SQLite를 활용한 데이터베이스 문제 풀이 예시
세 개의 릴레이션이 있는 상황을 가정합시다. 실습으로 다루고자 하는 데이터베이스는 사원(Employee), 회사(Company), 소속(Affiliation) 세 가지 테이블로 구성됩니다. 그 세부적인 정보는 다음과 같습니다.
※ 사원(Employee) 릴레이션 ※
사원의 이름, 거주 도시 정보를 포함하고 있습니다.
| Employee_ID | Employee_Name | Employee_City |
| 1 | Seo | 청주 |
| 2 | Chung | 서울 |
| 3 | Lee | 인천 |
| 4 | Kim | 대전 |
| 5 | Park | 서울 |
| 6 | Moon | 서울 |
※ 회사(Company) 릴레이션 ※
회사의 이름, 회사가 위치한 도시 정보를 포함하고 있습니다.
| Company_Name | Company_City |
| SK | 인천 |
| LG | 청주 |
| 삼성 | 서울 |
※ 소속(Affiliation) 릴레이션 ※
사원의 번호, 회사의 이름, 연봉 정보를 포함하고 있습니다. 즉, 어떠한 사원이 어떠한 회사에서 일을 하고 있는지에 대한 정보를 담고 있습니다.
| Employee_ID | Company_Name | Pay |
| 1 | SK | 10000 |
| 2 | LG | 900 |
| 3 | 삼성 | 30000 |
| 4 | 삼성 | 50000 |
| 5 | 삼성 | 100 |
| 6 | LG | 200 |
※ 데이터베이스 구축하기 ※
다음과 같이 데이터베이스를 생성하고, 테이블을 구축하여 기본적인 데이터를 삽입할 수 있습니다.
/* 사원(Employee) 테이블 */
CREATE TABLE Employee(
Employee_ID INT PRIMARY KEY,
Employee_Name TEXT,
Employee_City TEXT
);
INSERT INTO Employee VALUES (1, 'Seo', '청주');
INSERT INTO Employee VALUES (2, 'Chung', '서울');
INSERT INTO Employee VALUES (3, 'Lee', '인천');
INSERT INTO Employee VALUES (4, 'Kim', '대전');
INSERT INTO Employee VALUES (5, 'Park', '서울');
INSERT INTO Employee VALUES (6, 'Moon', '서울');
/* 회사(Company) 테이블 */
CREATE TABLE Company(
Company_Name TEXT PRIMARY KEY,
Company_City TEXT
);
INSERT INTO Company VALUES ('SK', '인천');
INSERT INTO Company VALUES ('LG', '청주');
INSERT INTO Company VALUES ('삼성', '서울');
/* 소속(Affiliation) 테이블 */
CREATE TABLE Affiliation(
Employee_ID INT,
Company_Name TEXT,
Pay INT
);
INSERT INTO Affiliation VALUES (1, 'SK', 10000);
INSERT INTO Affiliation VALUES (2, 'LG', 900);
INSERT INTO Affiliation VALUES (3, '삼성', 30000);
INSERT INTO Affiliation VALUES (4, '삼성', 50000);
INSERT INTO Affiliation VALUES (5, '삼성', 100);
INSERT INTO Affiliation VALUES (6, 'LG', 200);
Q1. 회사명이 'LG'인 회사에서 일하는 모든 사원의 이름과 거주하는 도시들을 출력합니다.
SELECT e.Employee_Name, e.Employee_City
FROM Employee as e, Affiliation as a
WHERE e.Employee_ID == a.Employee_ID
AND a.Company_Name = "LG";
Q2. 소속한 회사가 위치한 도시와 다른 도시에 거주하는 모든 사원의 이름, 소속 회사 이름, 소속 회사의 도시, 사원이 거주하는 도시를 출력합니다.
SELECT e.Employee_Name, c.Company_Name, c.Company_City, e.Employee_City
FROM Employee as e, Company as c, Affiliation as a
WHERE e.Employee_ID == a.Employee_ID
AND c.Company_Name == a.Company_Name
AND e.Employee_City != c.Company_City;
Q3. 각 회사별로 회사 이름과 사원의 수, 평균 월급을 출력합니다.
간단한 버전은 다음과 같습니다.
SELECT a.Company_Name, COUNT(a.Employee_ID), AVG(a.Pay)
FROM Affiliation as a
GROUP BY a.Company_Name;
조금 더 어렵게 작성 소스코드 버전은 다음과 같습니다.
SELECT c.Company_Name, COUNT(e.Employee_ID), AVG(a.Pay)
FROM Employee as e, Company as c, Affiliation as a
WHERE e.Employee_ID == a.Employee_ID
AND c.Company_Name == a.Company_Name
GROUP BY a.Company_Name;
Q4. 각 회사별로 소속 사원들의 평균 월급보다 높은 월급을 받는 종업원들의 사원의 번호, 회사 이름, 월 급여, 해당 회사의 평균 월급을 출력합니다.
SELECT a.Employee_ID, a.Company_Name, a.Pay, c_sum.Pay
FROM Affiliation as a, (SELECT t.Company_Name, AVG(t.Pay) as Pay FROM Affiliation as t GROUP BY t.Company_Name) as c_sum
WHERE a.Company_Name == c_sum.Company_Name
AND a.Pay > c_sum.Pay;
Q5. 'LG'의 (하나 혹은 여러) 사원보다 월급을 많이 받는 모든 사원들의 사원의 번호, 회사 이름, 월 급여를 출력합니다.
SELECT a.Employee_ID, a.Company_Name, a.Pay
FROM Affiliation as a, (SELECT MIN(t.Pay) as Pay FROM Affiliation as t WHERE t.Company_Name == "LG") as c_sum
WHERE a.Pay > c_sum.Pay;
혹은 다음과 같이 할 수 있습니다.
SELECT a.Employee_ID, a.Company_Name, a.Pay
FROM Affiliation as a
WHERE a.Pay > (SELECT MIN(t.Pay) as Pay FROM Affiliation as t WHERE t.Company_Name == "LG");
'기타' 카테고리의 다른 글
| 삼성전자, 삼성전자 우선주(삼성전자우) 차이 비교 및 주식 사는 방법 (0) | 2021.07.24 |
|---|---|
| 포항공대 학생회관/지곡회관 회의실 예약 방법 (0) | 2021.07.24 |
| 키움증권 웹 사이트에서 주식 시외가(시간 외 단일가) 보는 방법 (0) | 2021.07.20 |
| DB Browser for SQLite (DB4S) 설치 및 사용 방법 (0) | 2021.07.19 |
| Python에서 SQLite3 사용하는 방법 핵심 요약 및 소스코드 예제! (0) | 2021.07.19 |
키움증권 웹 사이트에서 주식 시외가(시간 외 단일가) 보는 방법
네이버에 "주식 거래 시간"을 검색하면 다음과 같은 정보가 나온다.

위 표에 나와 있듯이 국내 주식 매매 거래 시간의 정규시간은 09:00~15:30이다.
기본적으로 해당 날짜에 형성된 종가의 위아래로 10% 이내의 가격을 [시간 외 단일가]라고 한다. 장이 마감한 이후에도 이러한 [시간 외 단일가]로 16:00~18:00 사이에 거래할 수 있다. 이때 16:00~18:00 사이에서 매 10분마다 1번씩 거래가 체결된다. 예를 들어 16:00~16:10까지의 주문을 모아서 16:10에 체결을 진행하고, 또 16:10~16:20까지의 주문을 모아서 16:20에 체결을 진행하는 방식이다.
그래서 16:00 시간대 이후라고 해도 갑자기 호재가 터지는 경우에는 매수 주문이 많아져서, 시간 외 상한가에 도달하는 경우도 있다. 이런 경우에는 시간 외 상한가가 다음날 종목 시세에 영향을 미쳐서, 장 시작과 동시에 상승장이 시작되기도 한다.
※ 키움증권 웹 사이트(웹 트레이딩, WTS)을 이용해 시외가 보는 방법 ※
시외가를 보는 방법은 간단하다. 먼저 키움증권 웹 사이트에 로그인하자. 이후에 [주식주문(웹트레이딩)] 버튼을 누른다.

이후에 원하는 종목을 선택한 뒤에 오른쪽 위에 있는 [시간 외 단일가] 버튼을 누른다. 예를 들어 필자는 HMM을 종목으로 선택했으며, [시간 외 단일가]를 확인한 결과 43,050원으로 가격이 형성된 것을 확인할 수 있었다.

