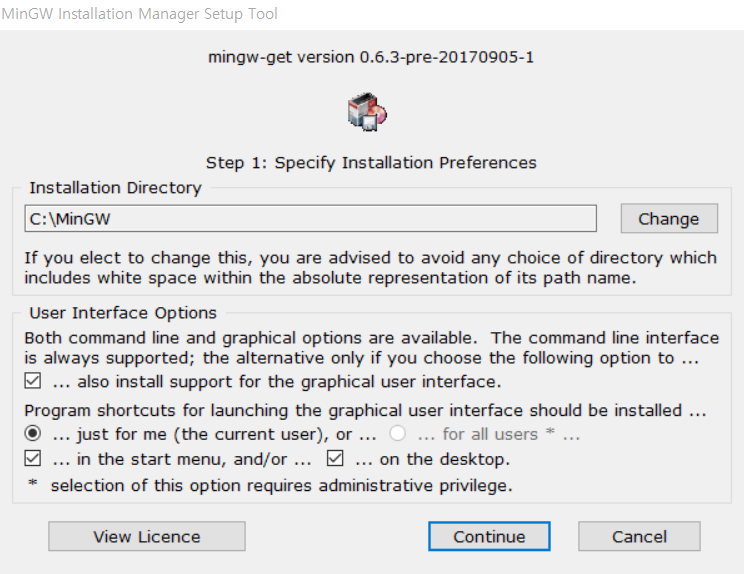
기본 설정 그대로 진행한다.
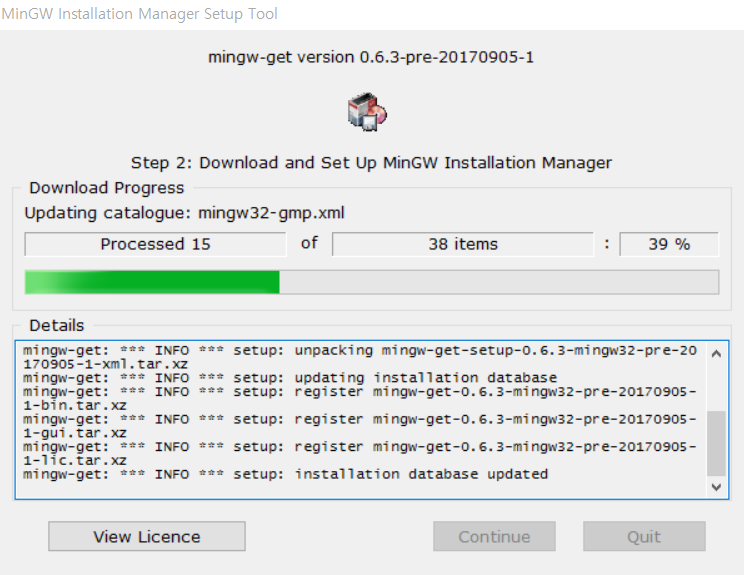
일반적으로 Basic Setup으로 설치를 진행하는데, 보이는 패키지를 모두 선택해서 설치하도록 해준다.
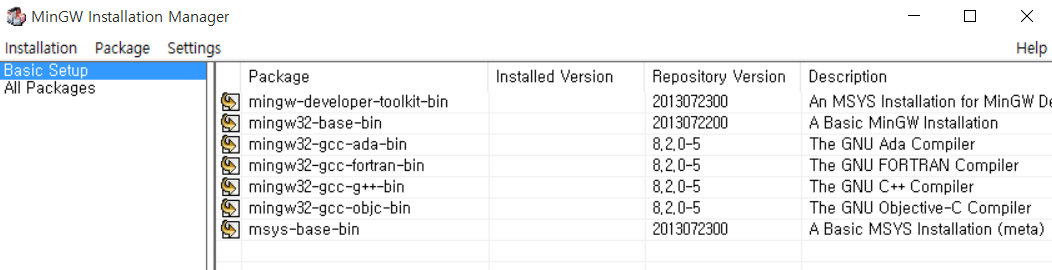
이제 [Installation] - [Apply Changes]를 눌러 설치를 진행한다.
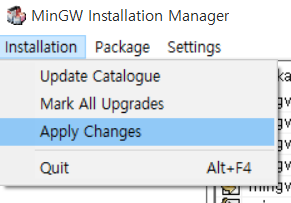
[Apply]를 눌러 설치한다.
설치가 진행되고 있는 모습이다.
[시스템] - [고급 시스템 설정] - [환경 변수] - [시스템 변수] - [Path] 변수 선택 및 C:\MinGW\bin 경로 추가
이후에 gcc -v 명령어를 입력하면 다음과 같이 GCC가 성공적으로 설치된 것을 확인할 수 있다.
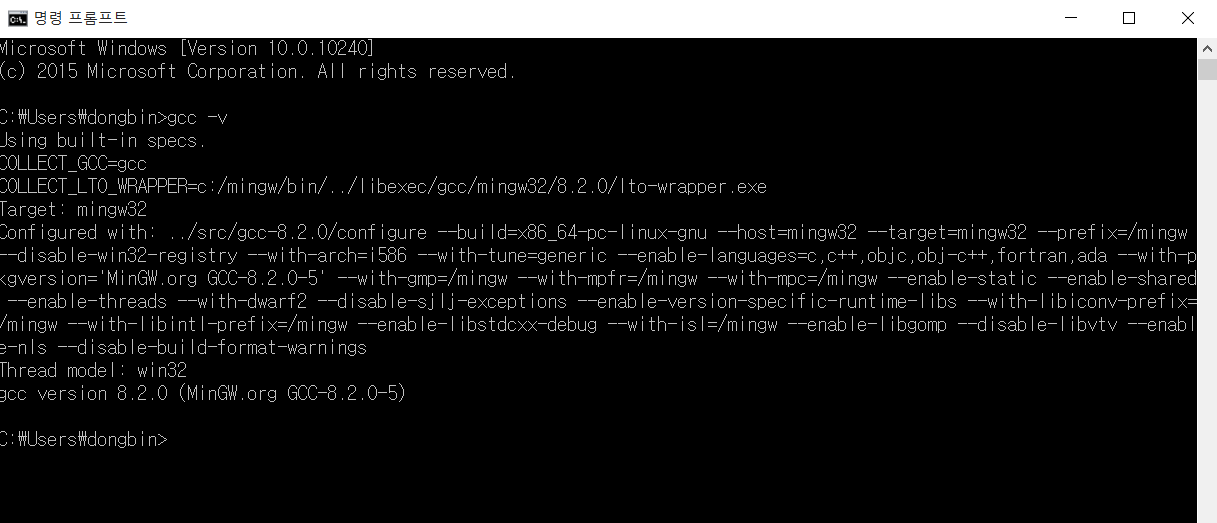
'기타' 카테고리의 다른 글
| MinnowBoard MAX와 MinnowBoard Turbot를 위한 UEFI 펌웨어 빌드 및 업데이트 (0) | 2020.03.25 |
|---|---|
| 윈도우(Windows)에서 CMake 설치하는 방법 (1) | 2020.02.11 |
| 윈도우(Windows)에서 Zephyr OS 개발환경 구축하여 시작하기 (2) | 2020.02.11 |
| Visual Studio 2017 이전 버전 다운로드 (0) | 2020.02.11 |
| DeepFakes 소프트웨어: FaceSwap을 이용해 추출한 얼굴로 학습하기(Training) (4) | 2020.02.06 |
윈도우(Windows)에서 Zephyr OS 개발환경 구축하여 시작하기
Zephyr Project의 소스코드를 받아서 보드(Board)에 올리기 위해서는, 기본적으로 Zephyr Project 개발 환경을 구축해야 합니다. "Getting Started" 페이지로 이동하면 상세한 설명이 나와 있습니다. 또한 Zephyr Project는 다양한 운영체제에서 구동시킬 수 있다는 점이 장점입니다. 저자의 경우 윈도우에서 개발환경을 구축하고자 하여, 윈도우에서의 진행 방법을 포스팅하고자 합니다.
▶ 프로젝트 시작 가이드: https://docs.zephyrproject.org/latest/getting_started/
기본적으로 프로젝트 시작을 위한 종속성 패키지를 설치하기 위하여 Chocolatey를 설치할 필요가 있습니다. Chocolatey는 Windows 운영체제 전용 패키지 매니저로, 다양한 소프트웨어를 검색하고 손쉽게 설치 및 업그레이드할 수 있도록 해줍니다. 파이썬에서의 패키지 관리 도구(PIP)나 리눅스에서의 다양한 패키지 관리 도구를 떠올리시면 Chocolatey가 어떤 역할을 하는지 이해되실 겁니다. 설치 이후에는 choco라는 커맨드를 이용해 명령을 날릴 수 있습니다.
일단 Choco를 설치하기 위하여 가장 먼저 PowerShell을 우클릭한 뒤에 [관리자 권한으로 실행] 버튼을 눌러 관리자 권한으로 실행합니다.

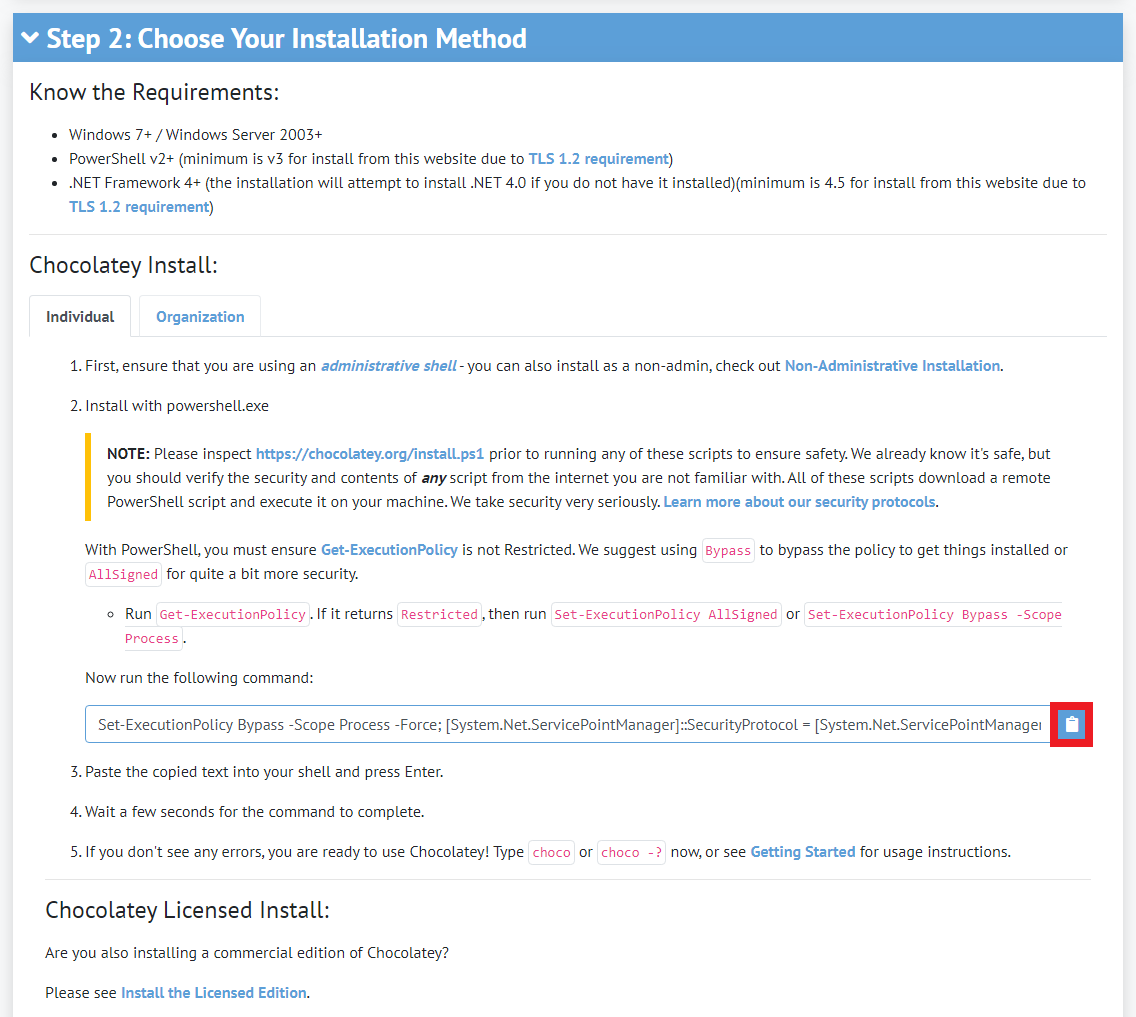
Chocolatey 설치 페이지에서 나와 있듯이 아래와 같은 명령어(Command)를 복사하여 PowerShell에 붙여넣기 해줍시다.
