[코드포스] Codeforces Round #637 (Div. 2)
대회 링크: http://codeforces.com/contest/1341
A번 문제: http://codeforces.com/contest/1341/problem/A
이 문제는 n개의 쌀알의 무게의 범위가 각각 [a - b, a + b]일 때, 이 쌀알들의 무게를 모두 더한 것이 [c - d, c + d]에 들어갈 수 있는지 물어보고 있다.
입력으로는 매 테스트 케이스마다 n, a, b, c, d가 입력된다.
예를 들어 7 20 3 101 18이 들어오게 되면, 각 쌀알의 무게는 [17, 23] 범위 중 하나가 된다. 이 때, 모든 쌀알의 무게를 더한 것이 [83, 119] 범위 중 하나가 될 수 있어야 한다는 것이다. 이 경우, 각 쌀알의 무게가 17이라고 하면, 모든 쌀알의 무게를 더한 것은 119가 되므로 조건을 만족한다. 따라서 "Yes"를 출력하게 된다.
[ 문제 해설 ]
이 문제는 단순히 [(a - b) * n, (a + b) * n]이 [c - d, c + d]과 교차하는지(Intersecting) 확인하면 된다.
따라서, 일직선 상의 두 직선이 교차하는 지 확인하는 알고리즘을 사용하면 된다.
만약에 (line_1.left <= left_2.right and line_1.right >= line_2.left)이 성립한다면, 교차한다고 볼 수 있다.
[ 정답 코드 ]
for _ in range(int(input())):
n, a, b, c, d = map(int, input().split())
# 일직선상의 두 직선이 교차하는지 검사
if (a - b) * n <= c + d and (a + b) * n >= c - d:
print("Yes")
else:
print("No")
B번 문제: http://codeforces.com/contest/1341/problem/B
산에는 고점(Peek)들이 존재하는데, 뾰족하게 올라온 부분이라고 보면 된다. 이 때, 제일 왼쪽과 제일 오른쪽은 제외한다.
예를 들어 산 데이터가 [3, 1, 4, 1, 5, 9, 2, 6]이라고 하면, 3의 위치와 6의 위치에 고점(Peeks)들이 있는 것이다.
문제에서는 K만큼을 차지하는 길이의 문을 산에 던진다. 산으로 던진 문은 고점에 닿은 위치에서 쪼개진다고 한다. 이 문제에서는 문이 최대한 많은 개수로 쪼개지길 원한다.
예를 들어 산 데이터가 [3, 2, 3, 2, 1]이고, 문의 길이가 3이라면,
i) 1번째 위치에 놓았을 때: [3, 2, 3, 2, 1] → 쪼개진 문의 개수는 1개
ii) 2번째 위치에 놓았을 때: [3, 2, 3, 2, 1] → 쪼개진 문의 개수는 2개
iii) 3번째 위치에 놓았을 때: [3, 2, 3, 2, 1] → 쪼개진 문의 개수는 1개
위와 같이 쪼개진 문의 개수가 나열된다. ii)의 경우에는 3의 위치에 있는 고점(Peek)이 문을 정확히 반으로 가르기 때문에 쪼개진 문의 개수가 2개가 되는 것이다. i)와 iii)의 경우에는 문이 쪼개지지 않는다.
[ 문제 해설 ]
일단, 길이가 K인 모든 구간을 계산한다고 해보자. 그렇다면, 다음의 공식이 성립한다.
쪼개지는 문의 개수 = 그 구간에 포함된 고점 개수 - 구간의 시작이 고점인지의 여부 - 구간의 끝이 고점인지의 여부
이 문제는 투 포인터(Two Pointers) 알고리즘으로 해결할 수 있다. 투 포인터 알고리즘은 특정 구간안에서의 어떠한 계산을 선형 시간에 해결하기 위해 효과적으로 사용할 수 있다. (정확히 구간이 K칸을 차지할 때만 계산하지 않고, K이하면 계산하도록 하였다. 어차피 이렇게 해도 최적의 해가 나온다.)
[ 정답 코드 ]
for _ in range(int(input())):
n, k = map(int, input().split())
data = list(map(int, input().split()))
# 모든 고점(Peak) 정보를 입력 받기
peaks = set()
for i in range(1, n - 1):
if data[i - 1] < data[i] and data[i] > data[i + 1]:
peaks.add(i)
''' 투 포인터(Two Pointers) 알고리즘 수행 '''
end = 0 # 구간의 끝 인덱스
peak_count = 0 # 구간에 존재하는 고점(Peak)의 개수
result = 0
index = 0
for start in range(n): # 구간의 시작 인덱스를 증가시키며
while end < n and end - start < k:
# 끝 구간이 고점(Peak)이라면 고점의 개수 증가
if end in peaks:
peak_count += 1
# 구간의 시작 혹은 끝이 고점이라면 1씩 빼기
additional = 0
if start in peaks:
additional -= 1
if end in peaks:
additional -= 1
# 가장 많이 쪼개지는 경우를 저장
if result < peak_count + additional:
result = peak_count + additional
index = start
# 시작 구간이 고점(Peak)이라면 고점의 개수 증가
if start in peaks:
peak_count -= 1
end += 1
print(result + 1, index + 1)
C번 문제: http://codeforces.com/contest/1341/problem/C
이 문제는 설명이 길어서 문제 설명은 생략한다.
[ 문제 해설 ]
기본적으로 문제에서는 1부터 n까지의 수를 차례대로 놓아서 순열을 만든다고 한다.
이 문제는 문제 해결의 아이디어만 떠올릴 수 있으면 바로 해결할 수 있다.
문제 해결의 아이디어는 바로 특정한 위치에 i번째 수를 놓게 되면, 오른쪽 끝에 도달할 때까지 1씩 증가시키며 그 다음수를 놓아야 한다는 사실이다. 예를 들어 n = 5일 때, 1을 3번째 자리에 놓게 되면, 무조건 2는 4번째 자리에 두고, 3은 5번째 자리에 두어야 한다.
한 번 순열 [2, 3, 4, 5, 1]을 생각해보자. 이것은 만들 수 있는 순열이다. 1을 5번째 자리에 두고, 2를 1번째 자리에 두면 자연스럽게 [2, 3, 4, 5, 1]가 형성된다. 따라서 "Yes"를 출력하면 된다.
반면에 순열 [1, 3, 2]를 생각해보자. 이것은 만들 수 없는 순열이다. 1을 1번째 자리에 두면, 무조건 [1, 2, 3]만을 만들게 된다. 따라서 "No"를 출력하면 된다.
[ 정답 코드 ]
for _ in range(int(input())):
n = int(input())
data = list(map(int, input().split()))
# 각 수별로 몇 번째 자리에서 등장하는지 기록
my_map = [0] * (n + 1)
for i in range(n):
my_map[data[i]] = i + 1
# n + 1의 위치를 '끝'으로 기록 (왼쪽에서 오면, 여기에서 멈추도록)
blocked = set()
blocked.add(n + 1)
now = 1
result = True
# 수를 1부터 차례대로 확인하며
while now < n:
# 해당 수가 등장한 위치를 가져오기
index = my_map[now]
# 해당 수의 위치를 '끝'으로 기록 (왼쪽에서 오면, 여기에서 멈추도록)
blocked.add(index)
# 더 이상 오른쪽으로 갈 수 없을 때까지 1씩 증가시키며 이동
if index + 1 not in blocked:
# 만약, 오른쪽에 있는 수가 자기보다 1만큼 큰 수가 아니라면
if my_map[now + 1] != index + 1:
result = False
break
now += 1
if result:
print("Yes")
else:
print("No")
'알고리즘 대회' 카테고리의 다른 글
| [코드포스] Codeforces Round #640 (Div. 4) (0) | 2020.05.10 |
|---|---|
| 코드포스(Codeforces) 대회에서 소스코드 해킹(Hack) 방법 (0) | 2020.05.10 |
| [코드포스] Codeforces Round #634 (Div. 3) (0) | 2020.04.23 |
| [코드포스] Codeforces Round #636 (Div. 3) (0) | 2020.04.23 |
| 알고리즘 대회를 위한 C++ 대회 환경 구성하기 (1) | 2018.11.27 |
경기도 재난 지원금 (재난기본소득) 온라인 신청 방법
최근 코로나19(COVID-19)로 인하여 국가적인 재난 상황입니다. 그래서 경기도에서는 2020년 4월부터 7월까지 경기도민들에게 경기도 재난기본소득을 달마다 지급합니다. 신청은 경기지역화폐 사이트에서 진행할 수 있습니다.
▶ 경기지역화폐 사이트: http://www.gmoney.or.kr/
웹 사이트에 방문한 뒤에 [재난기본소득 신청] 버튼을 클릭합니다.