'기타' 카테고리의 다른 글
| 포항공대 학생회관/지곡회관 회의실 예약 방법 (0) | 2021.07.24 |
|---|---|
| SQLite를 활용한 데이터베이스 문제 풀이 예시 (0) | 2021.07.20 |
| DB Browser for SQLite (DB4S) 설치 및 사용 방법 (0) | 2021.07.19 |
| Python에서 SQLite3 사용하는 방법 핵심 요약 및 소스코드 예제! (0) | 2021.07.19 |
| 미리캔버스 무료 PPT 템플릿을 이용한 PPT/배너/썸네일 제작 방법! (0) | 2021.07.11 |
DB Browser for SQLite (DB4S) 설치 및 사용 방법
DB Browser for SQLite (DB4S)는 SQLite과 호환되는 데이터베이스 설계 및 수정 소프트웨어입니다. 웹 사이트에 방문한 뒤에 간단하게 설치하여 곧바로 사용할 수 있습니다. DB4S는 다음의 웹 사이트에 방문하여 상세한 정보를 확인할 수 있습니다.
▶ DB Browser for SQLite 공식 홈페이지: https://sqlitebrowser.org/
DB4S 공식 페이지에 접속한 뒤에 [Download] 페이지로 이동하면 다음과 같은 화면을 확인할 수 있습니다. 자신의 운영체제에 맞는 설치 프로그램을 다운로드받으면 됩니다. 저는 윈도우(Windows) 운영체제에 맞는 64-bit 버전의 프로그램을 다운로드했습니다.
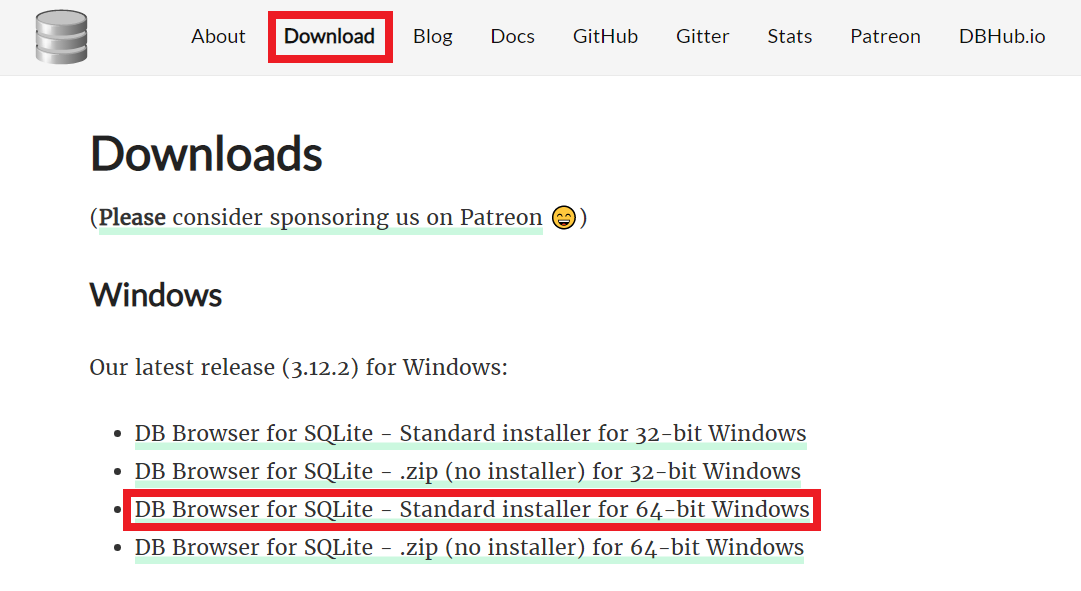
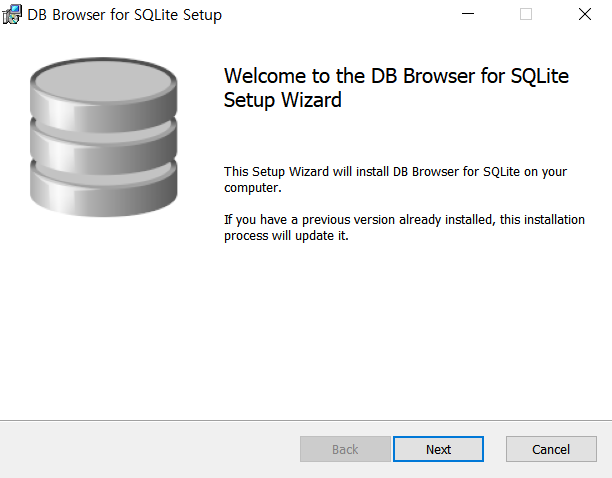
설치 프로그램을 실행하여, 가장 먼저 라이센스에 동의하고 설치를 진행합니다.
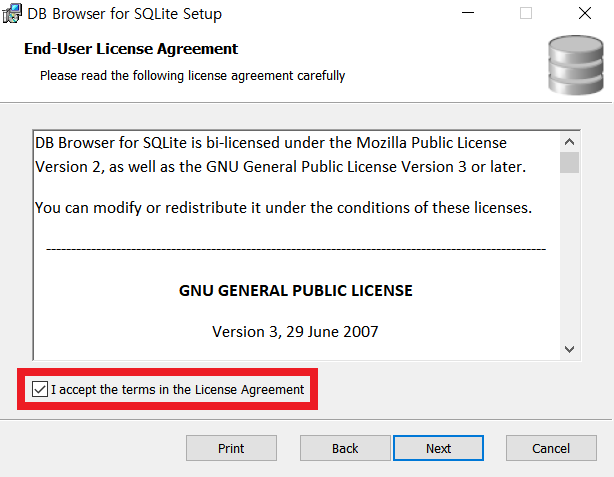
다음과 같이 설정을 진행합니다.
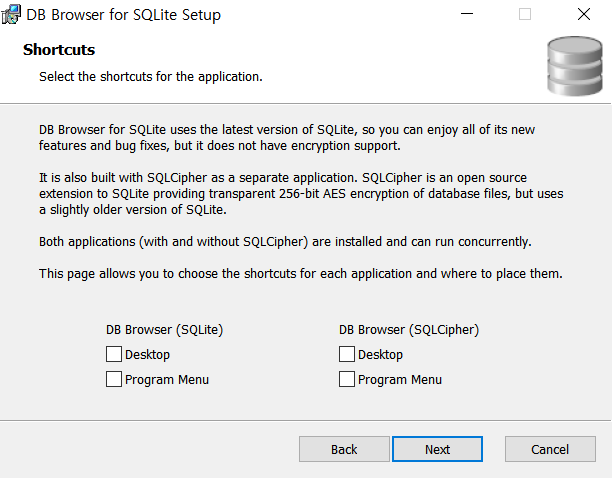
이후에 설치(install)를 진행하면 됩니다. 설치 이후에는 실행 프로그램을 실행하여 열 수 있습니다.
※ 데이터베이스 생성하기 ※
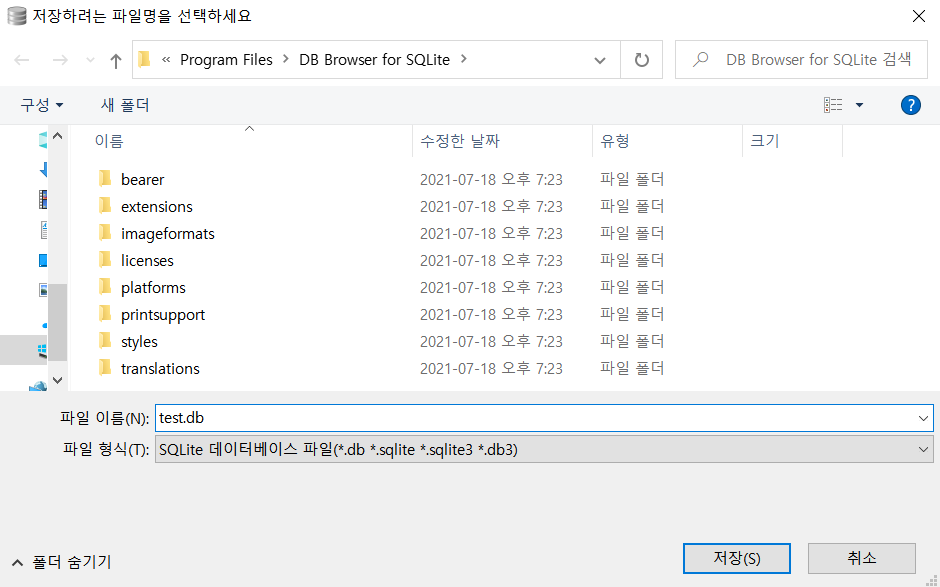
[새 데이터베이스] 버튼을 눌러 새로운 데이터베이스를 생성할 수 있습니다.