Set-ExecutionPolicy Bypass -Scope Process -Force; [System.Net.ServicePointManager]::SecurityProtocol = [System.Net.ServicePointManager]::SecurityProtocol -bor 3072; iex ((New-Object System.Net.WebClient).DownloadString('https://chocolatey.org/install.ps1'))아래 그림에서 설명으로 나와있듯이, 설치 과정에서 참고해야하는 다양한 사항들이 적혀 있습니다.
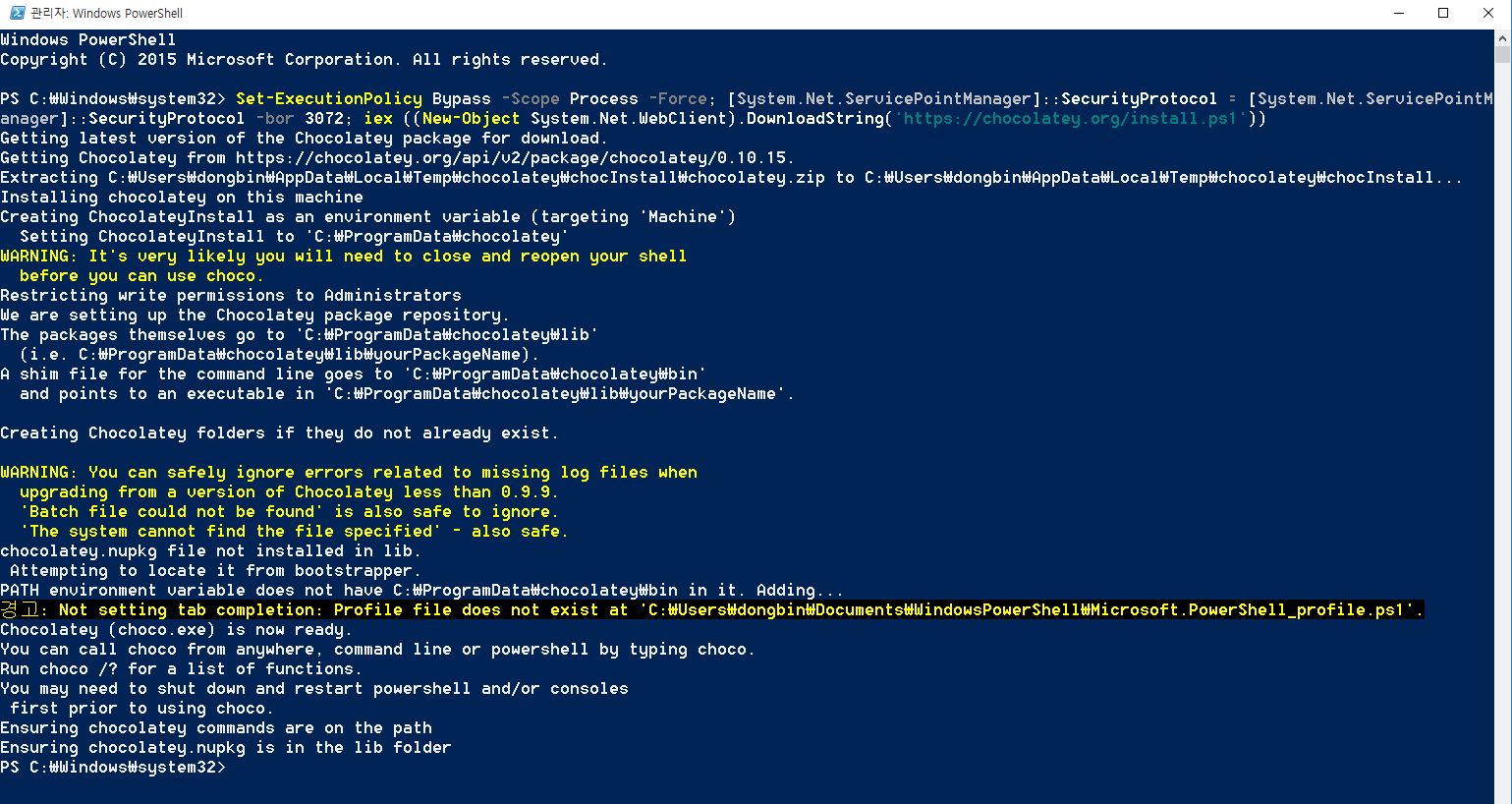
아무튼 명령어를 입력하면 다음과 같이 설치가 완료됩니다. 저는 경고 메시지가 등장했지만, 일단 귀찮으니까 넘어가겠습니다. (큰 문제 없이 진행되므로 일단 무시했습니다.)
아무튼 설치 이후에, PowerShell에서 choco 명령을 입력했을 때 다음과 같이 버전이 출력이 된다면 정상적으로 설치가 된 것입니다.

이후에 설치된 choco 패키지 매니저를 이용하여, 명령어들을 하나씩 입력하여 설치를 진행합니다. 총 4개의 명령어를 입력하게 되면 차례대로 git, python, ninja와 같은 도구(Tools)들이 설치가 됩니다. 이후에 최종적으로 west를 설치하도록 유도하고 있습니다. 한 번 따라가 보겠습니다.
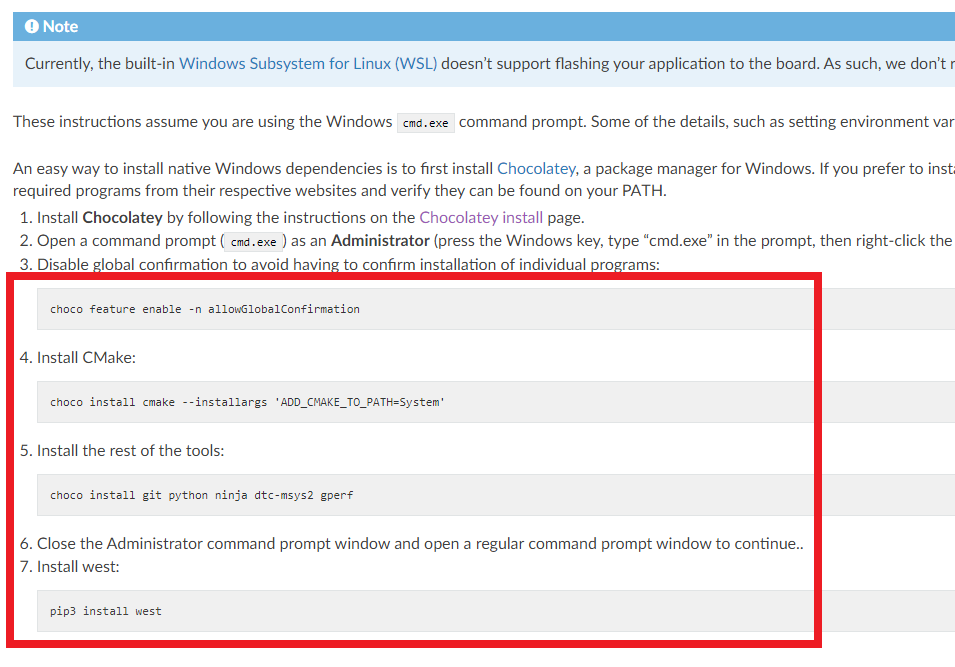
저자의 경우 모든 도구가 이미 설치가 되어 있는 상태라서 다음과 같이 출력이 되는 것을 알 수 있는데, 처음 설치하는 경우 모든 패키지를 설치하는 과정에서 몇 분 가량이 소요됩니다.
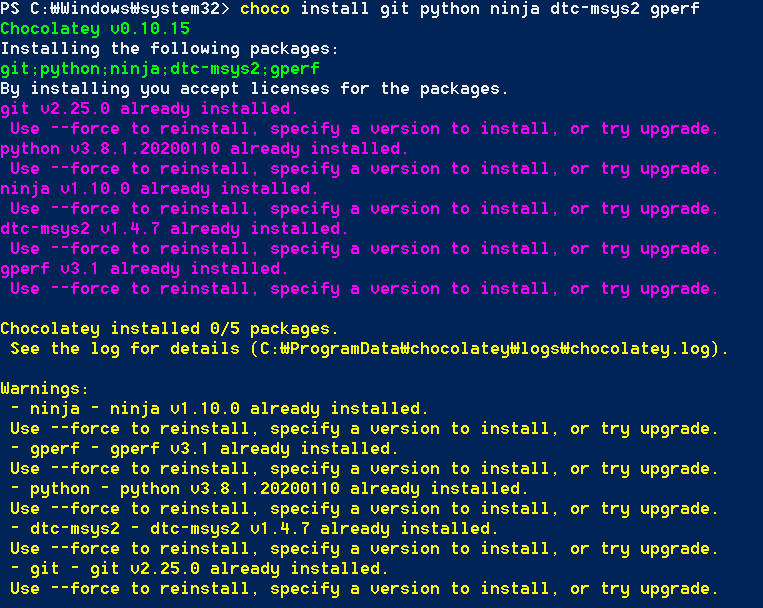
또한 저자는 다음과 같이 파이썬(Python) 3.8 버전이 설치가 되었으나, Python 3.8 버전의 사용을 원치 않았습니다. 또한 Python 3.8 버전 설치 이후에 pip 명령이 정상적으로 동작하지 않아서 다음의 명령어를 통해 Python 3.8 버전을 제거한 뒤에 Python 3.7 버전을 설치했습니다.
choco uninstall python
choco install python --version=3.7.2 이후에 시스템 변수에서 path 변수에 있는 Python 3.8 버전의 경로를 제거한 뒤에, 새롭게 설치된 Python 3.7 버전의 설치 경로를 넣어주었습니다. 아무튼 설치가 잘 되었는지를 확인하기 위해 python 및 git 명령을 실행해보고, 정상적으로 설치가 되었는지를 추가적으로 확인해주세요.
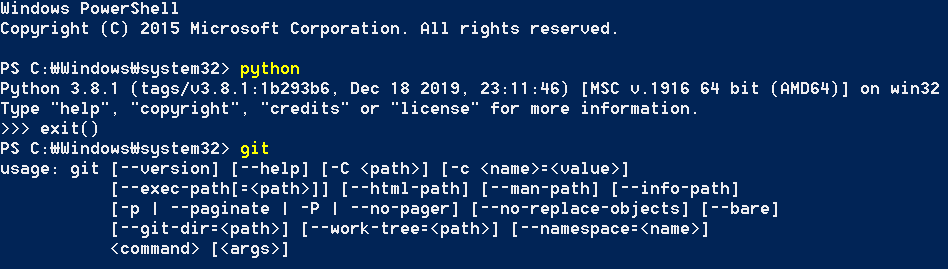
그리고 아무튼 west까지 잘 설치되었다면 성공입니다.