이후에 [온라인 신청]을 눌러서 온라인으로 신청을 진행할 수 있습니다.

약관에 동의합니다.

이후에 경기도 내에서의 시군을 선택합니다. 이후에 카드 번호를 입력해야 하는데, 저는 경기지역화폐카드를 신청해서 수령을 한 상태이기 때문에 해당 카드 번호를 입력했습니다.

이후에 다음과 같이 관할주민센터 동명, 세대주 성명, 세대주와의 관계를 입력해야 합니다. 세대주와의 관계를 입력할 때는 세대주를 기준으로 입력하므로, 세대주가 부모님이라면 본인을 '자녀'라고 넣으셔야 합니다.

조회가 완료되면 다음과 같이 최종적으로 [신청 완료]를 진행하실 수 있습니다.

'기타' 카테고리의 다른 글
| 가상 번호 만들어서 카카오톡 계정 2개 사용하기 (+ 카카오톡 계정 전화번호 교체 방법) (2) | 2020.05.05 |
|---|---|
| 크롬(Chrome) 브라우저가 느리게 동작하거나 인터넷 접속이 안 될 때 해결 방법 모음 (ERR_TIMED_OUT) (3) | 2020.05.05 |
| 윈도우(Windows)에서 make 명령 사용하기 (0) | 2020.04.20 |
| 리눅스(Linux)에서 윈도우(Windows)용 실행 파일을 컴파일하는 방법 (크로스 컴파일) (0) | 2020.04.20 |
| Oracle VM VirtualBox의 게스트(Guest) OS에서 USB 사용하기 (0) | 2020.04.20 |
[코드포스] Codeforces Round #634 (Div. 3)
대회 링크: http://codeforces.com/contest/1335
A번 문제: http://codeforces.com/contest/1335/problem/A
n개의 사탕을 두 사람이 나눠야 한다. 두 사람이 가지는 사탕의 수를 각각 a와 b라고 하자. 이 때 a > 0, b > 0, a > b가 되도록 하는 경우의 수를 출력하는 문제다.
[ 문제 해설 ]
예를 들어, 다음과 같은 n들을 고려해보자.
n = 1일 때는 조건에 맞게 나눌 수 있는 경우가 없다.
n = 2일 때는 조건에 맞게 나눌 수 있는 경우가 없다.
n = 3일 때는 (2, 1)로 나눌 수 있으므로 경우의 수는 1이다.
n = 4일 때는 (3, 1)로 나눌 수 있으므로 경우의 수는 1이다.
n = 5일 때는 (3, 2), (4, 1)로 나눌 수 있으므로 경우의 수는 2다.
n = 6일 때는 (4, 2), (5, 1)로 나눌 수 있으므로 경우의 수는 2다.
n = 7일 때는 (4, 3), (5, 2), (6, 1)로 나눌 수 있으므로 경우의 수는 3이다.
결과적으로 경우의 수는 0, 0, 1, 1, 2, 2, 3, 3, 4, 4, ... 순으로 나열되는 것을 알 수 있다. 따라서 단순히 (n - 1)를 2로 나눈 몫을 출력하면 그것이 정답이다.
[ 정답 코드 ]
for _ in range(int(input())):
n = int(input())
print((n - 1) // 2)
B번 문제: http://codeforces.com/contest/1335/problem/B
길이가 n인 문자열 s를 만드는데, 길이가 a인 모든 부분 문자열들이 b개의 서로 다른 문자들로 구성되도록 하는 문제다. 조건만 만족한다면 길이가 n인 문자열 s를 아무거나 출력해도 된다.
예를 들어 n = 7, a = 5, b = 3일 때를 고려해보자. 이 때는 tleelte가 정답이 될 수 있다.
[ 문제 해설 ]
이 문제는 길이가 a인 부분 문자열 k를 만들어서 순환적으로 출력하면 된다. n = 7, a = 5, b = 3일 때를 생각해보자.
k = ['a', 'b', 'c', 'a', 'a']로 만들게 되면, 예를 순환적으로 출력하면 다음과 같다.
{'a', 'b', 'c', 'a', 'a', 'a', 'b', 'c', 'a', 'a', 'a', 'b', 'c', 'a', 'a', ...}
이렇게 되면, 길이가 5인 어떤 부분 문자열도 3개의 서로 다른 문자로 구성된다. 즉, 문제 해결의 아이디어는 앞에서부터 b만큼은 'a'부터 시작해 차례대로 문자를 담고, 나머지는 그냥 'a'만 나열하도록 문자열 k를 만든다. 이후에 k를 순환적으로 출력하면 정답이다.
[ 정답 코드 ]
for _ in range(int(input())):
n, a, b = map(int, input().split())
k = []
# 앞의 b만큼은 'a'부터 시작해 차례대로 문자를 담기
for i in range(b):
k.append(chr(ord('a') + i))
# 나머지는 그냥 'a'만 나열하도록 문자를 담기
for i in range(a - b):
k.append('a')
# 이제 문자열 k를 순환적으로 출력하면 정답
for i in range(n):
print(k[i % a], end='')
print()
C번 문제: http://codeforces.com/contest/1335/problem/C
n명의 학생을 두 팀으로 나눌 때, 첫 번째 팀은 모두 스킬이 다르고 두 번째 팀은 모두 스킬이 같도록 구성하고자 한다. 단, 두 팀의 인원이 동일해야 한다. 이 때 팀의 가능한 최대 인원 수를 찾는 문제다.
예를 들어 n = 7이고, 학생들의 스킬이 {4, 2, 4, 1, 4, 3, 4}라면 다음과 같이 나누었을 때 각 팀의 인원수가 제일 많다.
첫 번째 팀: {1, 2, 3}
두 번째 팀: {4, 4, 4}
이 때 팀의 인원수는 3이다.
[ 문제 해설 ]
이 문제는 각 스킬의 번호마다 등장 횟수를 체크(count_map)하고, 스킬의 번호가 총 몇 개 있는지 체크(distinct_count)하여 해결할 수 있다.
예를 들어 위의 예시에서는 각 스킬의 번호마다 등장 횟수가 다음과 같다.
1번 스킬: 1명
2번 스킬: 1명
3번 스킬: 1명
4번 스킬: 3명
또한 전체 스킬의 번호가 총 4개가 된다.
이제 각 스킬 번호에 대해서, 그 스킬을 가진 학생들만을 오른쪽 팀에 두는 경우들을 고려하면 된다. 다만, 한 명의 학생은 왼쪽 팀에 넘겨 주어도 괜찮다. 이를 이용해 정답 코드를 작성할 수 있다.
[ 정답 코드 ]
for _ in range(int(input())):
n = int(input())
data = list(map(int, input().split()))
result = 0
count_map = {}
distinct_count = 0
for i in data:
if i not in count_map:
count_map[i] = 1
distinct_count += 1
else:
count_map[i] += 1
# 각 스킬 번호를 확인하며
for (key, value) in count_map.items():
# 해당 스킬을 가진 학생을 두 번째 팀에 두는 경우를 고려하여, 최대 인원 수 찾기
now = max(min(count_map[key], distinct_count - 1), min(count_map[key] - 1, distinct_count))
result = max(result, now)
print(result)
D번 문제: http://codeforces.com/contest/1335/problem/D
이 문제는 전형적인 스도쿠 퍼즐이 무엇인지 알아야 한다. 다음과 같이 이미 완성된 스도쿠 보드가 있다고 해보자.