예를 들어 다음과 같이 test.db라는 이름의 데이터베이스를 생성할 수 있습니다.
데이터베이스가 생성되면 다음과 같이 [데이터베이스 구조] 탭에서 데이터베이스의 정보를 확인할 수 있습니다.

이후에 [SQL 실행] 탭으로 이동하여 자신이 원하는 SQL 쿼리를 입력할 수 있습니다.
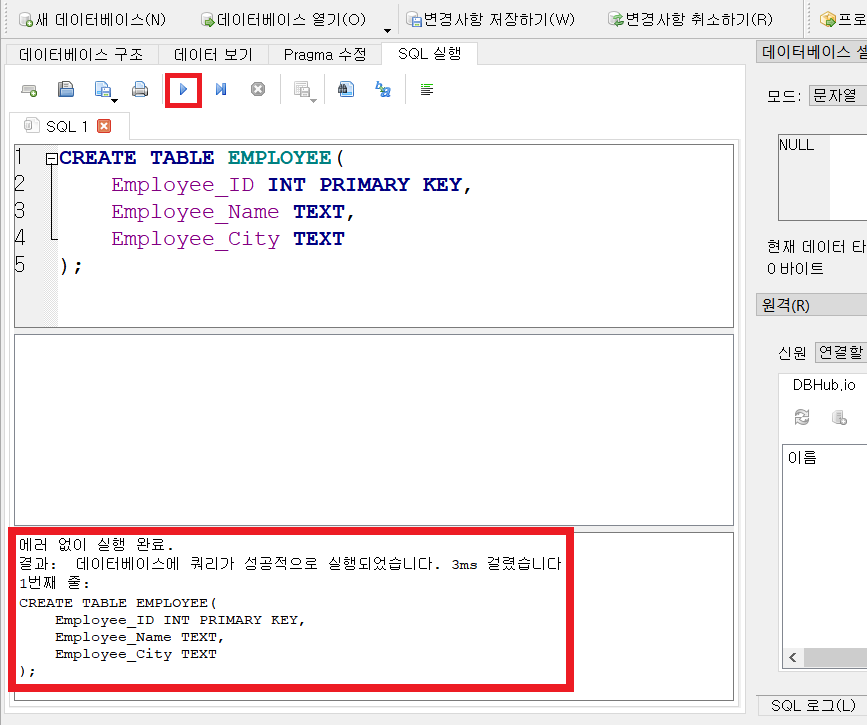
'기타' 카테고리의 다른 글
| SQLite를 활용한 데이터베이스 문제 풀이 예시 (0) | 2021.07.20 |
|---|---|
| 키움증권 웹 사이트에서 주식 시외가(시간 외 단일가) 보는 방법 (0) | 2021.07.20 |
| Python에서 SQLite3 사용하는 방법 핵심 요약 및 소스코드 예제! (0) | 2021.07.19 |
| 미리캔버스 무료 PPT 템플릿을 이용한 PPT/배너/썸네일 제작 방법! (0) | 2021.07.11 |
| 유튜버를 위한 단역 배우 섭외 방법 Feat. 인스타그램 DM (0) | 2021.07.10 |
Python에서 SQLite3 사용하는 방법 핵심 요약 및 소스코드 예제!
파이썬의 경우 sqlite3을 표준 라이브러리로 제공하고 있다. 그래서 파이썬을 설치했다면, 별다른 추가 설치 없이 sqlite3을 이용할 수 있다. sqlite3은 다음과 같이 불러 올 수 있다. 참고로 아래 소스코드를 실행하면 '3.21.0'와 같은 SQLite의 버전명이 출력된다. 이것은 파이썬 라이브러리 버전은 아니고, SQLite의 버전으로 이해할 수 있다.
import sqlite3
print(sqlite3.sqlite_version)
※ 데이터베이스 생성 ※
데이터베이스를 생성할 때는 간단히 connect() 메서드를 사용하면 된다. 이때 메서드의 인자로 넣은 값이 데이터베이스 파일의 경로가 된다. 예를 들어 'my_database.db'라는 파일을 생성하고자 한다면 다음과 같이 한다. 현재 'my_database.db'라는 데이터베이스 파일이 없기 때문에, 새롭게 생성된 것을 확인할 수 있다.