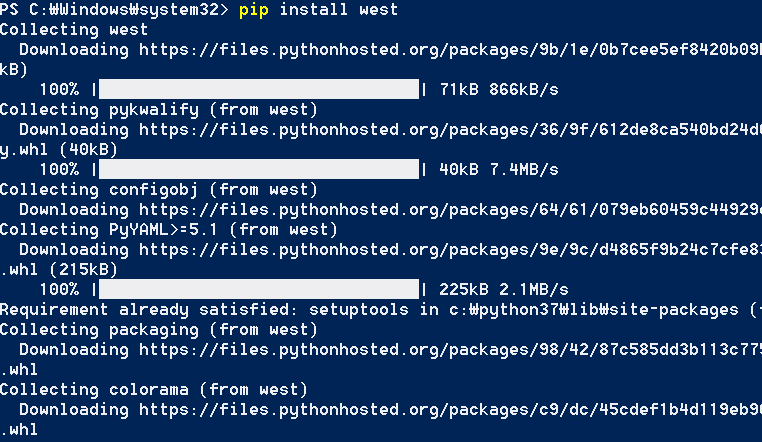
저자의 경우 위 과정에서 설치한 Python 및 Git이 이상하게도 정상적으로 동작하지 않아서 고생했습니다. 잘 안 되면 그냥 Python이나 Git을 따로 설치해서 시스템 변수에 잘 넣어주기만 해도 동작하는 것 같습니다.
※ Zephyr Project 소스코드 불러오기 ※
이제 다음 그림에서 나오는 명령어들을 이용하여 Zephyr Project의 소스코드를 불러올 수 있습니다. 이 때 git을 포함하여 아까 설치했던 도구들 중에서 제대로 설치가 안 된 것이 있다면 오류가 발생할 수 있습니다. 애초에 west 명령을 이용해도, 실제로는 git clone 명령을 이용해서 Zephyr Project 소스코드를 받아오는 것이기 때문입니다.
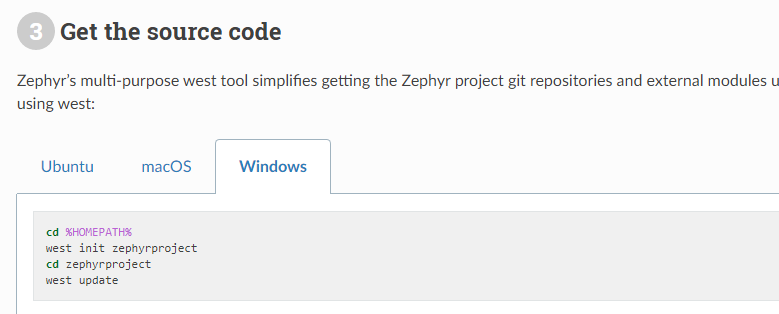
실제로 아래 명령어 중에서 west init zephyrproject 부분을 통해, 전체 Zephyr Project 소스코드를 원하는 폴더에 다운로드 받게 됩니다.
cd '원하는 폴더'
west init zephyrproject
cd zephyrproject
west update※ 필요한 파이썬 패키지 설치 ※
이후에 zephyr 소스코드 폴더의 scripts 폴더로 이동하여 필요한 패키지를 모두 설치하시면 됩니다.
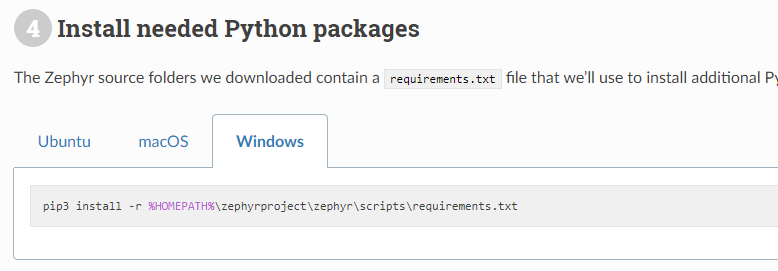
따라서 저는 웹 사이트에서 소개하고 있는대로 scripts 폴더로 이동하여 모든 관련 패키지를 설치해주었습니다.
※ 소프트웨어 개발 툴 체인 설치 ※
또한 소프트웨어 개발 툴 체인(Tool Chain)을 설치해야 합니다. Tool Chain이 설치되어 있어야 정상적으로 컴파일러, 어셈블러, 링커 및 종속성 라이브러리들을 포함하여 Zephyr 애플리케이션을 빌드할 수 있습니다. 다만 기본적으로 Zephyr SDK는 윈도우 운영체제를 지원하지 않기 때문에 윈도우에서 이러한 기능을 이용하기 위해서는 3rd-party toolchain을 설치해야 합니다.
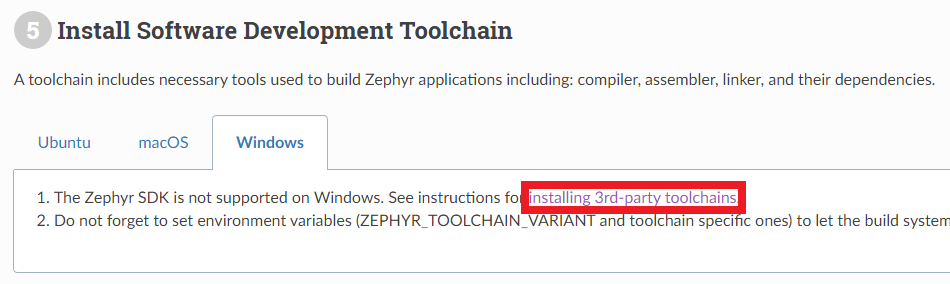
제가 대상으로 하는 보드(Board)는 Arm Cortex-M7 core 기반이기 때문에, 저는 GNU ARM Embedded 툴 체인을 설치했습니다.
공식 GNU ARM Embedded 설치 경로로 이동하여 설치합니다.
[Downloads] 버튼을 눌러 설치를 진행할 수 있었습니다.

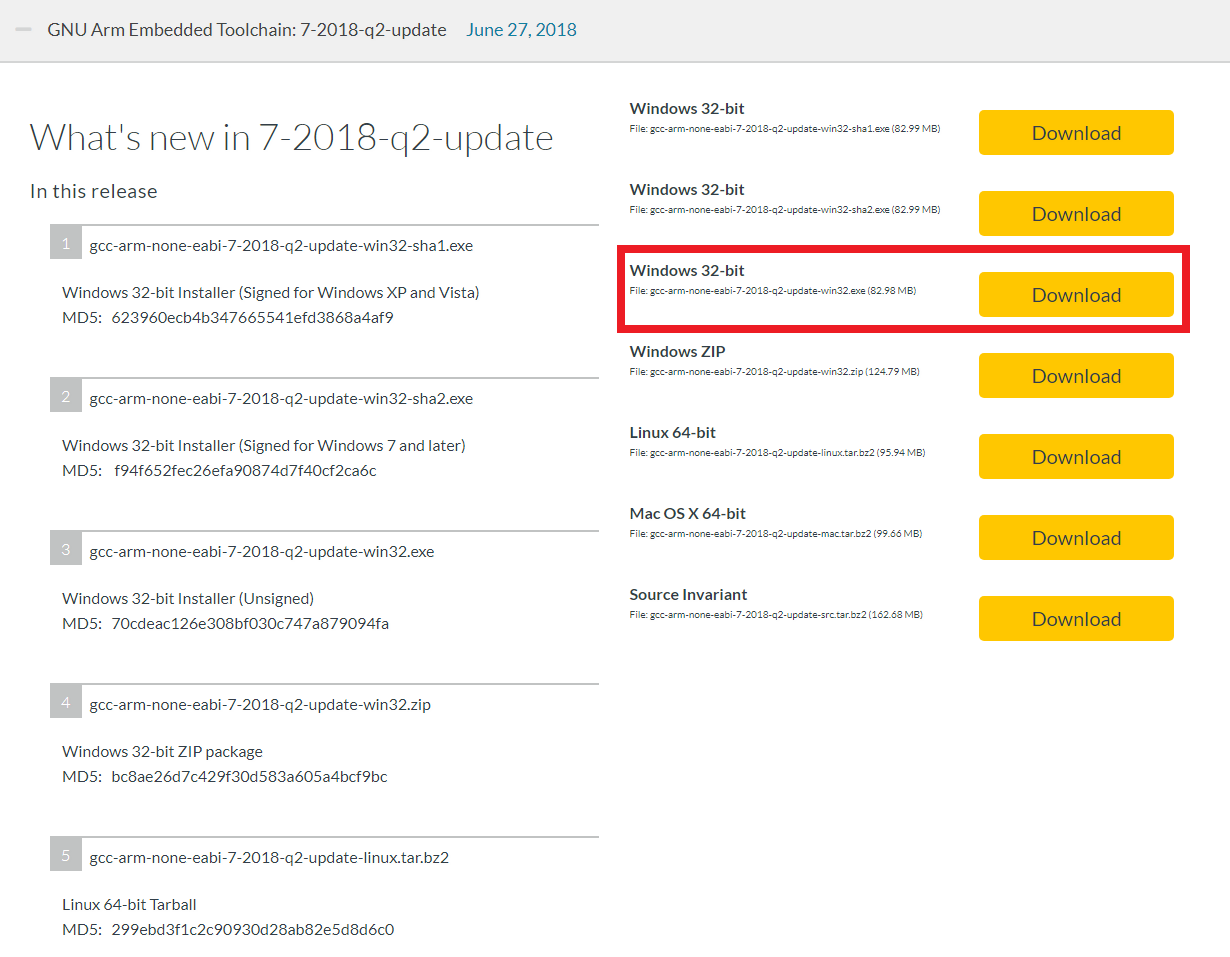
Zephyr Project 커뮤니티에 의하면 7-2018-q2-update 버전이 오류 없이 정상적으로 동작한다고 합니다. 따라서 저는 Windows 10을 이용하고 있으므로 다음과 같은 Windows 32-bit 버전을 다운로드 하였습니다.
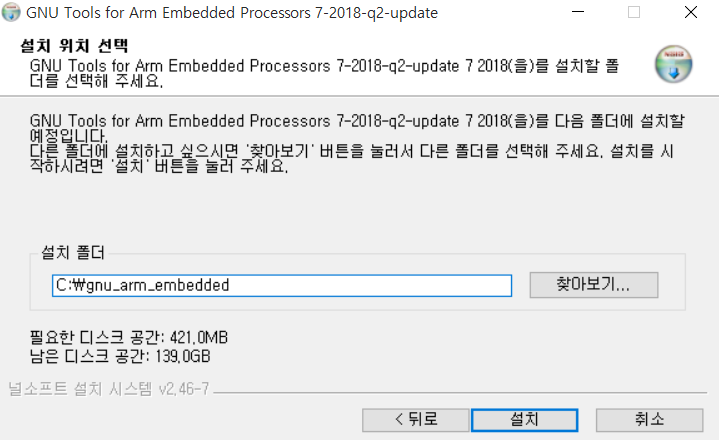
다음과 같이 설치를 완료했습니다. 참고로 설치할 때는 설치 폴더에 공백이 들어가지 않도록 그냥 C 드라이브와 같은 곳에 그대로 설치를 진행해주세요.