이 때 안티 스도쿠란, 다음의 조건을 만족하는 보드를 말한다.
1) 각 행에 대하여 최소한 두 개의 원소가 같아야 한다.
2) 각 열에 대하여 최소한 두 개의 원소가 같아야 한다.
3) 모든 3 x 3 블럭(Block)에서 최소한 두 개의 원소가 같아야 한다.
이번 문제는 완성된 스도쿠 보드가 입력되었을 때, 안티 스도쿠를 만들어 출력하는 문제다.
[ 문제 해설 ]
깊게 고민하면 문제 해결 아이디어를 떠올릴 수 있다. 다양한 방법이 있을 수 있겠지만, 저자는 다음과 같이 풀었다. 바로 다음의 9가지 위치에 있는 원소들의 값을 기존의 값이 아닌 다른 아무 값으로나 바꾸면 된다.

따라서 9개의 칸에 있는 각 원소의 값이 1인 경우에는 2로 바꾸고, 1이 아닌 경우에는 1로 바꾸면 된다.
[ 정답 코드 ]
for _ in range(int(input())):
data = []
for i in range(9):
data.append(list(map(int, input())))
# 9가지 위치의 값을 기존의 값이 아닌 다른 값으로 변경
data[0][0] = 2 if data[0][0] == 1 else 1
data[1][3] = 2 if data[1][3] == 1 else 1
data[2][6] = 2 if data[2][6] == 1 else 1
data[3][1] = 2 if data[3][1] == 1 else 1
data[4][4] = 2 if data[4][4] == 1 else 1
data[5][7] = 2 if data[5][7] == 1 else 1
data[6][2] = 2 if data[6][2] == 1 else 1
data[7][5] = 2 if data[7][5] == 1 else 1
data[8][8] = 2 if data[8][8] == 1 else 1
for i in range(9):
print(''.join(map(str, data[i])))'알고리즘 대회' 카테고리의 다른 글
| 코드포스(Codeforces) 대회에서 소스코드 해킹(Hack) 방법 (0) | 2020.05.10 |
|---|---|
| [코드포스] Codeforces Round #637 (Div. 2) (0) | 2020.04.25 |
| [코드포스] Codeforces Round #636 (Div. 3) (0) | 2020.04.23 |
| 알고리즘 대회를 위한 C++ 대회 환경 구성하기 (1) | 2018.11.27 |
| 코드포스(Codeforces) 개요 및 문제 풀어보기 (0) | 2018.11.27 |
[코드포스] Codeforces Round #636 (Div. 3)
대회 링크: http://codeforces.com/contest/1343
A번 문제: http://codeforces.com/contest/1343/problem/A
정수 n이 주어졌을 때, 정수 k가 1보다 큰 조건 하에서 다음을 만족시키는 양수 x가 하나라도 있는지 찾는 문제다.