※ 테이블 생성 ※
SQL 구문을 이용하기 위해서는 cursor 객체가 필요하다. cursor 객체를 이용하여 실제로 데이터베이스에 테이블(table)을 삽입하거나, 테이블(table)을 조회할 수 있다. 예를 들어 다음의 명령어는 Course(과목)라는 이름의 테이블을 생성한다. 이후에 생성된 테이블 정보를 조회한다.
import sqlite3
con = sqlite3.connect('./my_database.db')
cursor = con.cursor()
SQL = "CREATE TABLE Course (Course_ID int primary key not null, Course_Name text, Course_Date date);"
cursor.execute(SQL)
SQL = "SELECT name FROM sqlite_master WHERE type='table';"
cursor.execute(SQL)
print(cursor.fetchall())
SQL = "SELECT sql FROM sqlite_master WHERE type='table';"
cursor.execute(SQL)
print(cursor.fetchall())
con.close()
실행 결과는 다음과 같다.
[('Course',)]
[('CREATE TABLE Course (Course_ID int primary key not null, Course_Name text, Course_Date date)',)]
※ 데이터 삽입 ※
데이터를 삽입할 때는 INSERT 구문을 사용한다. 참고로 데이터를 삽입(insert)하는 명령어를 실행한 뒤에 데이터베이스에 반영하기 위해 commit() 메서드를 호출해야 한다.
import sqlite3
con = sqlite3.connect('./my_database.db')
cursor = con.cursor()
SQL = "INSERT INTO Course VALUES(1, 'Algorithm', '2021-03-01');"
cursor.execute(SQL)
SQL = "INSERT INTO Course VALUES(2, 'Data Structure', '2021-03-02');"
cursor.execute(SQL)
SQL = "INSERT INTO Course VALUES(3, 'Computer Architecture', '2021-03-05');"
cursor.execute(SQL)
con.commit()
SQL = "SELECT * FROM Course;"
cursor.execute(SQL)
print(cursor.fetchall())
con.close()
실행 결과는 다음과 같다.
[(1, 'Algorithm', '2021-03-01'), (2, 'Data Structure', '2021-03-02'), (3, 'Computer Architecture', '2021-03-05')]
※ 데이터 삭제 ※
데이터 삭제는 DELETE 구문을 사용하면 된다. 예를 들어 Course 테이블에 있는 모든 데이터(row)를 삭제하기 위해서는 다음과 같이 하면 된다. INSERT 구문과 마찬가지로 실행 뒤에 commit() 메서드를 이용해 DB에 반영할 수 있다. 위 코드를 실행하면 Course 테이블에 존재하는 모든 데이터가 삭제되기 때문에, 조회 결과가 없다.
import sqlite3
con = sqlite3.connect('./my_database.db')
cursor = con.cursor()
SQL = "DELETE FROM Course;"
cursor.execute(SQL)
con.commit()
SQL = "SELECT * FROM Course;"
cursor.execute(SQL)
print(cursor.fetchall())
con.close()
※ 하나의 테이블로 구성되는 간단한 데이터베이스 연동 프로그램 예시 ※
파이썬에서 SQLite 3 문법을 활용한 간단한 데이터베이스 연동 프로그램은 다음과 같다.
import sqlite3
database_name = './my_database.db'
con = sqlite3.connect(database_name)
cursor = con.cursor()
SQL = "CREATE TABLE IF NOT EXISTS Course (Course_ID int primary key not null, Course_Name text, Course_Date date);"
cursor.execute(SQL)
con.close()
def insert_course(course_id, course_name, course_date):
con = sqlite3.connect(database_name)
cursor = con.cursor()
SQL = "INSERT INTO Course VALUES(?, ?, ?);"
cursor.execute(SQL, (course_id, course_name, course_date))
con.commit()
con.close()
def insert_course_list(course_list):
con = sqlite3.connect(database_name)
cursor = con.cursor()
SQL = "INSERT INTO Course VALUES(?, ?, ?);"
cursor.executemany(SQL, course_list)
con.commit()
con.close()
def search_course_by_name(course_name):
con = sqlite3.connect(database_name)
cursor = con.cursor()
SQL = "SELECT * FROM Course WHERE course_name = ?;"
cursor.execute(SQL, (course_name, ))
return cursor.fetchall()
def search_course():
con = sqlite3.connect(database_name)
cursor = con.cursor()
SQL = "SELECT * FROM Course;"
cursor.execute(SQL)
return cursor.fetchall()
def search_course_order_by_date(limit):
con = sqlite3.connect(database_name)
cursor = con.cursor()
SQL = "SELECT * FROM Course ORDER BY date(course_date) ASC Limit ?;"
cursor.execute(SQL, (limit, ))
return cursor.fetchall()
def update_course_by_id(course_id, course_name, course_date):
con = sqlite3.connect(database_name)
cursor = con.cursor()
SQL = "UPDATE Course SET course_name = ?, course_date = ? WHERE course_id = ?;"
cursor.execute(SQL, (course_name, course_date, course_id))
con.commit()
con.close()
def delete_course_by_id(course_id):
con = sqlite3.connect(database_name)
cursor = con.cursor()
SQL = "DELETE FROM Course WHERE course_id = ?;"
cursor.execute(SQL, (course_id, ))
con.commit()
con.close()
delete_course_by_id(1)
delete_course_by_id(2)
delete_course_by_id(3)
delete_course_by_id(4)
delete_course_by_id(5)
insert_course(1, 'Algorithm', '2021-03-01')
insert_course(2, 'Data Structure', '2021-03-02')
insert_course(3, 'Computer Architecture', '2021-03-05')
course_list = [
(4, 'Programming Language', '2021-03-04'),
(5, 'Compiler', '2021-03-01'),
]
insert_course_list(course_list)
print(search_course_by_name('Algorithm'))
update_course_by_id(1, 'Cyber Security', '2021-03-03')
print(search_course())
print(search_course_order_by_date(100))
print(search_course_order_by_date(100)[::-1])
실행 결과는 다음과 같다.
[(1, 'Algorithm', '2021-03-01')]
[(1, 'Cyber Security', '2021-03-03'), (2, 'Data Structure', '2021-03-02'), (3, 'Computer Architecture', '2021-03-05'), (4, 'Programming Language', '2021-03-04'), (5, 'Compiler', '2021-03-01')]
[(5, 'Compiler', '2021-03-01'), (2, 'Data Structure', '2021-03-02'), (1, 'Cyber Security', '2021-03-03'), (4, 'Programming Language', '2021-03-04'), (3, 'Computer Architecture', '2021-03-05')]
[(3, 'Computer Architecture', '2021-03-05'), (4, 'Programming Language', '2021-03-04'), (1, 'Cyber Security', '2021-03-03'), (2, 'Data Structure', '2021-03-02'), (5, 'Compiler', '2021-03-01')]
※ 날짜 관련 코드 ※
참고로 현재 시각과 같은 날짜 및 시간 데이터가 필요할 때는 다음의 코드를 활용할 수 있다.
import sqlite3
database_name = './my_database.db'
con = sqlite3.connect(database_name)
cursor = con.cursor()
# 세계표준시
SQL = "SELECT strftime('%Y-%m-%d %H:%M:%S', 'now');"
cursor.execute(SQL)
print(cursor.fetchall())
# 현지시간
SQL = "SELECT strftime('%Y-%m-%d %H:%M:%S', 'now', 'localtime');"
cursor.execute(SQL)
print(cursor.fetchall())
실행 결과는 다음과 같은 형태를 갖는다.
[('2021-07-18 12:09:18',)]
[('2021-07-18 21:09:18',)]'기타' 카테고리의 다른 글
| 키움증권 웹 사이트에서 주식 시외가(시간 외 단일가) 보는 방법 (0) | 2021.07.20 |
|---|---|
| DB Browser for SQLite (DB4S) 설치 및 사용 방법 (0) | 2021.07.19 |
| 미리캔버스 무료 PPT 템플릿을 이용한 PPT/배너/썸네일 제작 방법! (0) | 2021.07.11 |
| 유튜버를 위한 단역 배우 섭외 방법 Feat. 인스타그램 DM (0) | 2021.07.10 |
| 주식 기본 용어 - HTS란 무엇일까? MTS, WTS에 대해서도 알아보자! (0) | 2021.07.10 |
미리캔버스 무료 PPT 템플릿을 이용한 PPT/배너/썸네일 제작 방법!
※ 이 글은 그냥 개인적으로 서비스를 사용해 본 후기 및 정보성 글입니다. 미리캔버스로부터 어떠한 지원도 받지 않았으며, 잘못된 정보가 포함되어있을 수 있습니다. ※
※ 미리캔버스 소개 ※
① 취직 및 이직을 준비할 때는 포트폴리오 PPT를 만들어야 하는 경우가 있다. 그리고 ② 대학교나 회사에서 발표할 때 다양한 PPT 양식이 필요한 경우도 많이 있다. 또한 ③ 유튜브 영상을 만들 때 썸네일이 필요한 경우가 많다. 이러한 상황에서 쉽게 사용할 수 있는 서비스로는 [미리캔버스]가 있다. 한 번 사용해 봤는데, 꽤 트렌디한 디자인 템플릿을 제공하고 있길래 리뷰해 보았다.
미리캔버스의 장점은 PPT 설치 없이 단순히 웹 화면에서 PPT를 만들 수 있다는 점이다. 즉, 파워포인트와 같은 프로그램을 설치할 필요 없이, 단순히 웹 브라우저에서 나의 포트폴리오 PPT를 만들거나 썸네일을 만들 수 있다. 미리캔버스는 다음의 웹 사이트에 방문하여 곧바로 사용할 수 있다.
▶ 미리캔버스 웹 사이트: https://www.miricanvas.com/
미리캔버스
저작권 걱정 없는 완전 무료 디자인툴 미리캔버스
www.miricanvas.com
접속 이후에는 다음과 같이 [회원가입] 버튼을 눌러서 가입을 진행한다.

다음과 같이 간단하게 회원가입을 진행할 수 있다.

※ 미리캔버스를 이용해 디자인하기 ※
미리캔버스를 이용해 디자인하는 방법은 간단하다. 로그인 이후에 [바로 시작하기] 버튼을 누르면 된다. 혹은 직접 디자인 페이지에 접속하여 프레젠테이션 자료를 제작할 수 있다.
▶ 미리캔버스 디자인 페이지: https://www.miricanvas.com/design
미리캔버스
저작권 걱정 없는 완전 무료 디자인툴 미리캔버스
www.miricanvas.com
디자인 페이지 접속 이후에는 다음과 같이 [해상도]를 설정한 뒤에 [검색어]를 입력하면 된다. 필자의 경우 [개발자 포트폴리오]라는 내용으로 검색했고, 눈에 띄는 포트폴리오 양식을 하나 선택했다.

이후에 [이 템플릿으로 덮어쓰기] 버튼을 누르면 다음과 같이 템플릿을 가져올 수 있다. 가져온 뒤에는 가장 먼저 [제목]을 내가 원하는 내용으로 바꾸어서 작성하면 된다.

이후에 자신의 입맛대로 PPT 내용을 바꾸면 된다. 필자의 경우 다음과 같이 첫 번째 페이지와 두 번째 페이지의 내용을 꾸며 보았다. 글자의 경우 단순히 더블 클릭하여 내용을 수정하면 되고, 이미지의 경우도 내가 원하는 이미지를 페이지 내부로 복사/붙여넣기해서 넣으면 끝이다.