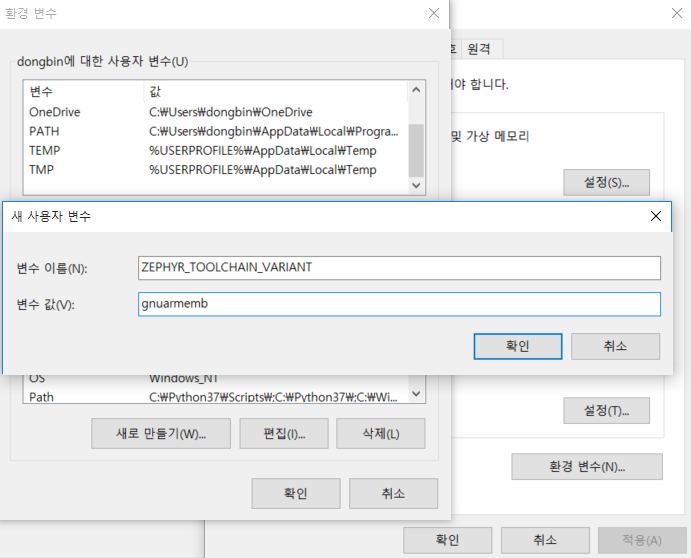
이후에 환경 변수 설정을 해줍니다. 웹 사이트에서는 두 개의 환경 변수(Environment Variables)들을 넣어주어야 한다고 하네요.
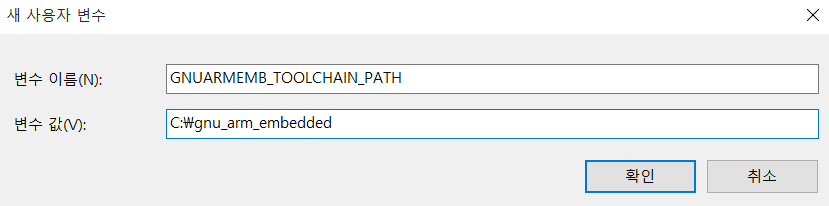
ZEPHYR_TOOLCHAIN_VARIANT: gnuarmemb
GNUARMEMB_TOOLCHAIN_PATH: 툴 체인이 설치된 경로따라서 저는 문서에서 요구하는 대로 다음과 같이 추가해주었습니다.
※ Blinky Application 빌드하기 ※
이제 Blinky Application을 빌드할 수 있습니다.
제가 쓰고 있는 보드는 STM32 Nucleo F767ZI 보드이기 때문에 다음과 같이 명령어를 입력했습니다.
cd '해당 폴더'/zephyrproject/zephyr
./zephyr-env.cmd
west --zephyr-base ./ build -p auto -b nucleo_f767zi samples/basic/blinky▶ 가능한 오류 상황 1) GCC 관련 오류
저는 다음과 같이 C Compiler와 CXX Compiler를 찾지 못하는 오류가 발생했습니다.
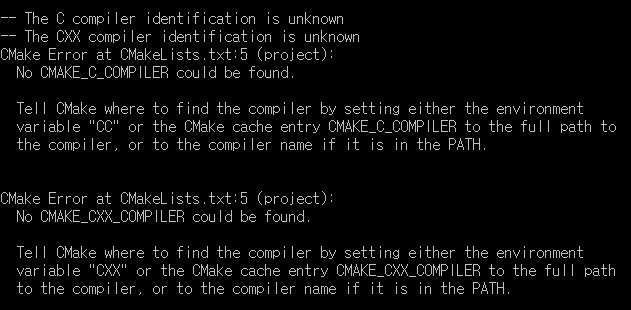
따라서 GCC 경로 설정을 해주면 됩니다. 만약에 윈도우(Windows) 사용자 중에서 GCC가 설치되어 있지 않으신 분이라면 MinGW를 설치하신 뒤에 시스템 변수로 등록해주시면 됩니다. 저자의 경우 처음에 Visual Studio가 설치되어 있었기 때문에 Visual Studio와 연동된 GCC를 사용하려고 했는데, 결국 그냥 MinGW로 설치한 GCC를 이용해서 진행했습니다.
▶ 가능한 오류 상황 2) ZEPHYR_BASE 설정 오류
또한 zepyer-env.cmd를 실행했다고 하더라도, 다음과 같이 ZEPHYR_BASE가 설정되어 있지 않다는 오류가 나올 수 있습니다. 이 경우에는 수동으로 ZEPHYR_BASE의 위치를 설정해주어야 합니다. 따라서 west 명령어를 실행할 때 --zephyr-base 옵션을 주어야 합니다. 제가 넣어 준 명령에서는 --zephyr-base ./라는 부분이 들어가 있습니다. 이것은 현재 폴더를 ZEPHYR_BASE 폴더로 설정하겠다는 것입니다.

▶ 가능한 오류 상황 3) 보드 모델명 오류
또한 보드(Board) 모델 이름을 잘못 기입하면 다음과 같이 보드 이름을 찾을 수 없다는 메시지가 나올 수 있습니다.
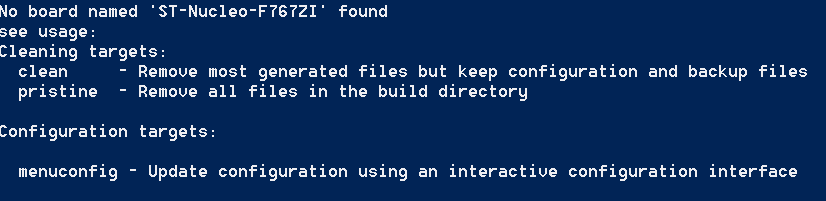
이 경우에는 가능한 보드 모델 이름들이 쭉 나열되기 때문에, 자신의 보드 이름과 동일한 것을 찾아서 잘 기입해주시면 됩니다.
▶ 가능한 오류 상황 4) CMake 불가능 오류
또한 다음과 같이 /cmake/app/boilerplate.cmake 파일을 찾을 수 없다는 메시지가 나올 수 있습니다. 이 경우 ZEPHYR_BASE를 설정했는지 확인해주시고, CMake를 CMake 공식 홈페이지를 통해 다시 설치하셔야 할 수도 있습니다. 이러한 오류 메시지는 'Cannot specify sources for target "app" which is not built by this project' 라는 메시지와 함께 등장할 수 있습니다.
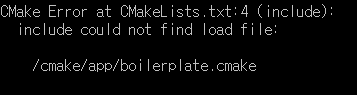
▶ 가능한 오류 상황 5) 기타 오류
이외에도 기타 오류로 의해 실행이 안 될 수도 있습니다. ninja: error: loading 'build.ninja'라는 ninja 관련 설정 파일을 찾을 수 없다는 오류 메시지가 나올 수도 있습니다. 저는 그럴 때 그냥 jephyrproject 프로젝트 파일을 통째로 삭제한 뒤에 다시 'Zephyr Project 소스코드 불러오기' 단계부터 다시 시작했더니 오류 없이 동작했습니다.
이를 포함해 다양한 이유로 Configuring incomplete, errors occurred! 와 같은 메시지가 나올 수 있습니다. 나는 분명히 하라는 대로 거의 완벽하게 잘 한 것 같은데, 빌드가 안 되는 경우 마찬가지로 jephyrproject 프로젝트 파일을 통째로 삭제한 뒤에 다시 'Zephyr Project 소스코드 불러오기' 단계부터 다시 시작해보는 것이 도움이 될 수 있습니다. (저자의 경우 도움이 되었습니다.)
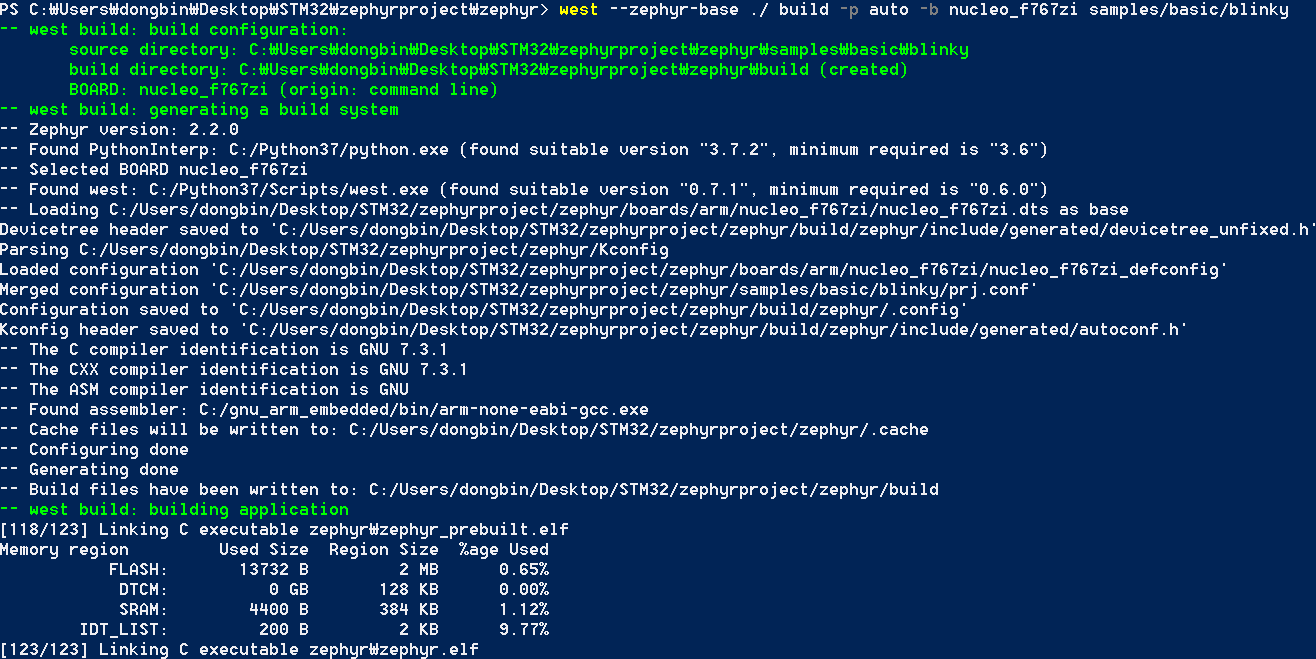
▶ 정상적으로 빌드(Build)가 되었을 때
정상적으로 빌드가 완료되었을 때는 다음과 같이 행복한 문구만 등장합니다.
※ 플래시(Flash) 및 애플리케이션 실행 ※
이제 빌드가 완료되어 .elf 파일을 얻게 되었습니다. 따라서 이렇게 만들어진 펌웨어(Firmware) 파일을 플래시(Flash)하여 보드에 업로드하면 됩니다. 다만 윈도우 사용자의 경우 플래시 과정에서 OpenOCD가 필요할 수 있습니다.
▶ OpenOCD 설치 경로: https://gnutoolchains.com/arm-eabi/openocd/
Download OpenOCD for Windows
Download pre-built OpenOCD for Windows OpenOCD is an open-source tool that allows debugging various ARM devices with GDB using a wide variety of JTAG programmers. You can download the pre-built OpenOCD for windows from this page: Each build above includes
gnutoolchains.com
최신 버전의 OpenOCD를 다운로드 받아줍니다.