[ 문제 해설 ]
이 문제는 완전 탐색(Brute Forcing)으로 해결할 수 있다. k를 2부터 쭉 증가시켜보자. n은 다음과 같이 표현된다.
3x = n
7x = n
15x = n
31x = n
63x = n
...
보면 x의 계수가 기하급수적으로 증가한다. 이 때 n은 최대 1,000,000,000이기 때문에, 모든 경우의 수를 고려해도 빠르게 문제를 풀 수 있다. (대략 k가 30만 되어도 계수는 10억에 근접할 것이다.)
그래서 3x, 7x, 15x, 31x, 63x, ... 이렇게 증가 시키면서, n이 각 계수로 나누어 떨어지는지 확인한다. 만약 나누어 떨어진다면 그 때의 x를 출력하면 정답이다.
[ 정답 코드 ]
for _ in range(int(input())):
n = int(input())
coefficient = 2
now = 3 # now는 3, 7, 15, 31, ...와 같이 증가한다.
while True:
# n이 now로 나누어 떨어진다면
if n % now == 0:
# 그 몫을 출력한다.
print(n // now)
break
coefficient *= 2
now += coefficient
B번 문제: http://codeforces.com/contest/1343/problem/B
배열의 크기 n이 주어졌을 때, 이 배열의 앞 부분 절반은 짝수 원소로만 구성되고, 뒷 부분 절반은 홀수 원소로만 구성된다고 한다. 이 때 모든 원소들은 서로 다르다. 앞 부분의 합과 뒷 부분의 합이 동일하게 되는 리스트를 하나라도 찾으면 되는 문제다.
예를 들어 N = 4일 때, 2 4 1 5를 찾으면 정답이다. N = 8일 때는 2 4 6 8 1 3 5 11를 찾으면 정답이다.
[ 문제 해설 ]
이 문제는 홀수 합의 특징을 생각하면 어렵지 않게 풀 수 있다. 홀수를 홀수 번 더하면 홀수이다. 즉, N / 2가 홀수라면 리스트를 만들 수 없다. 예를 들어 N = 6 이라면, 리스트를 만들 수 없다. 즉 N이 4의 배수일 때만 리스트를 만들 수 있다. 그렇다면 N이 4의 배수일 때는 리스트를 어떻게 만들면 될까?
앞 부분 절반은 그냥 2부터 하나씩 나열한다. 뒷 부분 절반은 앞 부분에서 1씩 더하거나 빼서 만들 수 있다. (정확히는 뒷 부분 절반의 합이 앞 부분 절반의 합이 되어야 하므로, 뒷 부분 절반을 또 절반으로 나누어서 처리하면 된다.)
[ 정답 코드 ]
for _ in range(int(input())):
n = int(input())
# N이 4의 배수일 때 리스트를 만들 수 있다.
if n % 4 != 0:
print("NO")
else:
print("YES")
front = []
# 앞 부분 절반(짝수 부분)은 2부터 하나씩 출력
for i in range(1, n // 2 + 1):
print(i * 2, end=' ')
front.append(i * 2)
# 뒷 부분 절반(홀수 부분)의 절반은 -1씩 해서 출력
for i in range(n // 4):
print(front[i] - 1, end=' ')
# 뒷 부분 절반(홀수 부분)의 남은 절반은 +1씩 해서 출력
for i in range(n // 4, n // 2):
print(front[i] + 1, end=' ')
print()
C번 문제: http://codeforces.com/contest/1343/problem/C
리스트가 주어졌을 때, 리스트의 원소를 앞에서부터 하나씩 확인하며 원소를 고른다. 단, 양수와 음수를 번갈아 가면서 원소를 하나씩 골라야 한다. 처음에 양수를 골랐으면, 다음 번에는 음수를 골라야 한다. 반대로 처음에 음수를 골랐으면, 다음 번에는 양수를 골라야 한다.
이 때, 원소들을 골라서 만들어지는 가장 긴 부분수열 중에서 원소의 합이 가장 큰 것을 찾는 것이 요구사항이다.
예를 들어 수열이 [-2, 8, 3, 8, -4, -15, 5, -2, -3, 1]이라면, 정답 부분수열은 [-2, 8, -4, 5, -2, 1]이 된다. 이 부분 수열의 합은 6이다.
[ 문제 해설 ]
이 문제는 같은 부호를 가지는 데이터들을 묶어서 해결할 수 있다. 예를 들어 [-2, 8, 3, 8, -4, -15, 5, -2, -3, 1]라는 수열이 있다면, 이를 다음과 같이 인접한 원소끼리 묶도록 한다.
[-2, 8, 3, 8, -4, -15, 5, -2, -3, 1]
이 때, 같은 묶음 중에서 가장 큰 수를 각각 뽑으면 된다. 이 때 합은 6이 된다.
[-2, 8, -4, 5, -2, 1]
이를 코드로 옮기면 정답이다.
[ 정답 코드 ]
for _ in range(int(input())):
n = int(input())
data = list(map(int, input().split()))
result = 0
# 시작점이 양수인지 음수인지 기록(양수: 1, 음수: -1)
if data[0] > 0:
sign = 1
else:
sign = -1
# 같은 부호들을 담을 리스트
array = []
# 리스트의 원소를 하나씩 확인하며
for x in data:
# 현재 양수일 때 양수가 나온 경우
if sign == 1 and x > 0:
# 같은 부호이므로 담기
array.append(x)
# 현재 양수일 때 음수가 나온 경우
if sign == 1 and x < 0:
# 현재 부호를 음수로 변환
sign = -1
result += max(array)
array = [x]
# 현재 음수일 때 음수가 나온 경우
if sign == -1 and x < 0:
# 같은 부호이므로 담기
array.append(x)
# 현재 음수일 때 양수가 나온 경우
if sign == -1 and x > 0:
# 현재 부호를 양수로 변환
sign = 1
result += max(array)
array = [x]
result += max(array)
print(result)
D번 문제: http://codeforces.com/contest/1343/problem/D
길이가 n인 수열이 주어진다. (n은 짝수) 이 수열의 모든 원소는 k 이하의 값을 가진다.
이 때 대칭되는 원소들의 합을 모두 x로 만들고자 한다. 이를 위해 원소를 하나씩 골라서 그 원소의 값을 k 이하의 수로 바꾸는 연산을 수행할 수 있다. 결과적으로 최소 연산의 횟수를 출력하면 되는 문제이다.
예를 들어 [1, 2, 1, 2]의 경우 대칭되는 원소의 합이 각각 3, 3이다. 따라서 x = 3으로 설정했을 때, 연산이 필요하지 않다. 따라서 최소 연산 횟수는 0이다.