※ 완성된 디자인(PPT) 다운로드하기 ※
완성된 PPT를 다운로드하는 방법은 간단하다. [다운로드] 버튼을 누르고 [웹용]인지 [인쇄용]인지 원하는 것을 선택하면 된다. 일반적으로 가장 많이 사용되는 설정은 [웹용]으로 다운로드하는 것이다.
▶ 웹용으로 다운로드
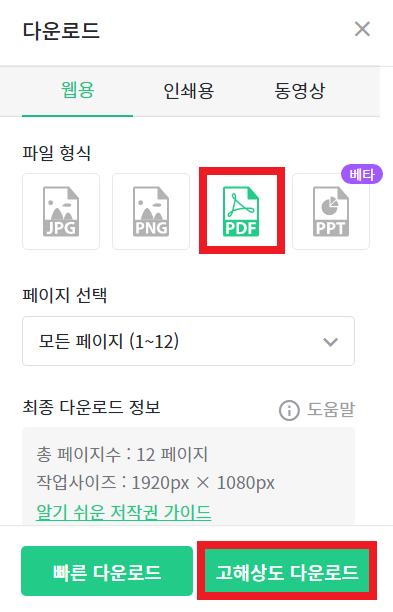
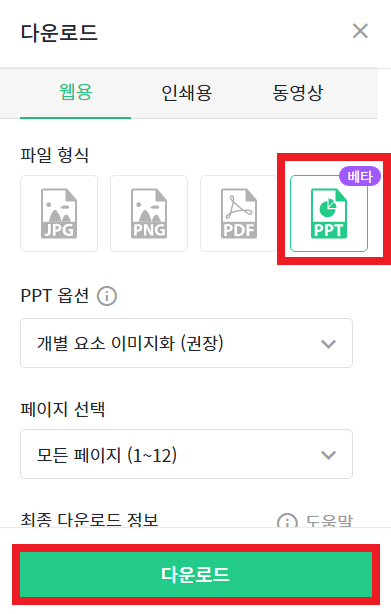
일반적으로 많이 사용되는 것은 [PDF] 형식으로 [고해상도 다운로드]를 하는 것이다. 이때 [고해상도 다운로드]로 다운로드를 하는 것을 추천한다. 빠른 다운로드를 이용하면, 확대했을 때 이미지의 해상도가 깨지는 경우가 있기 때문이다. 또한 [PPT] 형식으로 다운로드하는 것도 많이 사용된다. 이때 [텍스트 편집 가능]으로 선택하면, PPT에 사용되는 텍스트를 편집할 수 있지만, 경우에 따라서 PC에 폰트를 설치할 필요가 있다.
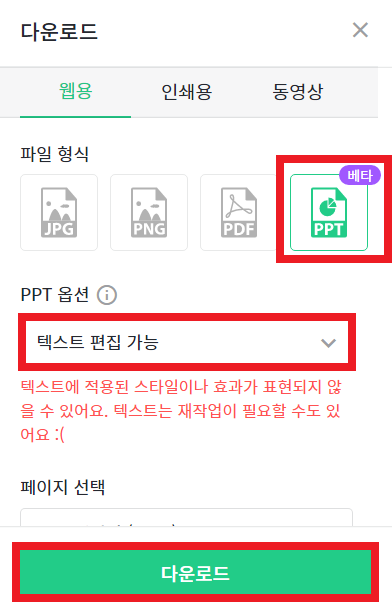
▶ 인쇄용으로 다운로드
인쇄용으로 다운로드를 진행하면, 고화질 PDF 자료를 얻을 수 있다. 다만 용량이 매우 크기 때문에, 말 그대로 인쇄 목적일 때만 사용하는 것이 좋다. 사실 [웹용]에서 [고해상도 다운로드]를 이용하더라도 충분히 좋은 해상도의 결과물을 다운로드할 수 있기 때문이다.

※ 참고사항 ※
또한 미리캔버스를 이용해 만든 결과물은 상업적으로 이용할 수 있다고 한다. 다만 이 글을 작성할 시점을 기준으로 몇 가지 저작권 관련 유의사항이 있다. 일반적인 저작권 관련 내용이기도 하므로 꼭 참고하자.
▶ 미리캔버스 템플릿에서 특정 요소 1개만 사용하는 것은 안 된다. (미리캔버스 PPT에 포함된 특정 그림 하나만 가져가 쓰는 등, PPT 파일에 포함된 요소를 다른 문서에 사용할 수 없다.)
▶ 미리캔버스 PPT에 포함되지 않은, 직접 추가한 요소는 본인이 직접 저작권을 확인해야 한다.
▶ 미리캔버스에서 만든 자료를 다운로드해 사용할 때는 폰트 저작권을 확인해야 한다. 예를 들어 PPT 양식을 다운로드할 때 [텍스트 편집 가능] 옵션으로 다운로드를 진행하는 경우, PC에 설치된 폰트를 사용하게 된다. 이때 PC에 설치된 폰트의 경우 미리캔버스에서 제공하는 것이 아니므로, 직접 폰트 저작권을 확인해야 한다.
▶ 미리캔버스에서 다운로드한 PPT 파일은 공유 및 배포가 불가능하다. 쉽게 말해 그냥 미리캔버스 사이트에서 바로 작업을 한 뒤에 PDF 파일로 내보내기하는 것이 가장 권장된다고 볼 수 있다.
▶ 미리캔버스에 포함된 인물 사진은 모델의 명예를 훼손하는 내용에 사용할 수 없다. (인물 사진에는 초상권 및 인격권이라는 것이 별도로 존재하므로, 모델이 불쾌감을 느낄만한 용도로 사용하면 안 된다. 당연하다.)
'기타' 카테고리의 다른 글
| DB Browser for SQLite (DB4S) 설치 및 사용 방법 (0) | 2021.07.19 |
|---|---|
| Python에서 SQLite3 사용하는 방법 핵심 요약 및 소스코드 예제! (0) | 2021.07.19 |
| 유튜버를 위한 단역 배우 섭외 방법 Feat. 인스타그램 DM (0) | 2021.07.10 |
| 주식 기본 용어 - HTS란 무엇일까? MTS, WTS에 대해서도 알아보자! (0) | 2021.07.10 |
| 키움증권 영웅문 4(HTS) - 주식 계좌 예수금, 주식 잔고, 총자산 조회하는 방법! (0) | 2021.07.09 |
유튜버를 위한 단역 배우 섭외 방법 Feat. 인스타그램 DM
필자는 구독자 13만 정도의 규모가 작은 유튜브 채널 하나를 운영하고 있다. 가끔 연기 콘텐츠(재미 위주의 개그 영상)를 올리고 있는데, 이러한 경우 배우가 필요하기 때문에 혼자서 영상을 만들기 쉽지 않다. 그래서 주변 친구를 배우로 섭외해야 할 필요가 있다. 사실 본인을 포함해 유튜버들이 간단하게 만드는 짧은 (재미 위주의) 영상들은 퀄리티 욕심이 없는 경우가 많다. 이럴 때는 그냥 간단히 주변 지인과 함께 영상을 촬영하는 것이다. 촬영도 내가 하고, 편집도 내가 하는 방식이다. 이렇게 하면 자유도가 높아서 배우들 의견을 반영하여 촬영을 여러 번 진행하는 것도 가능하다.
1. 지인 및 유튜버
주변에 알고 있는 지인이나 유튜버 친구에게 연락해서 같이 영상 찍으면 된다. 혹은 주변 친구들한테 물어보면 연극영화과와 같이 관련 학과를 다니고 있는 친구들을 소개받을 수 있다. 동아리 선후배한테 부탁하는 경우도 굉장히 흔하다.
2. 필름메이커스
단순히 친구를 섭외하는 것이 아니라 배우를 섭외하고 싶다면, 필름메이커스에 접속해서 [배우 프로필] 페이지로 해보자. 배우님들의 프로필이 올라와 있는데, 이메일 주소, 홈페이지나 인스타그램 아이디가 같이 적혀 있는 경우가 많다. 배우 정보 열람 자체는 무료인 것 같다. 개인적으로 메일이나 DM을 보내서 섭외하면 된다.
▶ 필름메이커스 액터스 커뮤니티 링크: https://www.filmmakers.co.kr/actorsForum
필름메이커스 커뮤니티 - 액터스 포럼
한국영화를 만드는 사람들, 스탭과 배우들의 커뮤니티 입니다.
www.filmmakers.co.kr
3. 각종 재능 판매 사이트
크몽과 같은 다양한 재능 판매 사이트에서 직접적으로 자신의 정보를 업로드하고, 활동하고 계시는 배우님들이 계시다. 이런 곳에서 배우를 검색하여 문의 및 섭외하는 방법도 있다.
※ 배우 컨택할 때 ※
- 만들고자 하는 싶은 영상에 잘 맞는 배우를 섭외해서 (인스타그램이나 이메일 주소)리스트를 정리한다. 차례대로 메일을 보내고, 거절 의사를 받으면 그다음 배우님께 연락하면 된다. 필자의 경우 10명 정도로 리스트를 꾸렸고, 한 분씩 연락 드렸다.
- 필자의 경우에는 먼 거리까지 불렀던 적이 있어서 섭외 비용을 더 많이 드렸다.
'기타' 카테고리의 다른 글
| Python에서 SQLite3 사용하는 방법 핵심 요약 및 소스코드 예제! (0) | 2021.07.19 |
|---|---|
| 미리캔버스 무료 PPT 템플릿을 이용한 PPT/배너/썸네일 제작 방법! (0) | 2021.07.11 |
| 주식 기본 용어 - HTS란 무엇일까? MTS, WTS에 대해서도 알아보자! (0) | 2021.07.10 |
| 키움증권 영웅문 4(HTS) - 주식 계좌 예수금, 주식 잔고, 총자산 조회하는 방법! (0) | 2021.07.09 |
| 주택 청약 통장 설명 - 주택 청약 종합 저축이란? 얼마씩 납부하면 될까? 10만 원 VS 2만 원, 국민주택 VS 민영주택 (0) | 2021.07.06 |
주식 기본 용어 - HTS란 무엇일까? MTS, WTS에 대해서도 알아보자!
※ HTS(Home Trading System) 설명 ※
HTS(Home Trading System)는 집에서 주식 거래를 할 수 있도록 하는 프로그램을 의미한다. 예를 들어 키움증권 영웅문 HTS 같은 프로그램이 있다. 흔히 집에서 전업으로 주식에 투자하는 사람들이 가장 많이 쓰는 프로그램 유형이다.
※ WTS(Web Trading System) 설명 ※
WTS(Web Trading System)는 별도의 프로그램 설치 없이 웹 사이트에서 바로 주식을 거래할 수 있는 시스템이다. 사실 주식이나 코인이나 많은 경우에 웹 기반으로 주식을 거래할 수 있도록 하는 경우가 있다. 키움증권도 2021년 7월을 기준으로 웹 트레이딩 시스템(WTS)를 제공하고 있다. 필자의 경우 WTS가 가장 편하다.