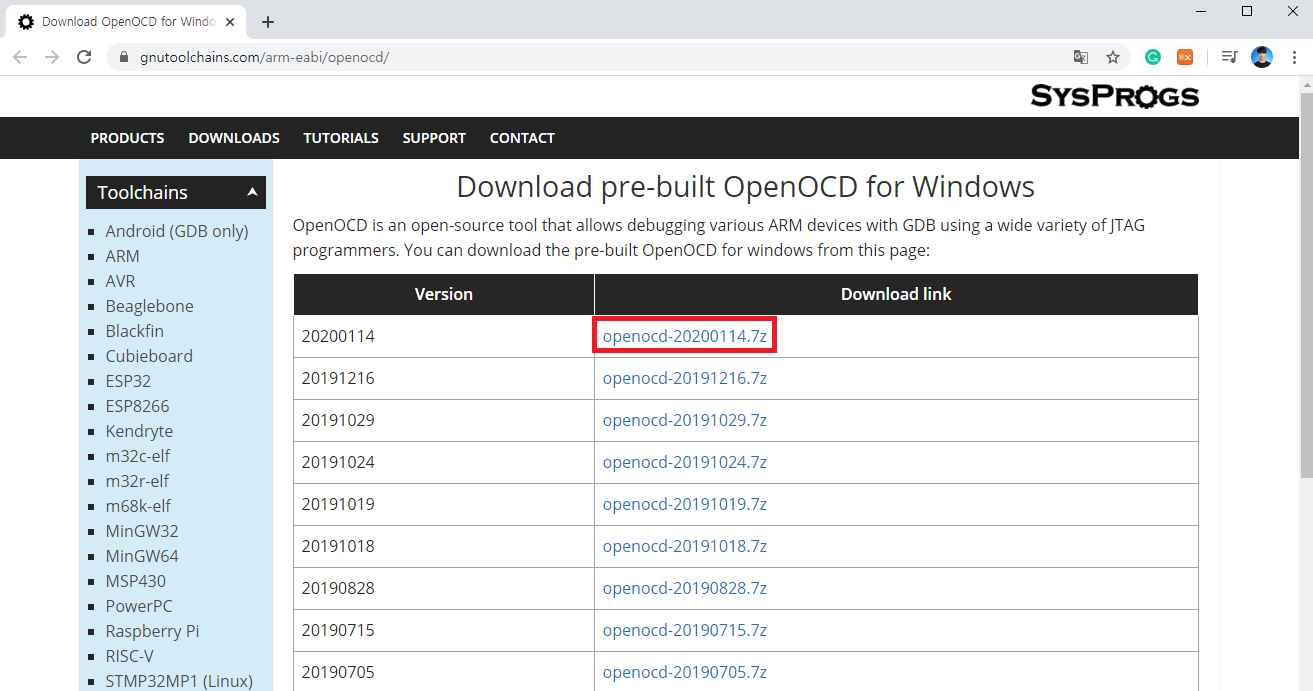
압축을 푼 이후에 bin 폴더와 share 폴더를 C:\Program Files\OpenOCD 경로의 안으로 옮긴 뒤에, C:\Program Files\OpenOCD\bin을 시스템 변수의 Path에 등록합니다.
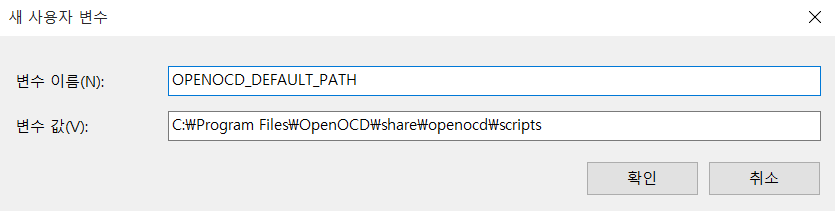
그리고 위와 같이 환경 변수를 하나 추가합니다. OPENOCD_DEFAULT_PATH의 값으로 C:\Program Files\OpenOCD\share\openocd\scripts를 넣습니다. 이제 한 번 나와 있는 대로 west flash 명령을 이용하여 플래시(Flash)를 진행해보도록 합시다.
다만 저자의 경우 OPENOCD-NOTFOUND not found; install it or add its location to PATH 라는 메시지가 등장했습니다. 하지만 분명히 OpenOCD는 설치를 마친 상태였으므로, 안 되는 이유가 잘 납득이 안 되어 컴퓨터를 재부팅해보았습니다. 그랬더니 다음과 같이 오류 없이 잘 동작하게 되었습니다.
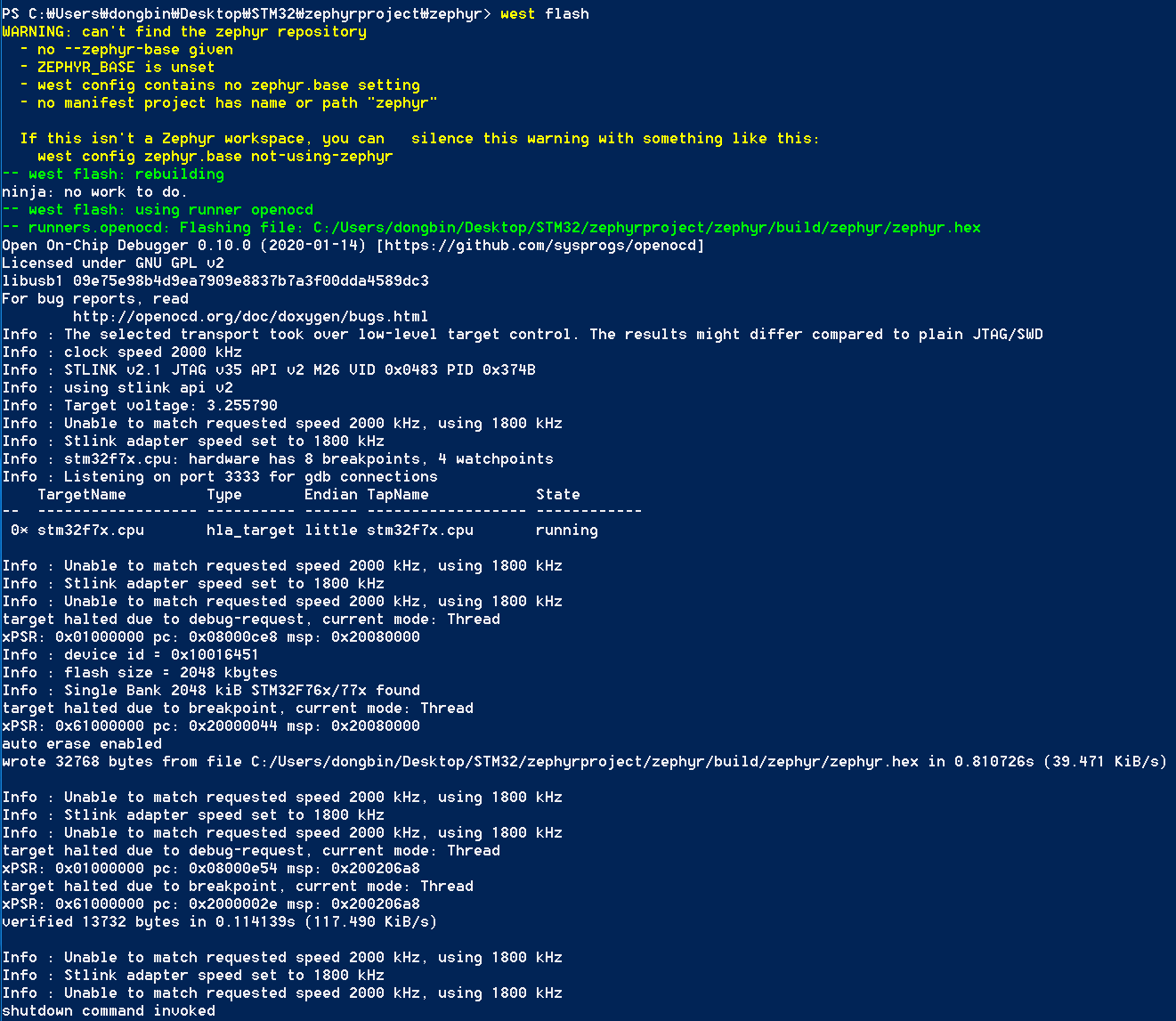
플래시를 진행하는 과정에서 Windows 컴퓨터와 보드(Board)가 연결된 상태라면, 이제 정상적으로 보드가 플래시 된 겁니다. 실제로 보드를 확인해 보시면 보드에 내장된 LED가 반짝반짝 빛나게 됩니다. 별 거 아닌 예제일 텐데, 자꾸 오류가 발생해서 오랜 시간이 소요되었네요.

'기타' 카테고리의 다른 글
| 윈도우(Windows)에서 CMake 설치하는 방법 (1) | 2020.02.11 |
|---|---|
| 윈도우(Windows)에서 MinGW 설치 방법 (0) | 2020.02.11 |
| Visual Studio 2017 이전 버전 다운로드 (0) | 2020.02.11 |
| DeepFakes 소프트웨어: FaceSwap을 이용해 추출한 얼굴로 학습하기(Training) (4) | 2020.02.06 |
| STM32CubeIDE를 활용한 Nucleo-144 Blinky 예제 (0) | 2020.01.31 |
Visual Studio 2017 이전 버전 다운로드
설치 경로는 다음과 같습니다.
https://docs.microsoft.com/ko-kr/visualstudio/productinfo/installing-an-earlier-release-of-vs2017
Visual Studio 2017 이전 릴리스 설치
이 문서에서는 Visual Studio 2017의 이전 릴리스 설치에 대한 지원을 제공합니다.
docs.microsoft.com
[이전 릴리스 설치] 부분에서 원하는 버전의 설치 파일을 클릭하여 다운로드를진행하면 됩니다.
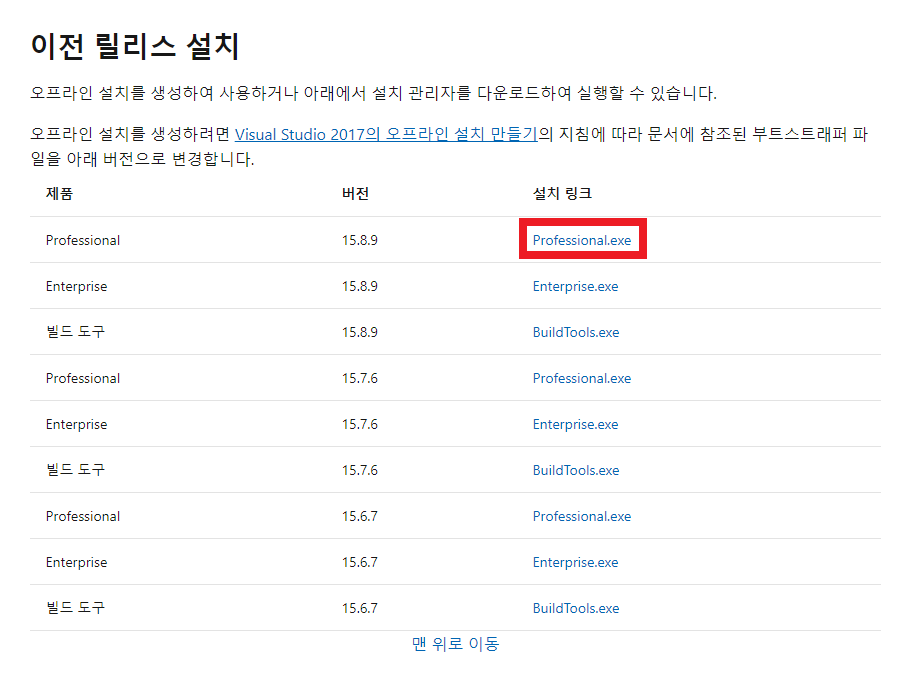
설치 파일을 실행하여 인스톨러를 불러옵니다.
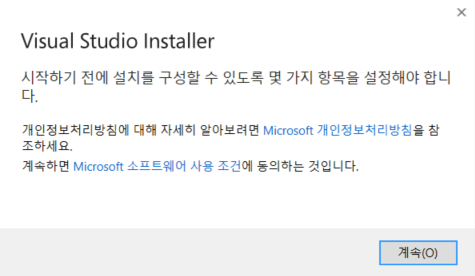
약 1분 이내로 인스톨러가 준비됩니다.