또한 [1, 2, 2, 1]의 경우 대칭되는 원소의 합이 각각 4, 2이다. 따라서 x = 4으로 설정했을 때, 첫 번째 원소를 3으로 변경하면 된다. 최소 연산 횟수는 1이다.
또한 [6, 1, 1, 7, 6, 3, 4, 6]의 경우 대칭되는 원소의 합이 각각 13, 4, 5, 12이다. 따라서 x = 8로 설정했을 때, 최소 연산 횟수로 4가 나올 수 있다.
[ 문제 해설 ]
이 문제는 아이디어만 잘 떠올리면 쉽게 해결할 수 있는 문제다. 일단 각 대칭 쌍마다 하나의 원소를 변경할 수 있다고 가정해보자. 예를 들어 3번째 예제를 가지고 생각해보자.
[6, 1, 1, 7, 6, 3, 4, 6]를 확인하면, 각 대칭 쌍을 정렬하여 나열하면 다음과 같다. 총 네 개의 쌍이 존재한다.
(1, 3): 합 = 4
(1, 4): 합 = 5
(6, 6): 합 = 12
(6, 7): 합 = 13
이 때 각 대칭 쌍의 원소 중 하나의 값을 변경할 수 있을 때의 범위는 다음과 같다.
(1, 3) → [2, 10]
(1, 4) → [2, 11]
(6, 6) → [7, 13]
(6, 7) → [7, 14]
결과적으로 모든 쌍들의 [lower_bound, upper_bound] 범위를 고려해보자. x를 2부터 2 * n까지 증가시키면서 확인한다고 생각해보자. x = 2라고 하면 (1, 3)과 (1, 4)의 범위에 포함되어 있으므로, 이들은 원소를 1개씩만 바꾸면 된다. 나머지 두 쌍은 원소를 2개 모두 바꾸어야 한다. 즉, x = 2일 때 최소 연산 횟수는 6이 될 것이다. 만약에 x = 7이라면 어떨까? 모든 대칭 쌍이 원소를 1개씩만 바꾸면 된다. 이 때 최소 연산 횟수는 4가 된다. 따라서 x를 증가 시키면서 매 x에 대하여 lower_bound와 upper_bound를 고려해주면 된다.
사실 [2, 2 * n] 범위에 대해서 x를 모두 고려할 필요는 없다. 각 대칭 쌍에 대하여 ① 대칭 쌍의 합, ② lower_bound, ③ upper_bound 세 가지에 대해서만 고려하면 된다. 이들을 포인트(points)라고 하겠다. 포인트는 오름차순 정렬이 되어 있어야 한다.
결과적으로 포인트를 하나씩 확인할 것이다. 이를 위해 lower_bound의 개수를 in_map에 기록하고, upper_bound의 개수를 out_map에 기록한다. 또한 대칭 쌍의 합은 sum_map에 기록하도록 하자. 이제 최소 연산 횟수를 구할 수 있다.
| points | 2 | 4 | 5 | 7 | 10 | 11 | 12 | 13 | 14 |
| in_map | 2 | 2 | |||||||
| out_map | 1 | 1 | 1 | 1 | |||||
| sum_map | 1 | 1 | 1 | 1 | |||||
| 연산 횟수 | 6 | 5 | 5 | 4 | 4 | 5 | 5 | 5 | 7 |
결과적으로 최소 연산 횟수는 4가 되는 것이다.
[ 정답 코드 ]
for _ in range(int(input())):
n, k = map(int, input().split())
data = list(map(int, input().split()))
# 3개의 해시 맵(Hash Map)을 사용합니다.
in_map = {}
out_map = {}
sum_map = {}
# x의 값으로 확인해야 할 포인트들
points = set()
for i in range(n // 2):
min_value = min(data[i], data[n - i - 1])
max_value = max(data[i], data[n - i - 1])
# lower_bound, upper_bound, 대칭 쌍의 합 계산
lower_bound = min_value + 1
upper_bound = max_value + k
sum_value = min_value + max_value
# 모든 lower_bound를 in_map에 기록합니다.
if lower_bound in in_map:
in_map[lower_bound] += 1
else:
in_map[lower_bound] = 1
# 모든 upper_bound를 out_map에 기록합니다.
if upper_bound in out_map:
out_map[upper_bound] += 1
else:
out_map[upper_bound] = 1
# 모든 대칭 쌍의 합을 sum_map 기록합니다.
if sum_value in sum_map:
sum_map[sum_value] += 1
else:
sum_map[sum_value] = 1
points.add(lower_bound)
points.add(upper_bound)
points.add(sum_value)
points = sorted(points)
now_sum = 0
result = n
for i in points:
# lower_bound의 개수만큼 더하기
in_count = 0
if i in in_map:
in_count = in_map[i]
now_sum += in_count
# sum의 개수 구하기
sum_count = 0
if i in sum_map:
sum_count = sum_map[i]
# 최소 연산 횟수 계산
now_total = n - (now_sum + sum_count)
result = min(result, now_total)
# upper_bound의 개수만큼 빼기
out_count = 0
if i in out_map:
out_count = out_map[i]
now_sum -= out_count
print(result)'알고리즘 대회' 카테고리의 다른 글
| [코드포스] Codeforces Round #637 (Div. 2) (0) | 2020.04.25 |
|---|---|
| [코드포스] Codeforces Round #634 (Div. 3) (0) | 2020.04.23 |
| 알고리즘 대회를 위한 C++ 대회 환경 구성하기 (1) | 2018.11.27 |
| 코드포스(Codeforces) 개요 및 문제 풀어보기 (0) | 2018.11.27 |
| 코드 포스(Code Force) 1055 - C. Lucky Days (0) | 2018.11.12 |
윈도우(Windows)에서 make 명령 사용하기
윈도우(Windows) 환경에서 GNU Make를 설치하여 이용하는 방법은 매우 간단합니다.
▶ 설치 경로: http://gnuwin32.sourceforge.net/packages/make.htm
다음과 같이 소스코드 없이 바로 설치할 수 있는 설치 파일을 받기 위해 [Setup] 링크를 누릅니다.