※ MTS(Mobile Trading System) 설명 ※
MTS(Mobile Trading System)는 스마트폰 앱 형태로 주식을 거래하는 시스템이다. 예를 들어 키움증권 영웅문S와 같은 앱이 대표적이다.

'기타' 카테고리의 다른 글
| 미리캔버스 무료 PPT 템플릿을 이용한 PPT/배너/썸네일 제작 방법! (0) | 2021.07.11 |
|---|---|
| 유튜버를 위한 단역 배우 섭외 방법 Feat. 인스타그램 DM (0) | 2021.07.10 |
| 키움증권 영웅문 4(HTS) - 주식 계좌 예수금, 주식 잔고, 총자산 조회하는 방법! (0) | 2021.07.09 |
| 주택 청약 통장 설명 - 주택 청약 종합 저축이란? 얼마씩 납부하면 될까? 10만 원 VS 2만 원, 국민주택 VS 민영주택 (0) | 2021.07.06 |
| 키움증권 영웅문 4(HTS) - 거래 내역 및 일별/월별/연도별 수익 조회(실현손익 및 수익률 조회) (0) | 2021.07.06 |
키움증권 영웅문 4(HTS) - 주식 계좌 예수금, 주식 잔고, 총자산 조회하는 방법!
※ 이 글은 부정확한 정보를 포함하고 있을 수 있습니다. ※
※ 예수금(현금) 확인하기 ※
영웅문 HTS에서 [주식주문] - [계좌정보] - [예수금] 창을 열면 현재 주식 계좌에 들어 있는 현금(주식을 구매할 수 있는 돈)을 확인할 수 있다. (참고로 실제로 내가 가진 예수금은 D+2를 기준으로 보면 된다.) 만약 주식 투자를 하기 위해서 주식 계좌에 돈을 입금하고 실제로 주식을 구매하지 않았으면, 예수금만 존재하는 것을 확인할 수 있다.

※ 주식 잔고(실시간 잔고) 확인하기 ※
영웅문 HTS에서 [주식주문] - [계좌정보] - [실시간 잔고] 창을 열면 현재 계좌별 잔고 금액을 확인할 수 있다. 기본적으로 잔고의 의미는 "주식잔고"를 의미한다. 아래 예시에서는 통장에 예수금만 넣은 뒤에, 실제로 주식을 구매하지 않았기 때문에, 주식 잔고는 0원인 것을 알 수 있다.