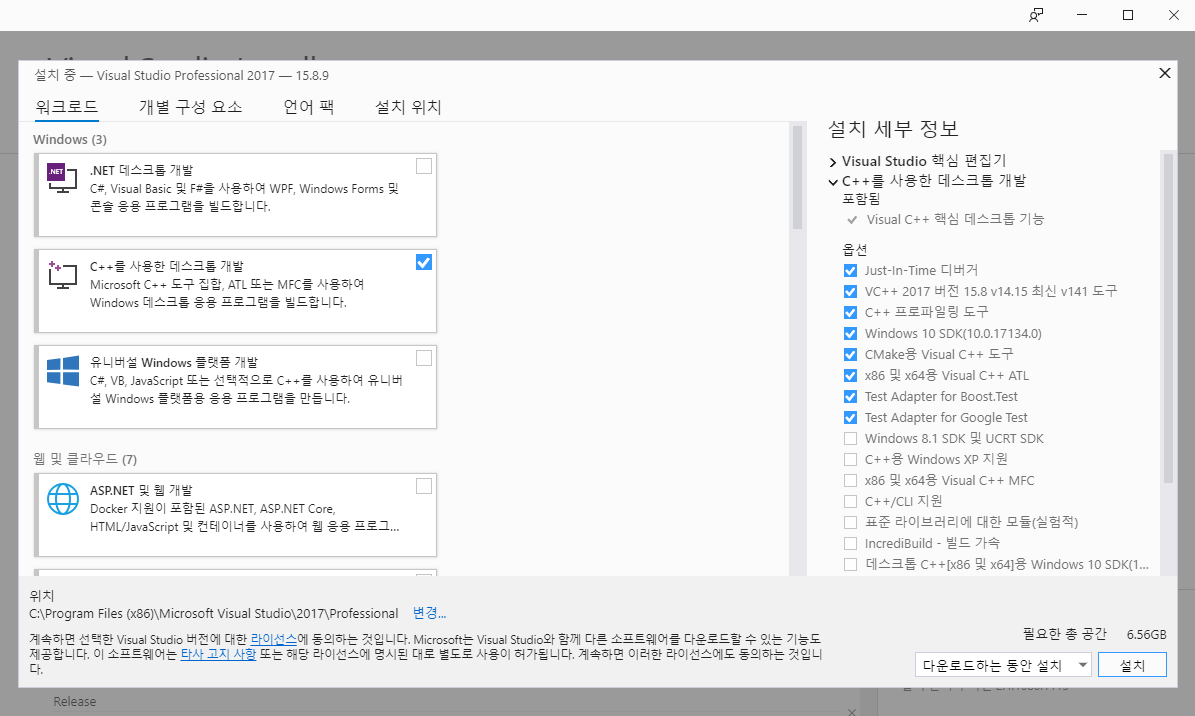
여기에서 자신이 원하는 워크로드를 선택하여 설치하시면 됩니다. 저는 C++ 개발환경을 설치했습니다.
설치 완료 이후에는 재시작하면 됩니다.
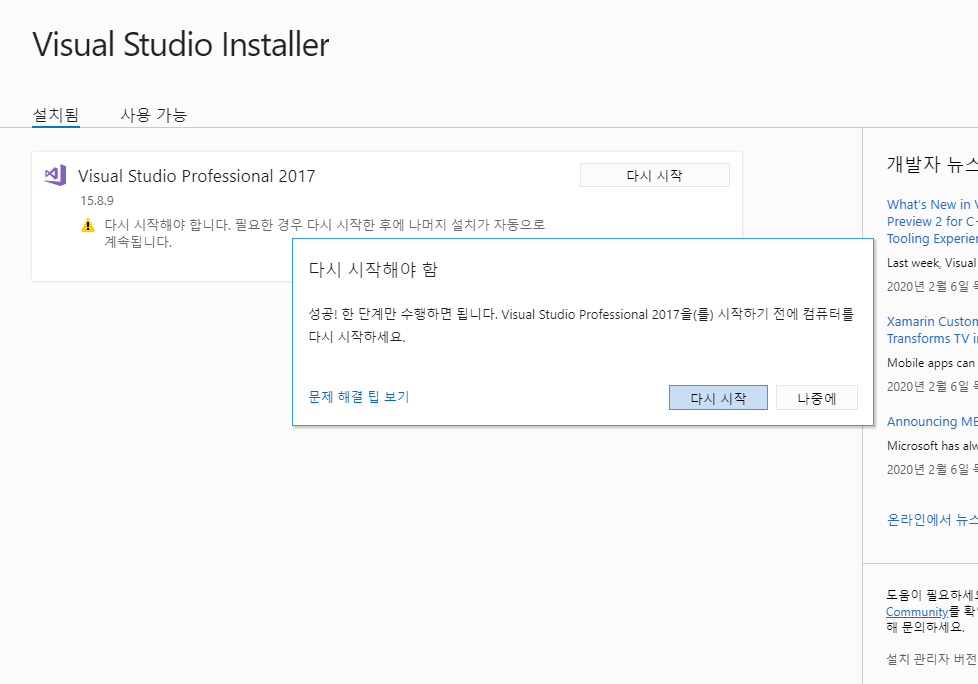
컴퓨터 재시작 이후에는 Visual Studio를 실행한 뒤에 로그인을 해줍니다.
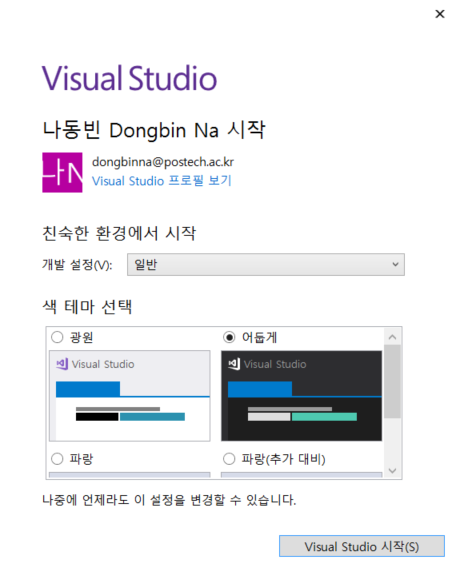
이제 간단히 하나의 프로젝트를 만들 수 있습니다.
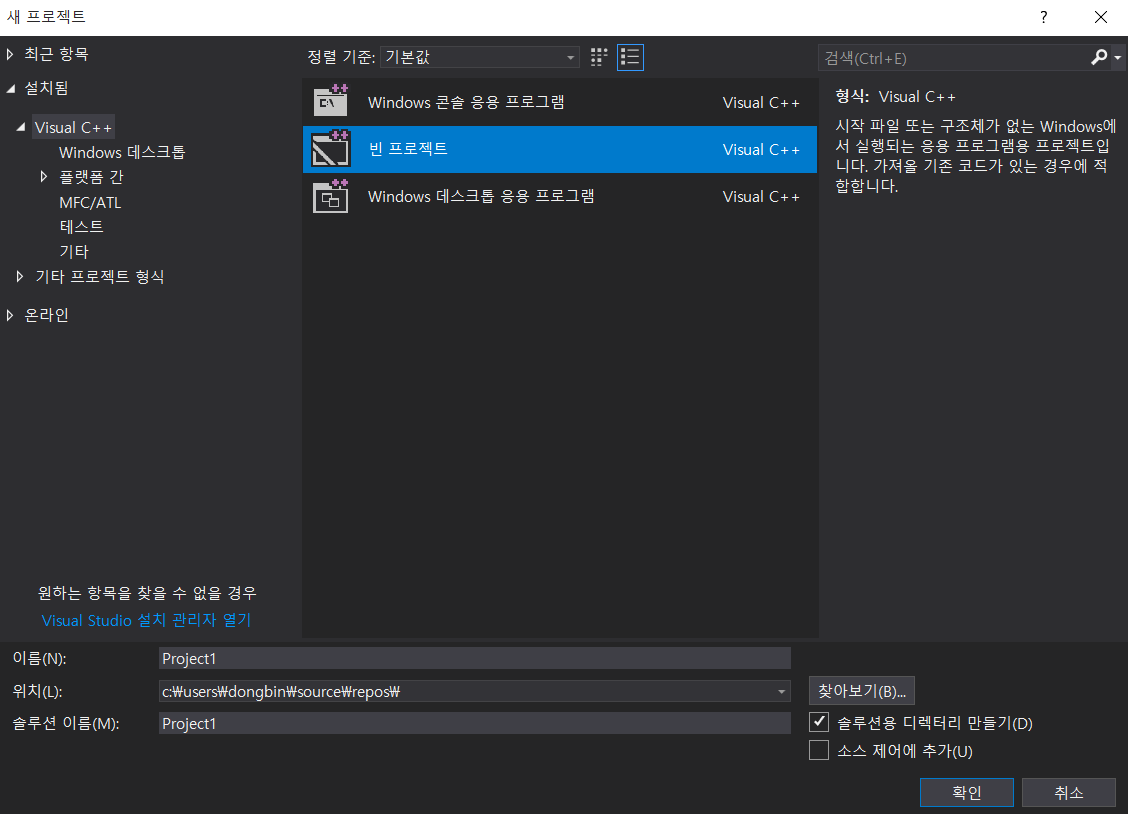
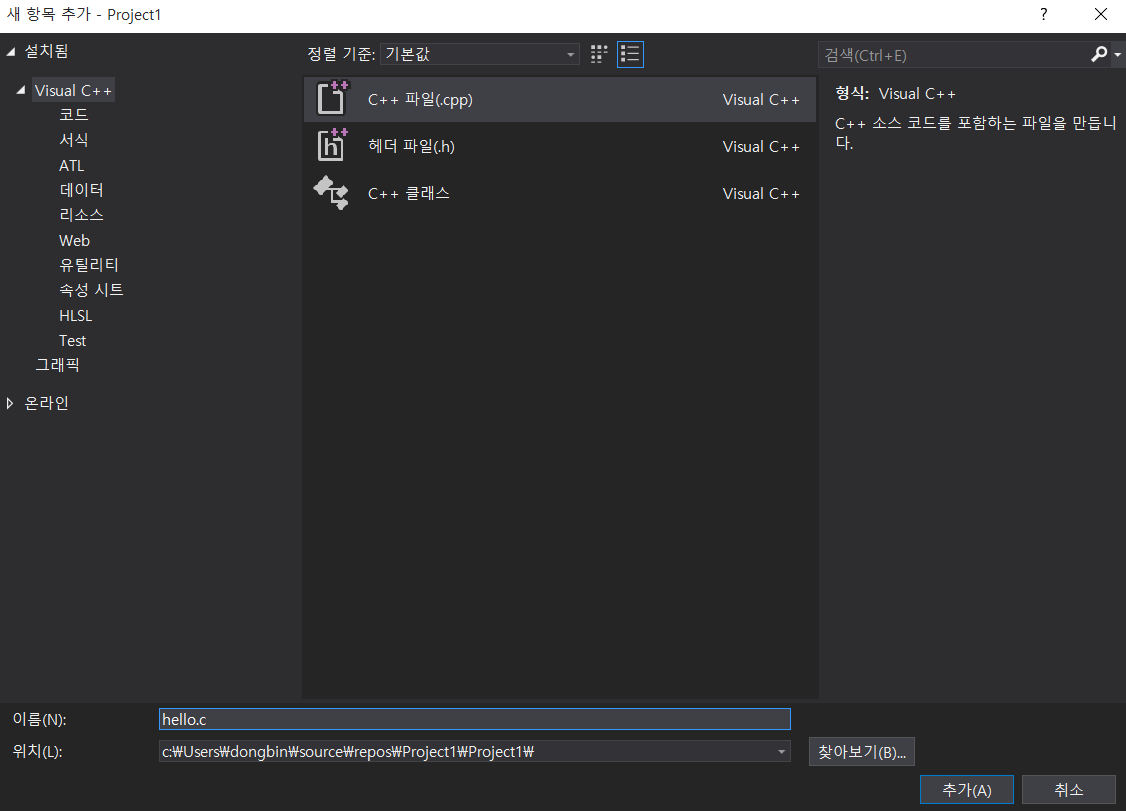
하나의 소스 파일을 추가해보겠습니다.