바로 설치 프로그램을 실행하여 설치를 진행할 수 있습니다. 기본 설정 그대로 [Next] 버튼만 누르셔도 정상적으로 설치됩니다.



설치가 완료된 이후에는 C 드라이브 내 GnuWin32가 설치된 폴더를 찾아주세요. 여기에서 bin 폴더의 위치를 환경 변수로 등록해주셔야, make.exe 파일을 사용할 수 있게 됩니다.

다음과 같이 시스템 변수 중에서 'Path'에 넣어 주시면 됩니다.

이후에 다음과 같이 명령 프롬프트(CMD)에서 make -v 명령을 입력했을 때, 버전 정보가 출력이 되면 정상적으로 설치가 완료된 겁니다.

'기타' 카테고리의 다른 글
| 크롬(Chrome) 브라우저가 느리게 동작하거나 인터넷 접속이 안 될 때 해결 방법 모음 (ERR_TIMED_OUT) (3) | 2020.05.05 |
|---|---|
| 경기도 재난 지원금 (재난기본소득) 온라인 신청 방법 (0) | 2020.04.24 |
| 리눅스(Linux)에서 윈도우(Windows)용 실행 파일을 컴파일하는 방법 (크로스 컴파일) (0) | 2020.04.20 |
| Oracle VM VirtualBox의 게스트(Guest) OS에서 USB 사용하기 (0) | 2020.04.20 |
| Oracle VM VirtualBox에서 호스트(Host)와 게스트(Guest) 공유 폴더 설정하기 (0) | 2020.04.20 |
리눅스(Linux)에서 윈도우(Windows)용 실행 파일을 컴파일하는 방법 (크로스 컴파일)
우분투(Ubuntu)에서 윈도우(Windows)에서 실행이 가능한 실행 파일을 만들기 위해서는 mingw를 설치할 필요가 있다. 사실 윈도우(Windws)에서 MinGW를 설치해서 직접 컴파일할 수도 있는데, 그것보다는 그냥 리눅스(Linux)에서 윈도우용 실행 파일을 크로스 컴파일하는 것이 편한 경우가 많다. 이를 위해 리눅스에 mingw를 설치하자.
sudo apt-get install mingw-w64
sudo apt-get install gcc-mingw-w64
이러한 mingw의 컴파일러는 다음과 같다. Makefile을 작업할 때는 컴파일러(Compiler)를 다음과 같이 정의해주어야 한다.
COMPILER = i686-w64-mingw32-gcc
또한 우분투(Ubuntu) 환경에서 mingw를 설치한 경우, 윈도우(Windows)에서 mingw를 설치한 것과는 다르게 라이브러리를 불러오는 경우가 있다. 예를 들어 헤더 파일로 라이브러리를 불러올 때 ddk/hidclass.h에서 불러오지 않고, hidclass.h의 위치에서 바로 불러온다. 물론 이는 컴파일 과정에서 오류가 발생하면 하나씩 바꾸면서 작업해 줄 수 있다.
'기타' 카테고리의 다른 글
| 경기도 재난 지원금 (재난기본소득) 온라인 신청 방법 (0) | 2020.04.24 |
|---|---|
| 윈도우(Windows)에서 make 명령 사용하기 (0) | 2020.04.20 |
| Oracle VM VirtualBox의 게스트(Guest) OS에서 USB 사용하기 (0) | 2020.04.20 |
| Oracle VM VirtualBox에서 호스트(Host)와 게스트(Guest) 공유 폴더 설정하기 (0) | 2020.04.20 |
| 우분투(Ubuntu)에서 usb.h 파일을 찾을 수 없을 때 (0) | 2020.04.20 |
Oracle VM VirtualBox의 게스트(Guest) OS에서 USB 사용하기
Oracle VM VirtualBox를 이용할 때, 게스트(Guest) OS 쪽에서 USB를 사용해야 할 일이 있다. 예를 들어 공인인증서를 게스트 OS에서 사용해야 하는 경우, 혹은 USB Device 관련 개발을 진행할 때가 이에 해당한다. 이 과정은 매우 간단하다. [장치] - [USB]에 들어가서 호스트(Host) OS에서 인식하고 있는 USB 중 하나를 선택해주면 된다.

이후에 다음과 같이 게스트 OS 쪽에서 정상적으로 USB를 인식하는 것을 확인할 수 있다.

참고로 리눅스 OS에서는 알 수 없는 장치(Unknown Devices)에 접근하려면 루트(Root) 권한이 필요하다. 따라서 알려지지 않은 HID USB 기기에 접근하는 코드를 실행하려는 경우에는 루트 권한으로 실행해야 한다.
'기타' 카테고리의 다른 글
| 윈도우(Windows)에서 make 명령 사용하기 (0) | 2020.04.20 |
|---|---|
| 리눅스(Linux)에서 윈도우(Windows)용 실행 파일을 컴파일하는 방법 (크로스 컴파일) (0) | 2020.04.20 |
| Oracle VM VirtualBox에서 호스트(Host)와 게스트(Guest) 공유 폴더 설정하기 (0) | 2020.04.20 |
| 우분투(Ubuntu)에서 usb.h 파일을 찾을 수 없을 때 (0) | 2020.04.20 |
| Teensy 3.6 SD Card 다루기 예제 (0) | 2020.04.20 |
Oracle VM VirtualBox에서 호스트(Host)와 게스트(Guest) 공유 폴더 설정하기
가상 머신(Virtual Machine) 기능을 이용하기 위해 많이 사용하는 소프트웨어 중 하나가 Oracle VM Virtual Box입니다. 이 때 호스트(Host) OS와 게스트(Guest) OS 간에 파일을 주고 받기 위해서 [공유 폴더]를 설정할 수 있습니다. [장치] - [공유 폴더] - [공유 폴더 설정]에 들어가서 공유 폴더를 설정할 수 있습니다.
(본 게시글은 호스트(Host)가 윈도우(Windows) 10이고, 게스트(Guest)가 Ubuntu 16.04인 상황에서 작성된 글입니다.)

[공유 폴더] 설정을 할 때, 처음에는 다음과 같이 내용이 비어있을 겁니다. 오른쪽 위의 [+] 버튼을 눌러서 추가를 진행하시면 됩니다.

이 때 호스트(Host) OS에서 공유 폴더 전용으로 하나의 폴더를 생성해 주시고, 이를 [폴더 경로]에 넣어줍시다. 이렇게 해서 [확인] 버튼을 눌러 만들어 주겠습니다.

이후에 게스트(Guest) OS인 Ubuntu 16.04에서 다음과 같이 해줍니다.
▶ sudo mkdir /mnt/share: 게스트(Guest) 입장에서 사용할 공유 폴더 경로
▶ sudo mount -t vboxsf (공유 폴더 이름) /mnt/share: 마운트 진행하기
명령을 수행한 뒤에는 두 OS가 성공적으로 폴더를 공유하고 있는 것을 확인할 수 있습니다.

※ 참고 사항 ※
가상 머신의 전원을 껐다가 다시 키면 마운트가 해제될 수 있습니다. 그런 경우에는 다시 마운트를 수행해 주시면 됩니다. 참고로 해당 폴더에 들어가 있는 상태에서 마운트를 하면 즉시 반영이 안 될 수 있으므로, 해당 폴더를 나왔다가 다시 들어가 보시면 공유 폴더 기능이 정상적으로 반영됩니다.