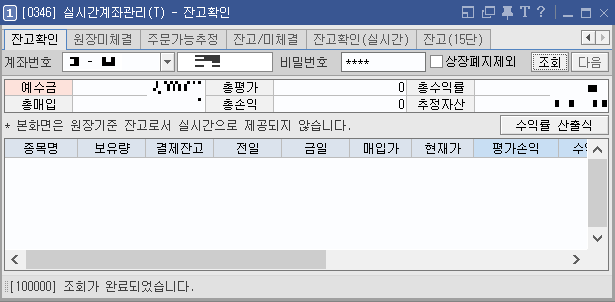
※ 자산(추정자산) 확인하기 ※
영웅문 HTS에서 [주식주문] - [계좌정보] - [잔고확인] 창을 열면 전체 잔고를 확인할 수 있다. 참고로 자산(추정자산)에는 주식과 예수금이 포함된다. 쉽게 말하자면 다음과 같다. 아래 예시에서는 주식을 구매하지 않고 예수금만 존재하므로, 예수금과 추정자산이 같은 것을 확인할 수 있다.
① 현재 돈으로 가지고 있는 돈(예수금) + ② 가지고 있는 주식들의 평가 금액 = 총자산(추정자산)이 된다.
'기타' 카테고리의 다른 글
| 유튜버를 위한 단역 배우 섭외 방법 Feat. 인스타그램 DM (0) | 2021.07.10 |
|---|---|
| 주식 기본 용어 - HTS란 무엇일까? MTS, WTS에 대해서도 알아보자! (0) | 2021.07.10 |
| 주택 청약 통장 설명 - 주택 청약 종합 저축이란? 얼마씩 납부하면 될까? 10만 원 VS 2만 원, 국민주택 VS 민영주택 (0) | 2021.07.06 |
| 키움증권 영웅문 4(HTS) - 거래 내역 및 일별/월별/연도별 수익 조회(실현손익 및 수익률 조회) (0) | 2021.07.06 |
| 잡플래닛(Jobplanet) 가입 이후 내가 원하는 기업의 리뷰를 보는(조회하는) 방법 (0) | 2021.07.06 |
주택 청약 통장 설명 - 주택 청약 종합 저축이란? 얼마씩 납부하면 될까? 10만 원 VS 2만 원, 국민주택 VS 민영주택
※ 이 글은 2021년 7월 기준으로 작성되었으며, 부정확한 정보를 포함하고 있을 수 있습니다. ※
※ 주택 청약이란? ※
주택 청약은 20살이 꼭 알아야 하는 것 중 하나다. 20대 중반까지도 필자의 주변에는 청약 통장이 없거나 무엇인지조차 모르는 경우가 많다. 어릴 때 미리 제대로 알아두지 않으면 나중에 크게 후회할 수 있으므로, 미리 알아 두면 좋다. 주택 청약을 처음 접하고 검색하면, 생소한 용어가 많아서 잘 이해가 되지 않을 수 있다. 초보자를 위해 정말 쉽게 설명하자면, 주택 청약은 ① 적금과 ② 집을 사기 위한(분양받기 위한) 발판의 역할을 동시에 수행하는 상품이다.
1) 적금: 청약 통장은 이자율이 나쁘지 않은 경우가 많아서, 적금 상품과 유사한 가치가 있다. 다만 적금의 경우 3~10년 만기로 만드는 경우가 많지만, 주택 청약은 일반적으로 그것보다 더욱 장기적인 기간의 적금 통장이라고 보면 된다. 단, 청약 통장은 납입 기간과 횟수가 중요하기 때문에, 한 번 만들면 일반적인 적금처럼 쉽게 깨지 못한다. 필자 또한 금리(이자) 목적으로 청약에 돈을 많이 넣는 것을 추천하지는 않는다.
2) 집을 사기 위한 발판: 좋은 집에 청약에 당첨되어 사는 경우(분양받는 경우), 주변 아파트 시세에 비해 저렴한 분양가로 구매할 수 있다. 가만히 앉아서 몇억을 먹는 경우가 많다. 실제로 30대 중후반 형들 얘기를 들어 보면, 주변 친구들이 청약에 당첨되어 몇억씩 차익을 얻는 것을 실제로 지켜보게 된다고 한다.
3) 기타 혜택: 주택 청약이 있으면, 소득 공제나 대출 우대 금리의 효과를 누릴 수 있다. 실제로 많은 직장인들이 주택 청약을 통한 소득 공제 절세 효과를 누리고 있다. 또한 디딤돌 대출과 같은 대출 상품에서의 우대 금리 효과가 있는 것으로 잘 알려져 있다.
※ 그래서 어떻게 하면 될까? ※
청약에 대해서 아무것도 모르는 사람은 어떻게 하면 될까? 필자가 추천하는 바는 다음과 같다. 아래 두 가지만 기억하자. 물론 이것은 필자의 추천이며, 최종적인 선택은 스스로 찾아보고 본인이 하는 것이다.
① 늦어도 20대 초반에는 주택 청약에 가입하자. 은행에서 [주택청약종합저축] 통장을 개설하면 된다.
② 한 달에 10만 원씩 청약 통장으로 자동 이체를 한다. 단, 주택 청약 통장에 한 번 들어간 돈은 주택에 당첨되거나 자신이 직접 해지하기 전에는 돈을 인출(꺼내기)하는 것이 불가능하다.
필자의 주변 친구들을 보면, 어릴 때부터 부모님이 청약 통장을 만들어 돈을 넣어 주거나, 본인이 직접 관심을 갖고 청약 통장을 만드는 경우를 보았다. (특히 성년에 이르기 전에도 24회차에 대한 납입 금액은 인정해 주기 때문에, 어릴 때 부모님이 청약 통장을 만들어 돈을 넣어 준 경우에는 남들보다 2년 더 앞서나갈 수 있다.) 슬프게도 필자의 경우 재테크나 부동산에 정보가 밝지 못해서 20대 초중반에 청약 통장을 만들었는데, 필자처럼 늦었다고 하더라도 주택 청약에는 일단 가입하는 것을 추천한다. 금액을 납부하지 못한다고 하더라도 일단 청약 통장은 최대한 빠르게 만드는 편이 유리하다.
또한 주택 청약의 경우 [청년우대형주택종합저축통장]이 있다. 이것은 주택 청약 중에서도 연소득이 낮은 청년층을 위한 청약 상품이다. 사회 초년생이라면 청년 우대형 주택 청약을 이용하는 것을 추천한다. 특히 무주택자(자신 명의의 집이 없는 사람)에게 소득공제 효과가 있기 때문에 주택 청약은 절세 상품으로도 활용된다. 참고로 이미 주택청약종합저축에 가입한 사람도 청년 우대형 가입 요건을 만족하면, 청년 우대형 청약 통장으로 전환이 가능한 것으로 알려져 있다.
기본적으로 청약 통장은 매월 2만 원 이상 50만 원 이하의 금액을 자유롭게 납입할 수 있도록 되어 있다. (단, 잔액이 1,500만 원 이하인 경우 월 50만 원을 초과해서 1,500만 원까지 일시 납입할 수 있다.) 하지만 국민주택 청약을 할 때는 한 달에 10만 원의 금액까지만 납입 금액으로 인정해준다. 만약 한 번에(특정한 달에) 1,000만 원을 넣었다고 해도, 10만 원만큼만 [인정 금액]으로 잡히는 것이다. 이 점을 감안하여 기본적으로 10만 원씩 분할 납부를 하는 것을 추천한다. 필자 개인적으로는 그냥 청약에는 10만 원씩만 꼬박꼬박 넣으면서, 남는 돈이 있다면 다른 투자 상품(더 수익률이 좋은 상품)을 찾는 것을 추천한다.
※ 주택 청약 통장에 돈이 묶여 있는데, 목돈이 필요하다면? ※
주택 청약 통장에 돈이 묶여 있을 때, 목돈이 필요한 경우가 있다. 사실 이럴 때는 주택 청약 통장을 담보로 걸고 대출을 받을 수 있다. 다시 말해 청약 통장을 해지하지 않고도, 일반적으로 낮은 이자율로 대출이 가능하다. 담보대출을 받더라도 통장 가입기간, 납입 회차, 가점에 영향을 주지 않는다. 필자가 아는 사람의 경우 주택 청약 통장에 몇천만 원의 돈이 들어 있다. 나중에 급하게 돈이 필요하다면 대출을 받을 수 있어서 사실 큰 문제가 되지 않는다.
※ 민영주택 VS 국민주택 ※
미리 청약을 만들어 놓으면, 나중에 민영주택과 국민주택 청약 공고가 나왔을 때, 청약을 넣을 수 있다. 이때 민영주택과 국민주택에 대해서 아는 것이 중요하다.