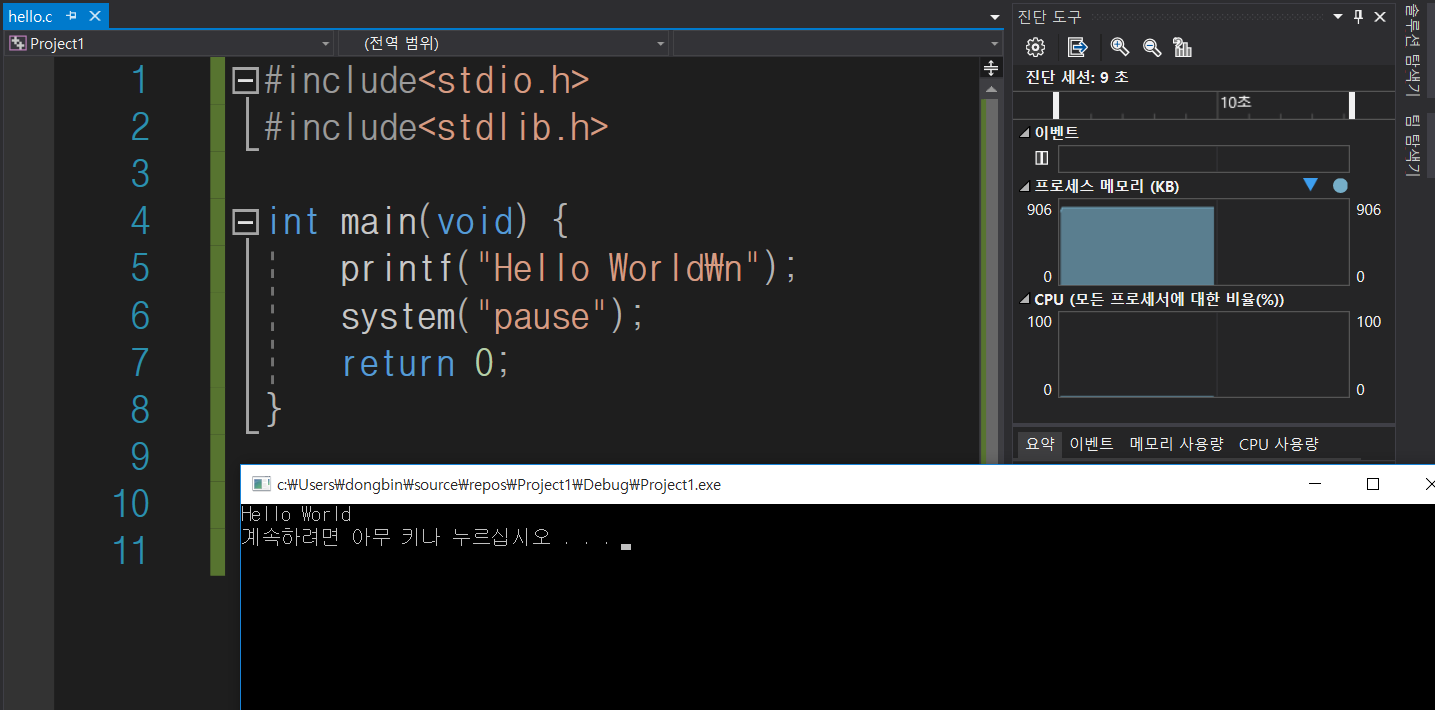
대략 hello.c 라는 파일입니다.
소스코드 작성 및 실행을 해보니까 너무 잘 동작하네요.
'기타' 카테고리의 다른 글
| 윈도우(Windows)에서 MinGW 설치 방법 (0) | 2020.02.11 |
|---|---|
| 윈도우(Windows)에서 Zephyr OS 개발환경 구축하여 시작하기 (2) | 2020.02.11 |
| DeepFakes 소프트웨어: FaceSwap을 이용해 추출한 얼굴로 학습하기(Training) (4) | 2020.02.06 |
| STM32CubeIDE를 활용한 Nucleo-144 Blinky 예제 (0) | 2020.01.31 |
| STM32CubeIDE 설치 방법 (0) | 2020.01.31 |
DeepFakes 소프트웨어: FaceSwap을 이용해 추출한 얼굴로 학습하기(Training)
※ 오토 인코더의 구성요소
1) 인코더(Encoder): 얼굴 이미지를 '인코딩(Encoding)' 하는 역할을 수행한다. 얼굴 이미지가 입력으로 들어 오면 그 이미지를 Representation 벡터(Vector)로 변환한다. 다시 말해 Representation에는 입력 이미지의 어떠한 특징(Feature)들이 임의의 형태로 저장된다.
2) 디코더(Decoder): 압축된 Representation을 다시 얼굴 이미지로 되돌리는 역할을 수행하는 파트다.
이러한 인코더와 디코더를 합친 구조를 흔히 오토 인코더(Auto-Encoder)라고 부르는데, 주로 차원 축소, 데이터 압축이나 Generative Model의 기능으로 인공지능 분야에서 많이 활용되고 있다. 사실 이러한 AE는 GAN과 더불어 현재 Generative Model의 주축이라고 할 수 있는데, 자세한 내용에 대해서 궁금하신 분께는 VAE 논문을 읽어 보는 것을 추천한다.
아무튼, 오토 인코더 자체는 어떤 이미지를 '압축'했다가 다시 '복원'하는 과정을 수행해주는 모델이라고 할 수 있다. 이러한 구조가 DeepFakes 분야에서 유용한 이유는, 기본적으로 오토 인코더는 중간 레이어라고 할 수 있는 Representation Layer가 '얼굴의 특징'을 잡아내고 있기 때문이다.
예를 들어 오바마 사진을 넣어서 학습을 시키면, 오바마가 가지고 있는 얼굴의 특징들이 Representation Layer에 남아 있게 된다. (Controllable 한지는 잘 모르겠다.) 특징이라고 하면, 다음과 같은 것들이 있다.
- 눈썹의 위치
- 입술의 모양
- 눈의 크기
- 등등
아무튼 이러한 Feature들을 Representation Layer에서 인코딩된 정보로서 포함하게 된다.

※ 오토 인코더의 학습
기본적으로 머신러닝 모델 학습에 있어서는 다음과 같은 용어를 알고 있으면 좋다.
- 손실(Loss): 모델에 입력으로 넣는 이미지가 복원(Reconstruction)된 이미지와 얼마나 다른지를 정량화한 것이다. 학습 초반에는 당연히 손실 값이 크고, 학습이 잘 되고 나면 손실 값이 낮다. 학습을 시킨다는 것은 손실 값 자체를 낮추기 위해 모델을 Update하는 것을 의미한다. 일반적으로 FaceSwap에서는 오토 인코더의 Loss 값이 0.01 미만으로 떨어졌을 때, 상당히 DeepFakes 영상이 그럴싸하게 나온다.
- 가중치(Weights): 흔히 모델의 파라미터 값이라고 불리는 Weight 값은, 모델 그 자체의 값을 의미한다. 이미지 자체가 원래 고차원의 Vector 형태로 주어지며, 모델은 여기에 임의의 가중치 값을 곱하여 연산을 수행한다. 사실 모델을 Update한다는 의미도 이 가중치를 업데이트하는 것을 의미한다.

※ FaceSwap의 동작 원리
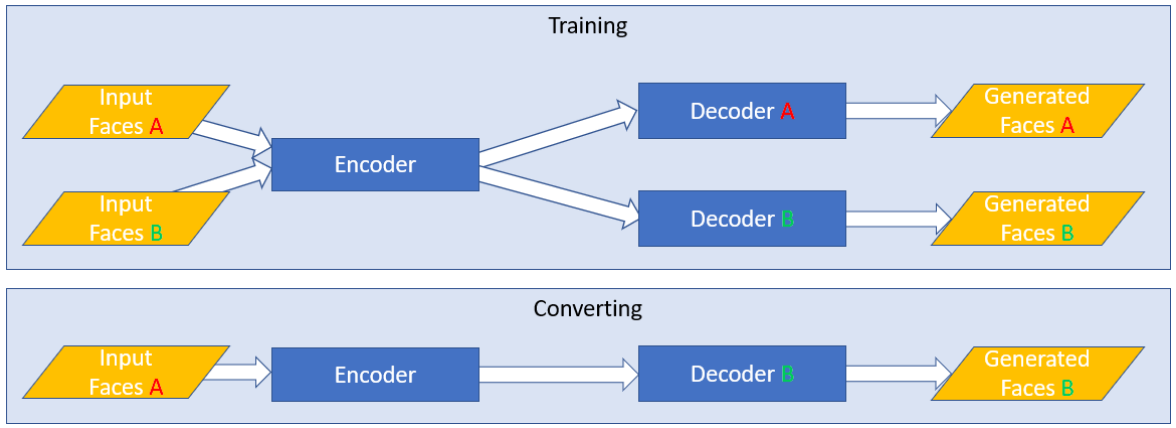
이제 이러한 오토 인코더를 이용하여 어떻게 DeepFake가 만들어지는지 자세히 알아보자. DeepFakes 모델은 오토 인코더 모델을 재미있게 변형하여 만들어졌다. 바로 학습 과정에서 두 영상이 '공통된 인코더(Shared Encoder)'를 사용하고, 서로 다른 디코더(Decoder)를 이용하도록 하면 된다.
그러면 Encoder에서는 두 얼굴에서 공통적인 특징들(눈썹의 위치, 코의 위치, 얼굴 각도 등)을 효과적으로 추출할 수 있게 되고, 두 얼굴에서 서로 다른 특징들(눈썹의 모양, 코의 모양, 얼굴의 형태 등)은 Decoder 파트에서 구분하여 이미지를 복원(Reconstruction)하게 된다.
그렇게 학습을 하고 나면, Source의 이미지를 Encoder에 넣어서 추출된 '눈썹의 위치, 코의 위치, 얼굴 각도' 등의 Representation을 다시 Decoder에 넣게 되면, 해당 위치에 맞게 Target의 이미지의 인물이 가지는 정체성(Identity)이 입혀지게 된다. 다시 말해 해당 인물이 누구인지를 알려주게 되는 정체성 정보는 Decoder 파트가 처리하게 되어 DeepFakes 비디오가 만들어지는 것이다.
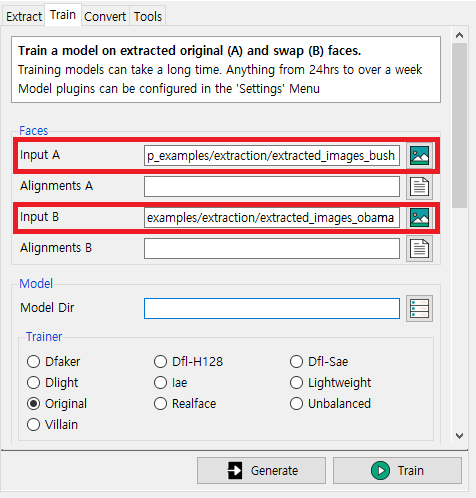
※ 학습(Training) 실습
이제 지난 시간에 추출했던 이미지를 가지고 학습을 진행해보자. Input A는 Source이며, Input B는 Target이 된다. 다시 말해 Source 동영상의 얼굴 부분에 Target(피해자) 동영상에 존재하는 사람의 얼굴 정체성(Identity)를 삽입하는 것이다. 즉, Input A에 Input B의 얼굴이 삽입된다. 예를 들어
- Input A: 부시(Bush)
- Input B: 오바마(Obama)
위와 같이 설정하면 부시 미국 전 대통령이 연설하는 동영상에 오바마 미국 전 대통령의 얼굴이 삽입된다.