'기타' 카테고리의 다른 글
| 리눅스(Linux)에서 윈도우(Windows)용 실행 파일을 컴파일하는 방법 (크로스 컴파일) (0) | 2020.04.20 |
|---|---|
| Oracle VM VirtualBox의 게스트(Guest) OS에서 USB 사용하기 (0) | 2020.04.20 |
| 우분투(Ubuntu)에서 usb.h 파일을 찾을 수 없을 때 (0) | 2020.04.20 |
| Teensy 3.6 SD Card 다루기 예제 (0) | 2020.04.20 |
| Teensy를 활용해 Raw HID 소프트웨어 개발 시작하기 (0) | 2020.04.20 |
우분투(Ubuntu)에서 usb.h 파일을 찾을 수 없을 때
리눅스에서 usb.h 헤더 파일을 사용해야 할 때가 있다. 하지만 usb.h가 설치되어 있지 않을 때는 다음과 같은 오류 메시지를 확인하게 될 수 있다.
fatal error: usb.h: No such file or directory
이는 usb 개발용 라이브러리를 설치하면 해결된다.
sudo apt-get install libusb-dev
'기타' 카테고리의 다른 글
| Oracle VM VirtualBox의 게스트(Guest) OS에서 USB 사용하기 (0) | 2020.04.20 |
|---|---|
| Oracle VM VirtualBox에서 호스트(Host)와 게스트(Guest) 공유 폴더 설정하기 (0) | 2020.04.20 |
| Teensy 3.6 SD Card 다루기 예제 (0) | 2020.04.20 |
| Teensy를 활용해 Raw HID 소프트웨어 개발 시작하기 (0) | 2020.04.20 |
| Windows 10 운영체제에 VirtualBox 및 우분투(Ubuntu) 설치하기 (3) | 2020.04.06 |
Teensy 3.6 SD Card 다루기 예제
Teensy 3.6을 포함해 일부 Teensy Board들은 SD Card 슬롯(Slot)이 존재합니다. 따라서 Host PC와 데이터를 주고 받으면서, SD Card에 파일을 저장하는 등의 작업이 가능합니다. Teensyduino에서 기본적으로 제공되는 예시들을 확인할 수 있습니다.
일단 아래의 모든 예시들을 실행할 때는 chipSelect 변수의 값을 자신이 사용하고 있는 Teensy의 버전에 맞게 설정해야 합니다. 저는 Teensy 3.6 버전을 이용하고 있기 때문에, chipSelect 변수의 값을 BUILTIN_SDCARD로 설정했습니다.
※ SD 카드(Card) 정보 출력하기 ※
[예제] - [SD] - [CardInfo]를 들어가면 SD 카드의 정보를 출력하는 예제를 실행할 수 있습니다.

이 예제는 단순히 카드 정보를 출력하는 예시입니다. 대략 다음과 같이 내용이 출력됩니다. 다만 예제 소스코드를 확인해 보시면, Volume Size만을 출력해주는 것이 아니라 루트 폴더에서의 전체 폴더 및 파일 목록까지 함께 보여주는 것을 알 수 있습니다.

※ SD 카드(Card)의 파일 리스트 읽어오기 ※
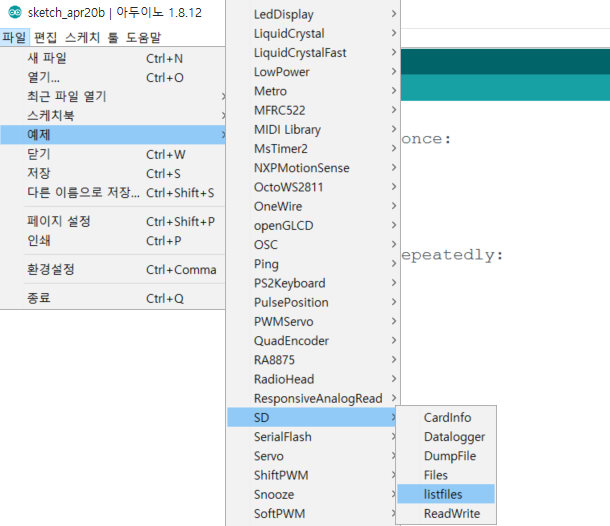
[예제] - [SD] - [listfiles]에 들어가면 카드에 포함된 파일 목록을 출력하는 예제를 실행할 수 있습니다. 이 내용은 위의 예제에서 출력되는 내용과 비슷해 보이지만, 실제 구현상에서는 File 객체를 이용하여 파일을 openNextFile() 함수를 이용해 파일에 하나씩 접근하여 정보를 출력한다는 점이 특징입니다.
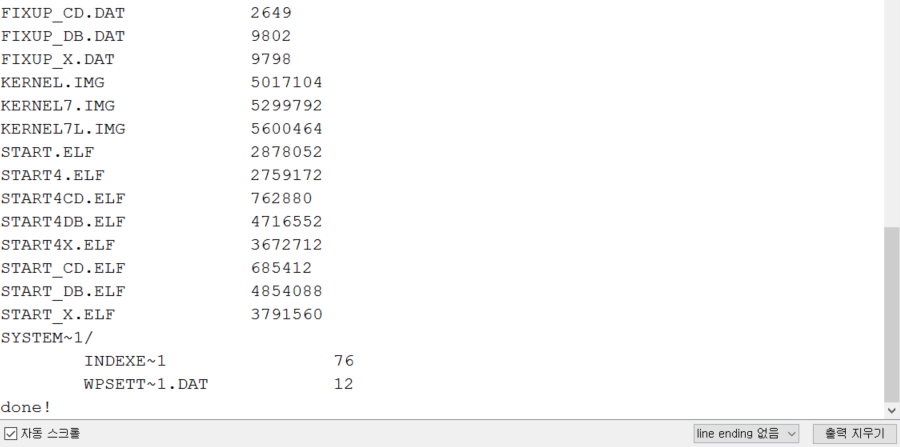
출력된 결과는 다음과 같습니다.
※ SD 카드(Card)에서 파일의 데이터를 읽고 데이터 쓰기 ※
[예제] - [SD] - [ReadWrite]에 들어가면 하나의 파일을 만들고 내용을 추가한 뒤에, 출력하는 예제를 실행할 수 있습니다. 소스코드를 확인해 보시면 SD Card 내부에서 "test.txt"라는 이름의 파일을 연 뒤에 여기에 특정한 문자열을 내용으로 기입하고, 이를 저장하는 것을 알 수 있습니다. 그리고 그렇게 저장된 내용을 다시 출력해보며 확인합니다.