① 국민주택: 국민 주택은 국가, 지자체, LH 등이 분양 주체다. 기본적으로 무주택 세대주가 청약을 신청할 수 있다. 1순위 내에서는 40제곱미터 초과의 집인 경우 납입 인정 금액(저축 총액)이 많은 사람이 높은 우선순위를 갖는다. 이때 매달 최대 10만 원까지만 납입 금액을 인정하기 때문에, 가능하다면 10만 원씩 꾸준히 넣어서 납입 인정 금액을 최대로 높이는 편이 유리하다.
② 민영주택: 래미안, 자이와 같은 민간 건설 업자가 분양 주체다. 1주택자도 청약을 신청할 수 있지만, 당첨되기는 어렵다. 참고로 예치 금액에 따라서 평수가 결정되며, 전략적으로 1,500 만 원 정도로 큰 돈이 넣어버리고 평수 상관없이 신청하는 경우도 있다. 민영주택의 예치 금액 조건에서는 매달 최대 10만 원과 같은 기준이 없기 때문에, 한 번에 많은 돈을 넣어서 예치 금액을 만족하는 것이 가능하다. 1순위 내에서는 가점제의 경우 (무주택 기간, 부양가족 수, 가입기간)에 따라서 점수를 부여한다. 좋은 아파트 분양의 경우 가점제에 대하여 만점에 가까운 수준으로 커트라인이 형성되는 경우가 많다. 실제로 무주택 기간 15년 이상, 가입기간 15년 이상, 부양가족 수 3~4명 수준으로 커트라인이 형성된 경우를 쉽게 찾아볼 수 있다. 추첨제의 경우 말 그대로 추첨(운)으로 당첨 여부를 결정한다.
※ 1주택자는 청약 통장을 유지해야 할까? ※
기본적으로 청약 제도는 무주택자(0주택자로, 자기 소유의 집이 없는 사람)에게 유리하다. 하지만 1주택자도 가능성은 희박하지만, 청약 당첨 가능성이 있다. 그래서 흔히 두 가지 의견으로 많이 나뉜다.
① 1주택자도 청약 통장을 유지해야 한다는 의견: 기본적으로 청약 통장을 오래 보유할수록 가점이 주어지기 때문에, 자기 소유의 집이 있다고 해도 일단은 유지하는 편이 장기적으로 리스크가 적다는 의견이다. 특히 국민주택에서 순차제(납입 인정 금액이 클수록 우선순위를 가짐)을 고려했을 때, 여유가 있다면 계속 10만 원씩 넣는 것이 유리할 수 있다.
② 1주택자는 청약 통장을 해지해야 한다는 의견: 1주택자의 경우 어차피 청약 당첨 가능성이 매우 희박하다. 추첨제 비율이 높아진다고 해도, 애초에 추첨제는 경쟁률이 매우 높기 때문에, 당첨된다는 보장이 없다. 희박한 확률에 기대하기보다는 차라리 재개발·재건축 투자를 하거나, 좋은 시기에 적절한 아파트를 구매하여 시세 차익을 노리는 편이 낫다는 주장이다.
필자의 의견은 어떨까? 필자는 현재 1주택자이다. 하지만 여전히 매달 10만 원씩 납부하고 있다. 그다지 큰돈이 아닐뿐더러, 필자는 미래에 대한 리스크를 줄이기 위한 비용으로 생각하며 납부하고 있다. 필자의 주변에는 1주택자인 형들이 많은데, 대체로 필자와 같이 10만 원씩 납부하고 있다. 국민주택은 기본적으로 무주택 세대주일 때 청약이 가능하지만, 나중에 무주택자(3년 이상 무주택자)가 될지도 모르기 때문에, 그대로 청약을 유지하는 편이 리스크가 적을 수 있다. 예를 들어 유주택자였다가 집을 팔아서 무주택이 돼 3년만 채우면 납입 인정 금액에 따라서(순차제로) 당첨될 수 있다.
'기타' 카테고리의 다른 글
| 주식 기본 용어 - HTS란 무엇일까? MTS, WTS에 대해서도 알아보자! (0) | 2021.07.10 |
|---|---|
| 키움증권 영웅문 4(HTS) - 주식 계좌 예수금, 주식 잔고, 총자산 조회하는 방법! (0) | 2021.07.09 |
| 키움증권 영웅문 4(HTS) - 거래 내역 및 일별/월별/연도별 수익 조회(실현손익 및 수익률 조회) (0) | 2021.07.06 |
| 잡플래닛(Jobplanet) 가입 이후 내가 원하는 기업의 리뷰를 보는(조회하는) 방법 (0) | 2021.07.06 |
| 윈도우10에서 문서(파일) 내용으로 문서(파일) 검색하는 방법 (0) | 2021.07.05 |
키움증권 영웅문 4(HTS) - 거래 내역 및 일별/월별/연도별 수익 조회(실현손익 및 수익률 조회)
※ 이 글은 부정확한 정보를 포함하고 있을 수 있습니다. ※
※ 거래 내역 조회 ※
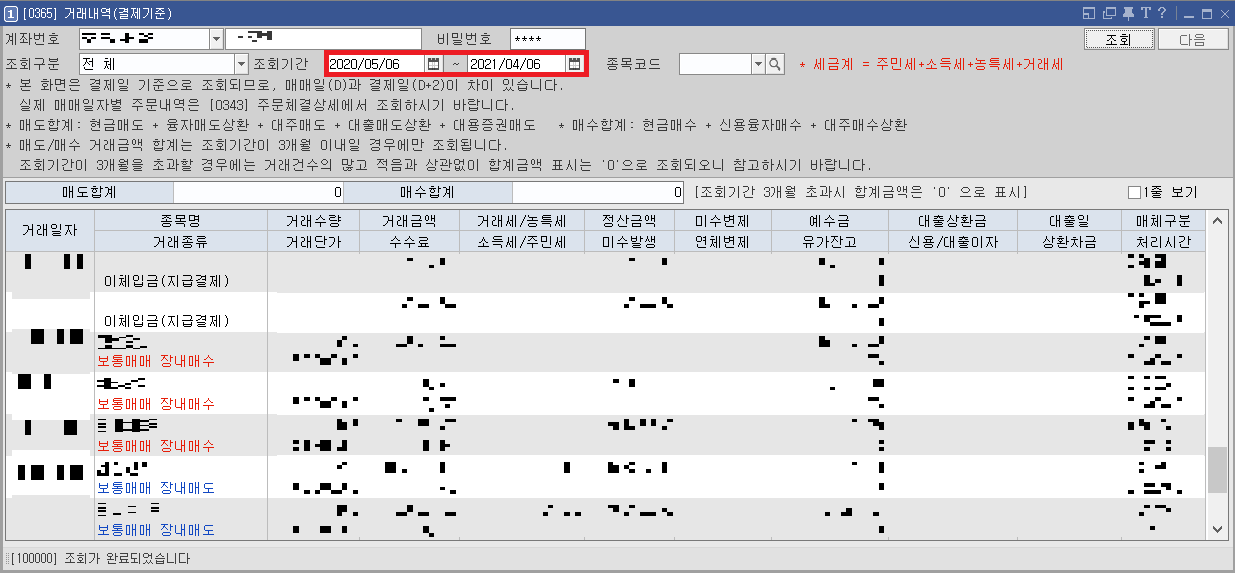
[주식주문] - [거래내역] - [거래내역(결제기준)] 창을 띄운 뒤에 [조회기간]을 설정하여 [조회]버튼을 누른다. 이때 최대 1년까지의 거래내역을 조회할 수 있다. 만약에 거래내역이 많아서 한 번에 모든 거래내역이 조회되지 않는다면 [다음] 버튼을 연타하여 모든 거래내역을 전부 불러와 출력할 수 있다.
결과는 다음과 같다. 거래 종류로는 흔히 세 가지를 확인할 수 있다.
1) 이체입금: 외부 은행에서 주식 계좌로 돈이 들어오는 경우
2) 보통매매 장내매수: 주식을 구매하는 경우
3) 보통매매 장내매도: 주식을 판매하는 경우
또한 어떠한 주식을 얼마에 몇 개를 샀는지 정확히 출력되는 것을 알 수 있다. 그리고 특정 시점에서의 예수금(통장에 들어있는 돈)이 얼마인지 확인할 수 있다.
※ 계좌별 실현손익 조회 ※
[주식주문] - [계좌정보] - [일별실현손익]에 들어간다. 그러면 계좌에 따른 손익 정보가 출력되는 것을 알 수 있다. 정확히 어떤 날짜에 얼마만큼의 주식을 매도했고, 이때 실현손익이 얼마인지 알려준다. 만약에 내가 매수할 때보다 비싸게 팔았다면 실현 손익이 크게 나올 것이다. 실현손익은 실제로 매도가 이루어졌을 때를 기점으로 출력되기 때문에, 판매한 주식의 개수가 너무 많지만 않다면 꽤 보기 좋게 출력될 것이다.
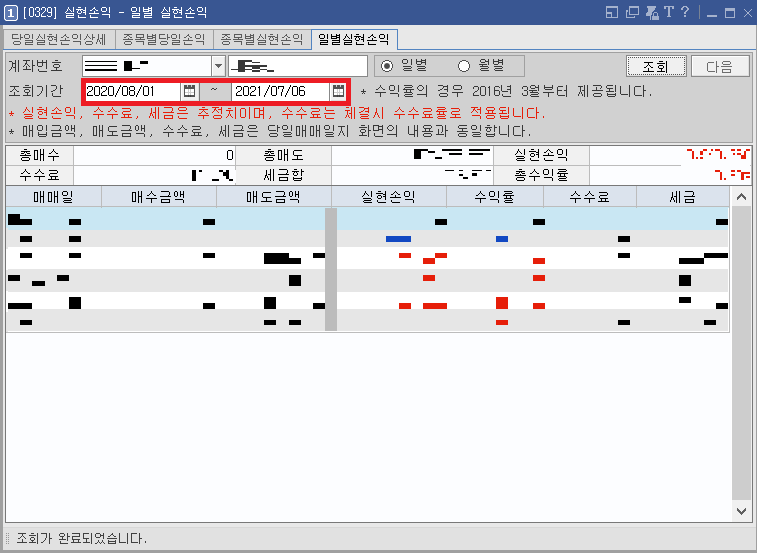
※ 계좌별 수익률 조회 ※
[주식주문] - [수익률현황] - [월별계좌수익률현황]에 들어간다. 월별로 계좌 수익률을 보여주는데, 실제로 아무런 거래도 일어나지 않은 달을 포함하여 모든 달에 대한 수익률 정보를 보여준다. 필자는 개인적으로 [누적손익]을 보기 위해서 월별 계좌 수익률 현황에 들어오곤 한다.

'기타' 카테고리의 다른 글
| 키움증권 영웅문 4(HTS) - 주식 계좌 예수금, 주식 잔고, 총자산 조회하는 방법! (0) | 2021.07.09 |
|---|---|
| 주택 청약 통장 설명 - 주택 청약 종합 저축이란? 얼마씩 납부하면 될까? 10만 원 VS 2만 원, 국민주택 VS 민영주택 (0) | 2021.07.06 |
| 잡플래닛(Jobplanet) 가입 이후 내가 원하는 기업의 리뷰를 보는(조회하는) 방법 (0) | 2021.07.06 |
| 윈도우10에서 문서(파일) 내용으로 문서(파일) 검색하는 방법 (0) | 2021.07.05 |
| 농협 주택 청약 통장 - 인터넷 뱅킹으로 미납회차 돈 넣기, 납입 인정 금액 확인, 청약 순위 확인, 자동 이체 납입 금액 변경, 선납 방법! (1) | 2021.07.05 |