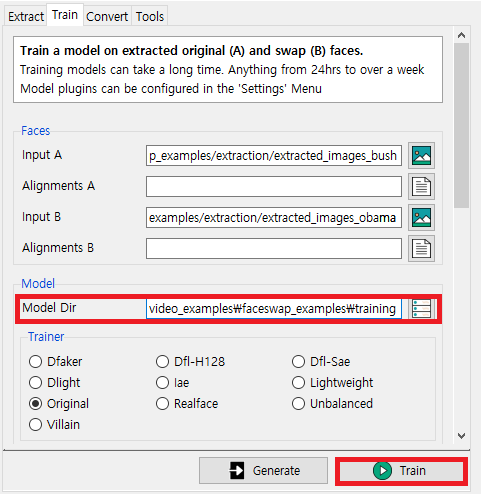
이제 학습이 진행됨에 따라서 모델 파일을 저장할 경로를 [Model Dir]에 기록한다. 이후에 [Train] 버튼을 누르면 학습이 진행된다.
※ 학습이 안 되는 경우
원래는 학습(Training)이 정상적으로 진행이 되며 모델이 학습됨에 따라서 Face Swapping이 얼마나 잘 되는지 [Preview]에서 보인다. 하지만 저자의 경우 AMD 그래픽 카드를 가지고 있어 호환 문제로 다음과 같은 크래시(Crash)가 발생하였다.
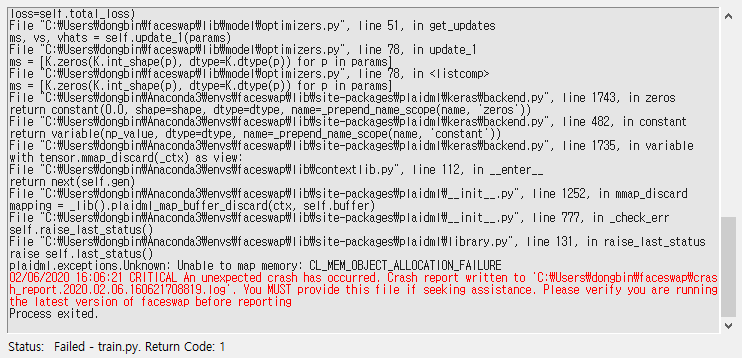
이런 문제가 발생하는 경우, 선택할 수 있는 방법은 여러 가지가 있는데, 대략 다음과 같다.
- FaceSwap을 CPU 버전으로 설치 및 실행하여 CPU만 가지고 학습을 진행하기
- Google Colab과 같은 무료 GPU 서비스를 이용하여 학습을 진행하기
- 개인용 학습 워크스테이션을 구축하여 리눅스 서버상에서 학습을 진행하기
- 별도로 AWS 등에서 GPU 서버를 구축하여 학습을 진행하기
사실상 이전 포스팅에서도 저자가 가지고 있는 AMD GPU 그래픽 카드의 호환 문제 때문에 추출(Extraction)을 CPU만 가지고 수행하였다. 역시 학습(Training)을 수행할 때에도 동일한 문제가 발생하고 있는 것이다. 하지만 걱정할 필요는 없다. 어차피 나중에 제대로 장비를 갖추어서 학습을 진행할 때는 리눅스에서 진행하게 되므로, 미리 공부하는 셈 치면 된다. 아무래도 공짜로 학습을 시키는 방법 중에서는 Google Colab이 가장 효과적일 것이다.
저자가 사용한 Google Colab 소스코드를 첨부하겠다.
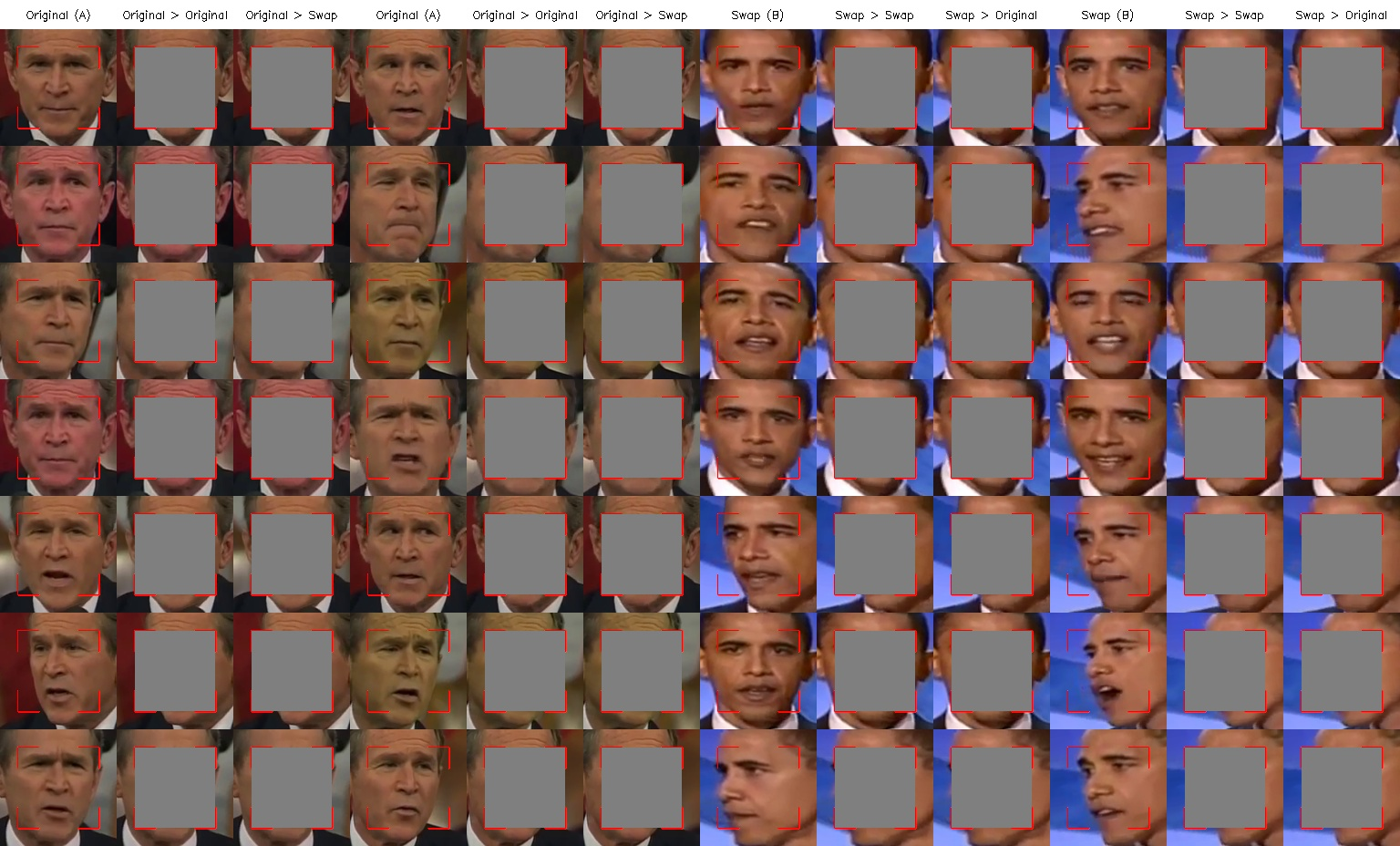
※ 학습 과정 살펴보기
# 학습 시작 직후
# 학습 시작 5분 후
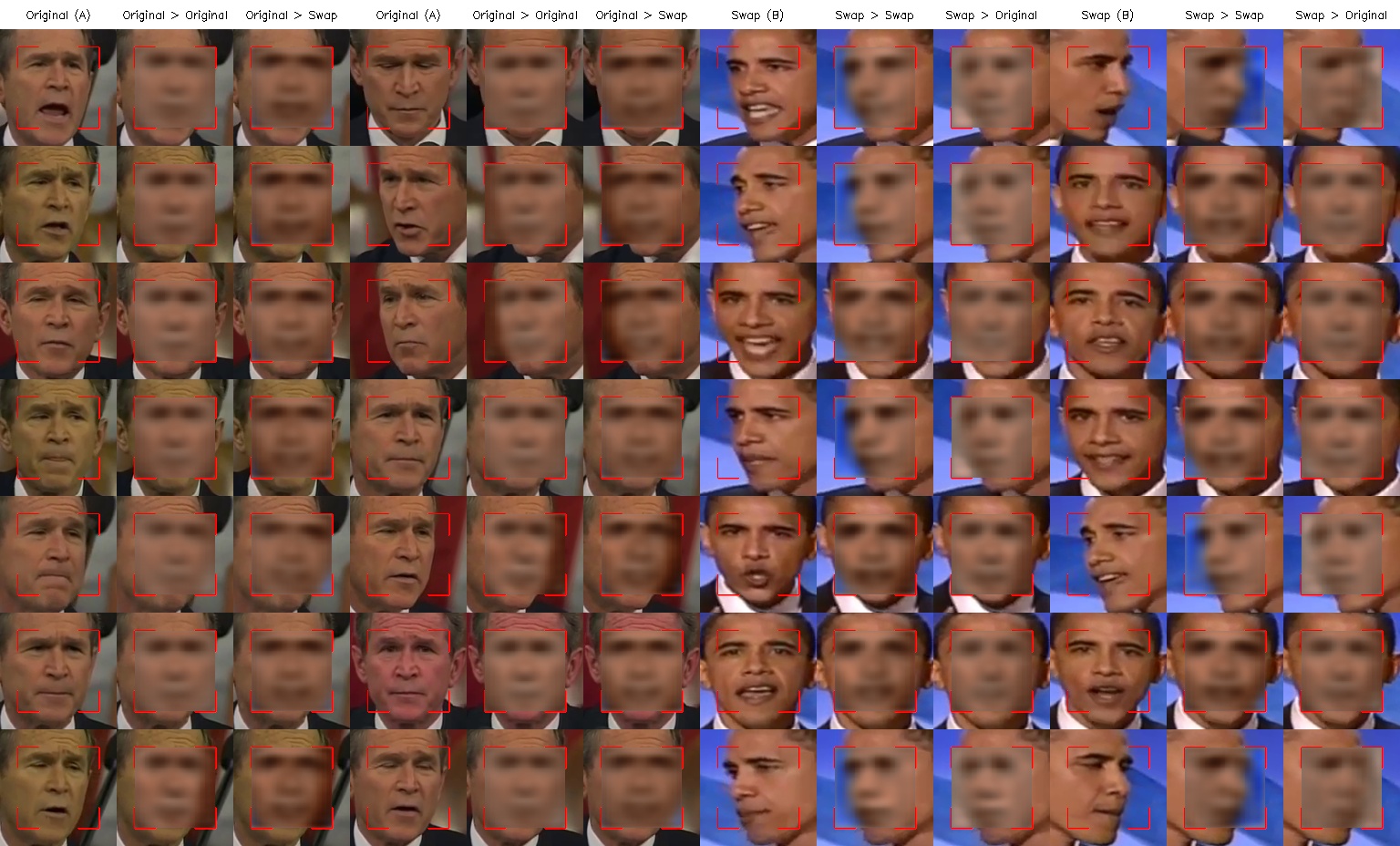
# 학습 시작 30분 후

# 학습 시작 8시간 후

'기타' 카테고리의 다른 글
| 윈도우(Windows)에서 Zephyr OS 개발환경 구축하여 시작하기 (2) | 2020.02.11 |
|---|---|
| Visual Studio 2017 이전 버전 다운로드 (0) | 2020.02.11 |
| STM32CubeIDE를 활용한 Nucleo-144 Blinky 예제 (0) | 2020.01.31 |
| STM32CubeIDE 설치 방법 (0) | 2020.01.31 |
| DeepFakes 소프트웨어: FaceSwap을 이용해 비디오에서 얼굴 추출하기(Extraction) (0) | 2020.01.30 |