※ Raw HID를 통해 받은 데이터를 SD 카드(Card)에 저장하기 ※
이제 Raw HID를 통해서 Host PC로부터 받은 데이터를 Guest Device의 SD Card에 작성하는 예시를 다루어 보겠습니다. Host PC 전용 프로그램은 아래 경로에서 다운로드 받아서 그대로 이용하실 수 있습니다.
▶ Teensy 공식 홈페이지: https://www.pjrc.com/teensy/rawhid.html
Guest Device인 Teensy 3.6의 소스코드는 다음과 같이 작성할 수 있습니다. 소스코드를 확인해 보시면, 먼저 SD Card 내부에 example.txt 파일을 생성하는 것을 알 수 있습니다. 이후에 Host PC로부터 한 문자씩 전달 받는 데이터를 example.txt에 쓰게 됩니다. 만약에 전달 받은 문자가 'q'라면 데이터를 전달 받는 것을 멈추고, example.txt 파일을 읽어서 입력되었던 문자들을 시리얼 통신을 통해 출력합니다.
#include <SD.h>
#include <SPI.h>
File myFile;
const int chipSelect = BUILTIN_SDCARD;
void setup() {
Serial.begin(9600);
while (!Serial) ;
Serial.println("RawHID Example");
// Initialize SD card.
Serial.print("Initializing SD card...");
if (!SD.begin(chipSelect)) {
Serial.println("initialization failed!");
return;
}
Serial.println("initialization done.");
// Remove and recreate example.txt file.
SD.remove("example.txt");
Serial.println("Creating example.txt...");
myFile = SD.open("example.txt", FILE_WRITE);
}
// RawHID packets are always 64 bytes.
byte buffer[64];
elapsedMillis msUntilNextSend;
unsigned int packetCount = 0;
void loop() {
int n;
n = RawHID.recv(buffer, 0);
if (n > 0) {
if (buffer[0] == 'q') {
if (myFile) {
Serial.println("Quit!");
myFile.close();
// If the file is available, print it's data.
Serial.println("File contents are:");
File dataFile = SD.open("example.txt");
if (dataFile) {
while (dataFile.available()) {
Serial.write(dataFile.read());
}
dataFile.close();
}
// If the file isn't open, pop up an error.
else {
Serial.println("error opening example.txt");
}
}
return;
} else {
if (myFile) {
Serial.print("Received packet, first char: ");
Serial.println((char)buffer[0]);
myFile.println((char)buffer[0]);
}
}
}
}
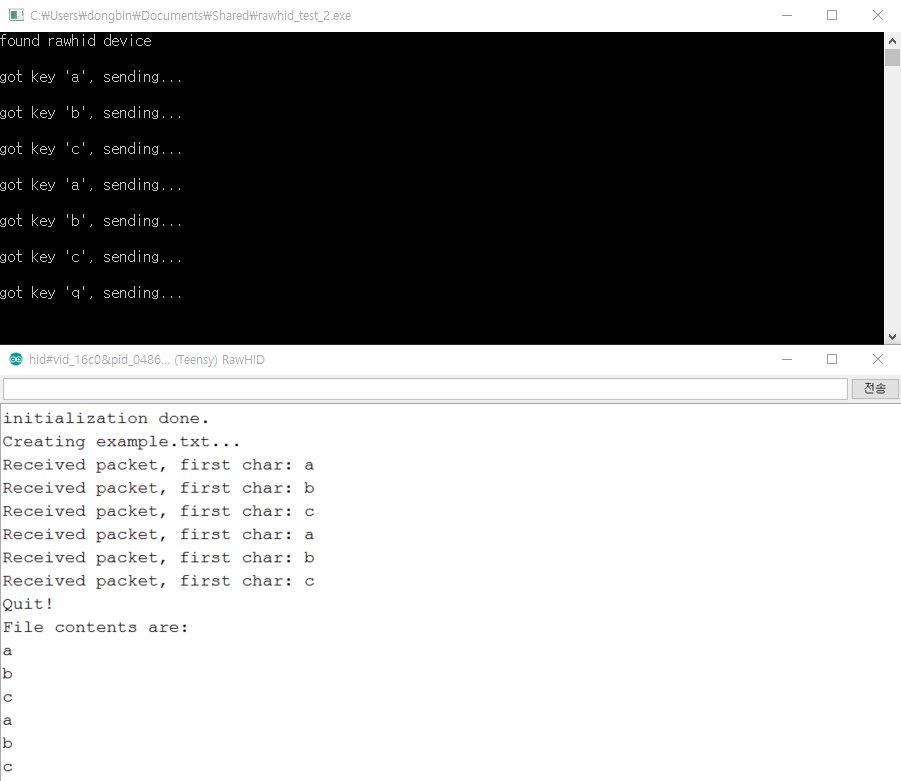
실행 결과는 다음과 같습니다.
※ 특정한 파일의 Byte Stream 읽어서 그대로 출력하기 ※
특정한 파일을 열어서 내부에 적힌 데이터를 읽어서 Byte Stream 형태 그대로 출력하는 예제는 다음과 같습니다. 이 코드는 제가 개인적으로 많이 쓰는 코드입니다.
#include <SD.h>
#include <SPI.h>
#define BUFFER_SIZE 64 // 버퍼 사이즈
File myFile;
byte buffer[BUFFER_SIZE];
const int chipSelect = BUILTIN_SDCARD;
void setup() {
Serial.begin(9600);
while (!Serial);
if (!SD.begin(chipSelect)) {
Serial.println("initialization failed!");
return;
}
delay(1000);
myFile = SD.open("example.dat", FILE_READ);
uint64_t fileSize = myFile.size();
if (myFile) {
while (true) {
// 전달 받을 데이터의 크기(버퍼 크기보다 덜 남은 경우 남은 크기만 저장)
int length = (fileSize < BUFFER_SIZE)? fileSize : BUFFER_SIZE;
// 전달 받은 내용 그냥 Serial 통신으로 출력
myFile.read(buffer, length);
fileSize -= length;
for (int i = 0; i < length; i++) {
Serial.print(buffer[i]);
Serial.print(" ");
if ((i + 1) % 8 == 0) Serial.println();
}
// 크기만큼 다 출력한 경우 파일 객체 닫기
if (fileSize <= 0) {
break;
}
}
myFile.close();
}
}
void loop() {
}
실행을 해보시면 다음과 같은 시리얼 출력 결과를 확인할 수 있습니다. (한 줄에 8바이트씩 출력합니다.)

'기타' 카테고리의 다른 글
| Oracle VM VirtualBox에서 호스트(Host)와 게스트(Guest) 공유 폴더 설정하기 (0) | 2020.04.20 |
|---|---|
| 우분투(Ubuntu)에서 usb.h 파일을 찾을 수 없을 때 (0) | 2020.04.20 |
| Teensy를 활용해 Raw HID 소프트웨어 개발 시작하기 (0) | 2020.04.20 |
| Windows 10 운영체제에 VirtualBox 및 우분투(Ubuntu) 설치하기 (3) | 2020.04.06 |
| 이전 버전의 Visual Studio를 설치하는 방법 (Visual Studio 2015) (0) | 2020.04.03 |
